In the first level of this series, I showed how to get started with Docker on Windows and running a database container. That was a basic look at containers, with no discussion on storage and persistence of state. In this article, I will start to examine storage in containers and how we can persist changes across time.
Storage in Containers
Containers maintain their own copy of the filesystem based on the host filesystem. This means that Windows containers see the Windows filesystem and Linux containers see the Linux filesystem. There is some magic to let Linux containers run on Windows, with the Linux subsystem, so this ensures the Linux containers still see a normal Linux file system when they start.
This filesystem appears to be completely normal to the container, but it's not quite the same filesystem that most of us are used to dealing with. I will give a short explanation of how this works and then demonstrate what this means in a practical sense.
The Unified Filesystem
This isn't meant to be a detailed look at how containers deal with files, but rather, an overview of the way storage works.
When a container starts, it uses the image named in the docker run command as the basis for it's structure. This is a read only file that is built of various layers. Some of these layers are views of the file system at various states. Docker containers use a unified file system driver that takes all of those layers and presents a unified view of the final state.
This means that if the first layer has a /var/opt folder, or c:\Program Files, in it, and the second layer adds the /mssql or \Microsoft SQL Server folders, the image will contain the full path, /var/opt/mssql or c:\Program Files\Microsoft SQL Server. If a layer updates or changes a files from a previous layer, those changes are shown in the final view of the file system.
When a container starts, the Docker engine adds a thin writable layer on top of the read-only view of the file system in the image. This writable layer allows the container to make changes to the file system. These changes exist for the lifetime of the container, which we will show next.
The Container File System In Action
A container is meant to be an ephemeral, short lived system. This means that the changes made to the container do not persist beyond the lifetime of the container. If the container is removed, changes are lost.
When a container starts, its view of the filesystem is what the image had when it was built. If changes are made, these are reflected in what that container sees. If a second container is started from the same image, it has the base file system from the image, and changes that were made in container 1 are not visible in container 2.
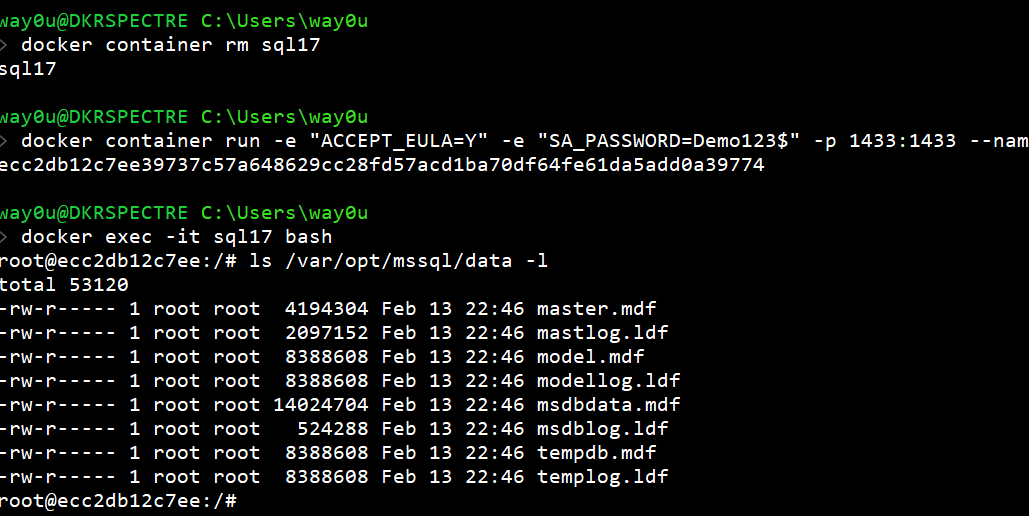
Let's see this in an example. I'll start a SQL Server container with the name SQL17.

I can then connect to this container with SSMS and create a database. This will create the database mdf/ldf files in /var/opt/mssql/data. Let's see this below:
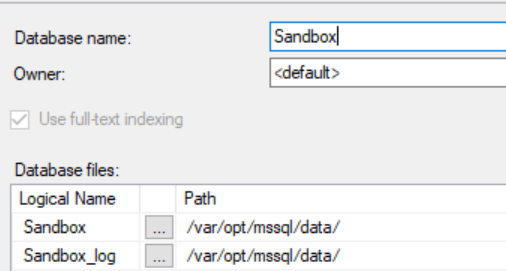
I use the docker exec command to connect to the container and run the bash shell to check the files. As we can see, there are database files here.
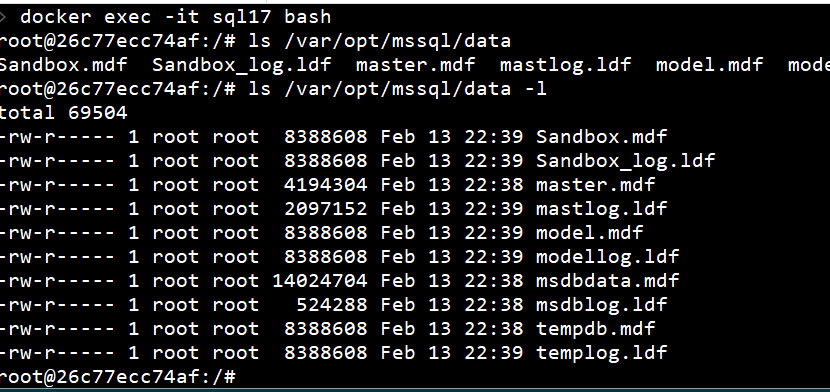
If I stop the container, the new files (sandbox.mdf and sandbox.ldf) still exist. I can start the container and see this is the case.
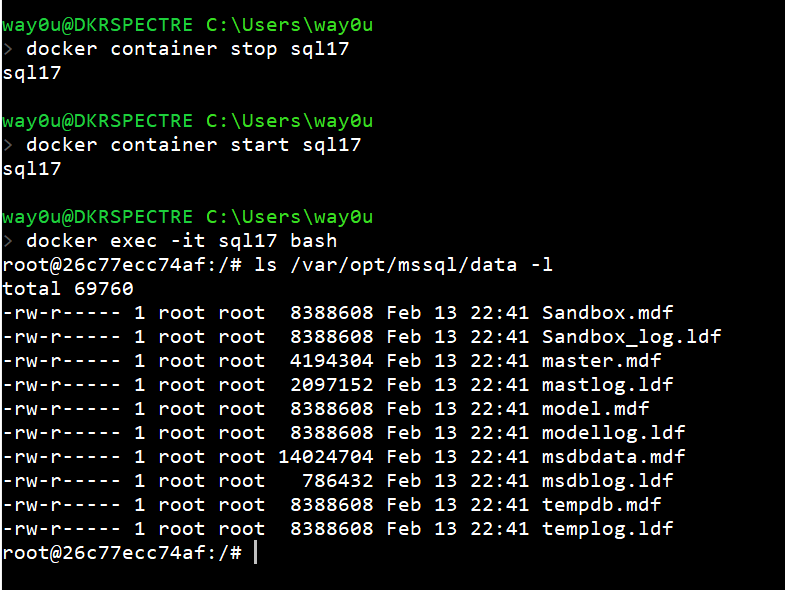
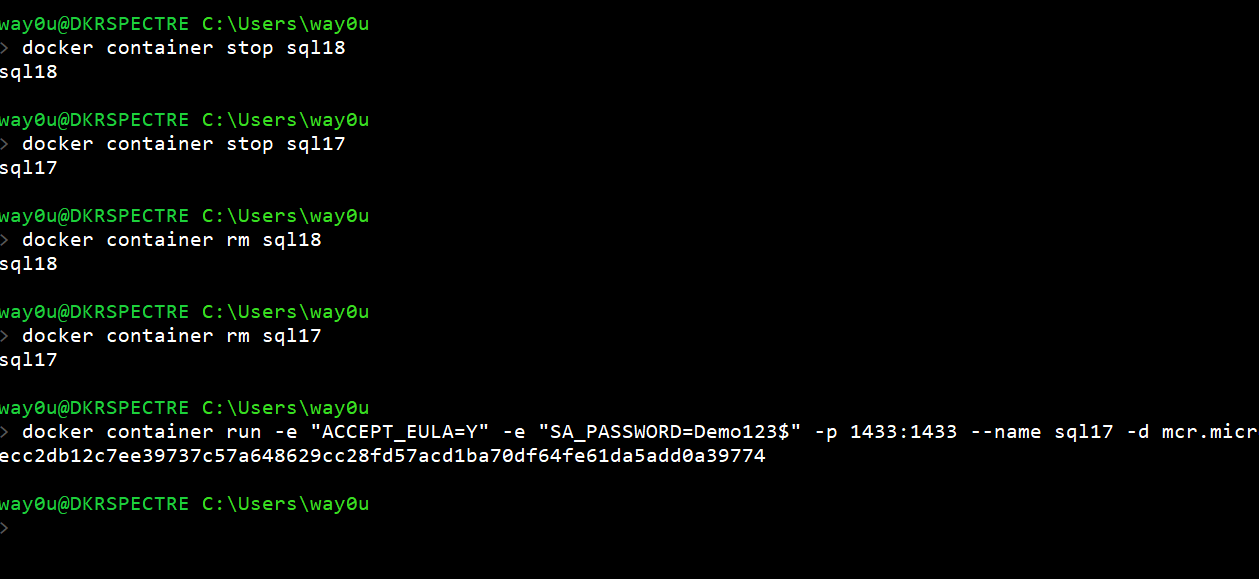
Let's now start a second container and call this SQL18. We won't create a database, but just connect to the container and check the filesystem.
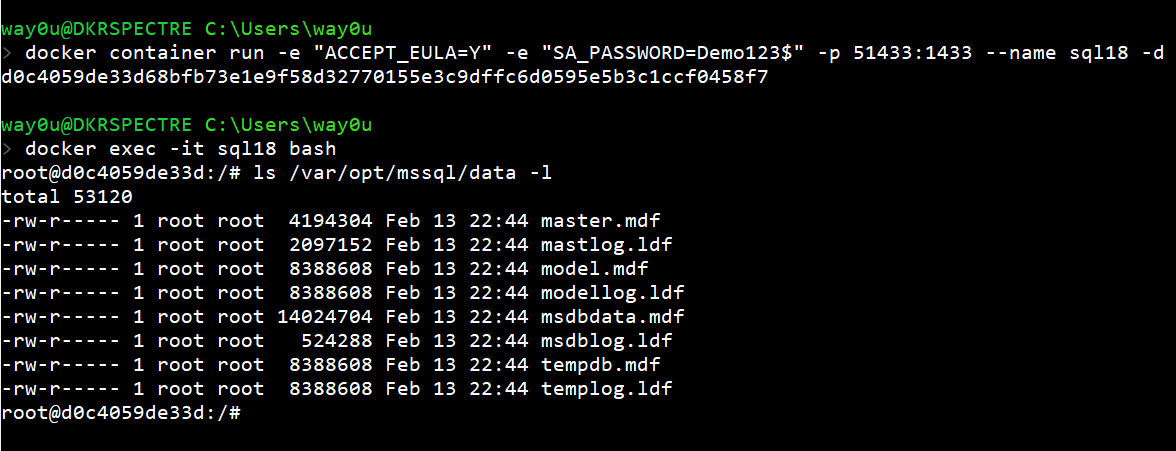
Note there are no sandbox database files here. This is because this container has been created with the base filesystem from the image.
Now I will stop and remove both containers. We will restart a new container called SQL17. When we check the filesystem (shown in these two screenshots), we see this is again the base filesystem with no sandbox database files. This is a new container, even though it has the same name as the first one we created. This is the power of containers, always having a known starting point and quickly reset to a known configuration.
There are ways to ensure we have a more complete SQL Server when we start a new container, but we will cover those in another article. For now, let's see how we can persist storage inside of a container.
Using Volumes
There are a few ways to keep storage around inside containers, but we will focus on volumes, which seem to be the way Windows works with Docker. On Linux there are mounts, but those don't seem to work in Windows at this time.
A volume is essentially a mapping from the host to a container. This mapping allows the container to read and write to a folder it sees in its unified file system, but the changes actually occur on a folder on the host computer. When the container is removed, the folder still exists and can be mapped to other containers.
We can actually map the same folder to multiple running containers, but that would be disaster for SQL Server database files. This is intended to show you how you can keep databases around and restart containers, potentially with different SQL Server patch levels. Let's see how to do this.
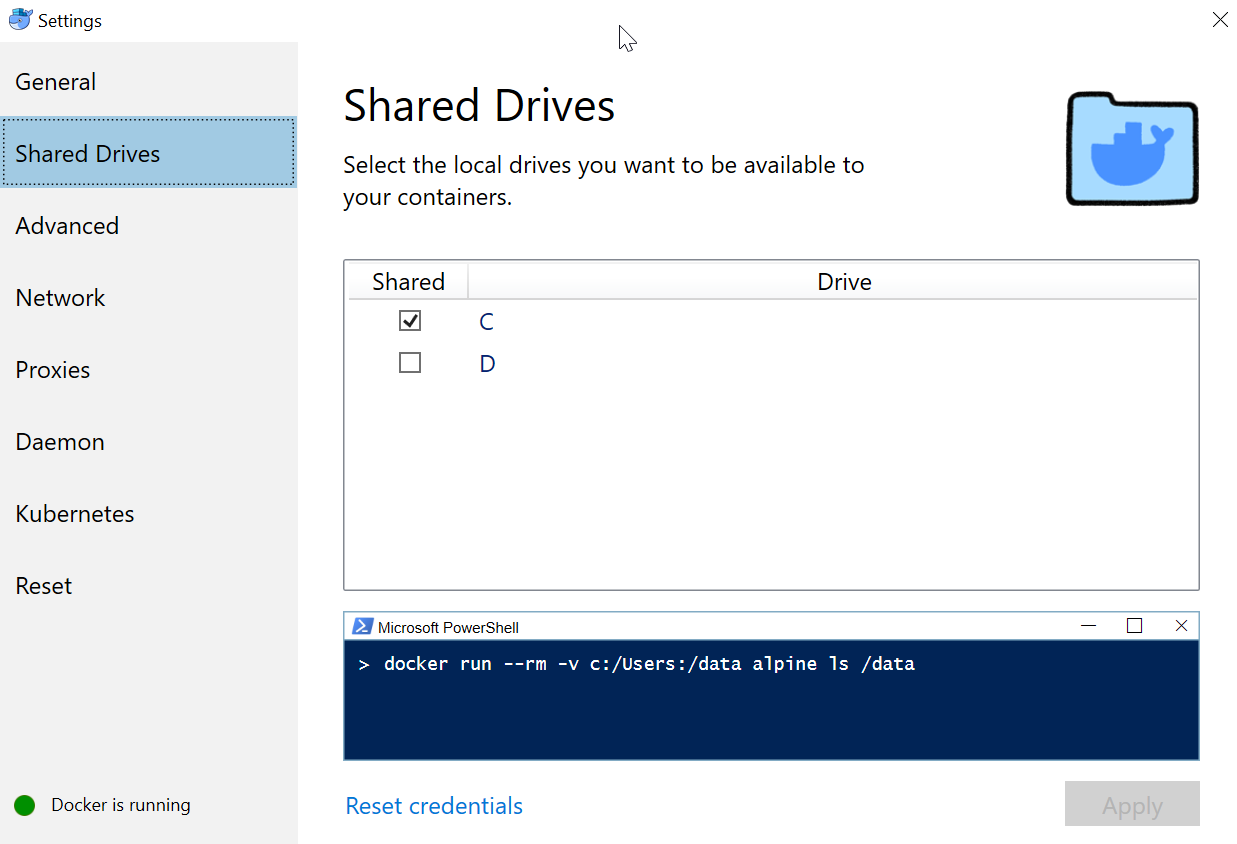
Configure Shared Drives
On Windows, we need to let Docker know which drives will be potentially shared. If you access the settings of your Docker runtime client, you will see a Shared Drives section. Check the drive(s) that you wish to share with containers.
Note, you are not sharing the entire drive, but any folder in the drive can be mapped to the container.
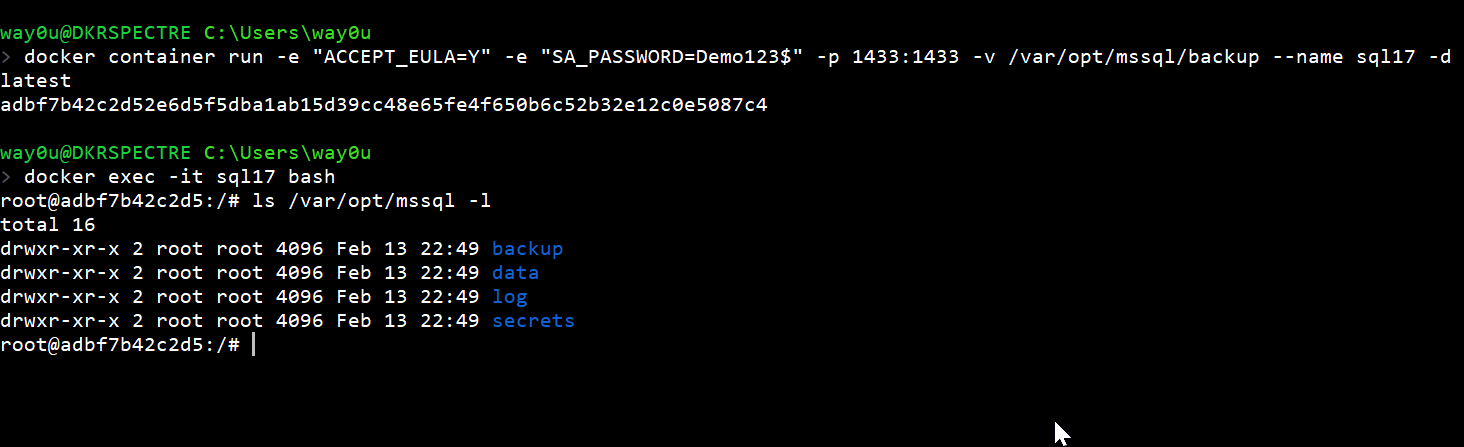
Mapping a Volume
The easiest way to add a volume is to do so when the container starts. We use the -v parameter and then (optionally) include the host path, a colon, and the path inside the container. We can do this as follows. In this case, I will mount a volume by just specifying the path inside the container. As we can see, a "backup" folder has been created.
If we backup a database inside the container, we can specify this new path.
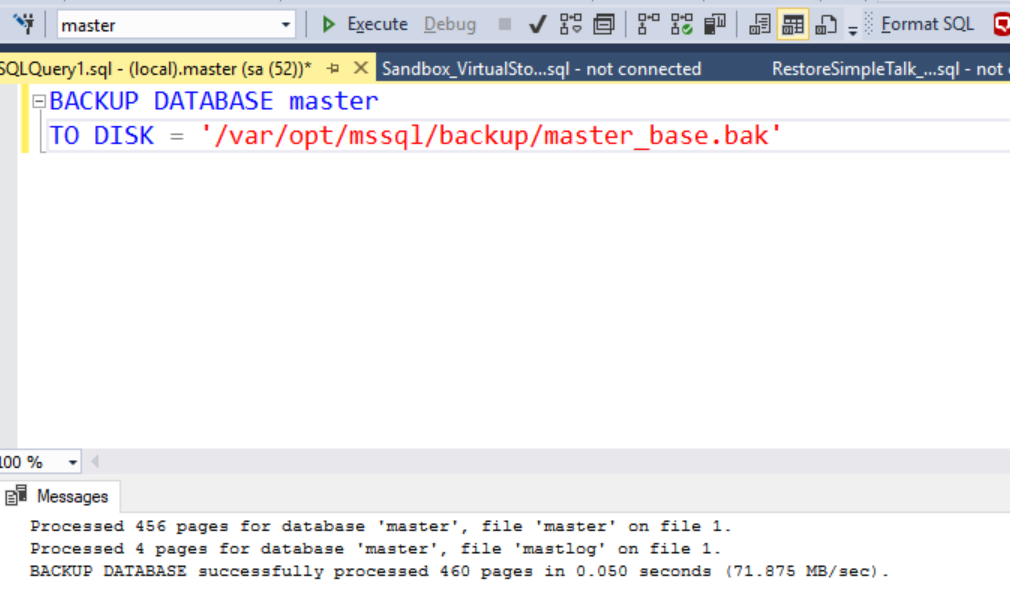
Now I'll look in the host folder before and after the backup. After, I can see the database files.
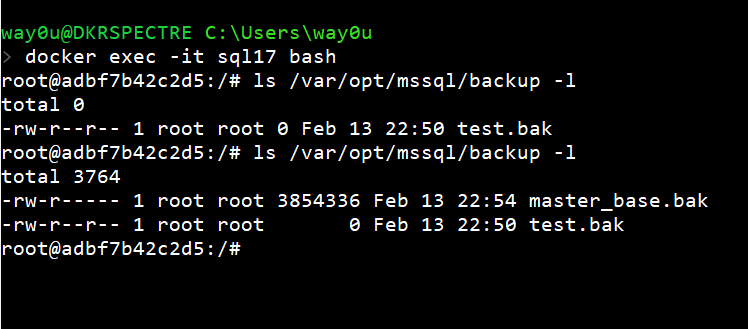
If we don't include the host path, Docker mounts the filesystem to a path that is not easy to track down. Include the host path is what you should take away from here. If I were to start a new container, it would have a new ID and have the path mapped to a different location.
Let's now stop and remove the container. This time, I'll start a new container with the a host folder mapping to a specific drive. First, I'll create the folder, and I'll copy in a couple files.
When I connect and look inside the container, I can see the same files exist.
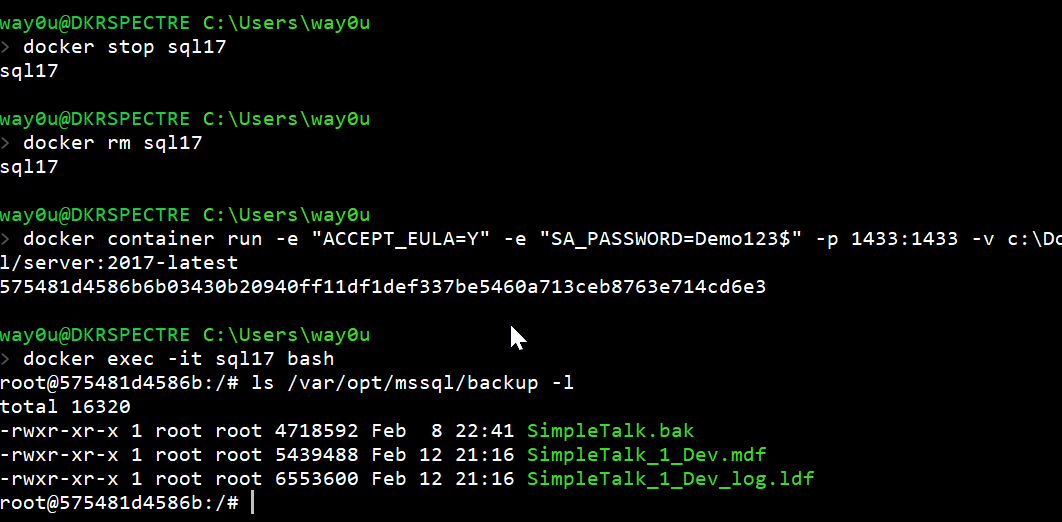
Now, let's restore a database from these files. I will do that with SSMS.
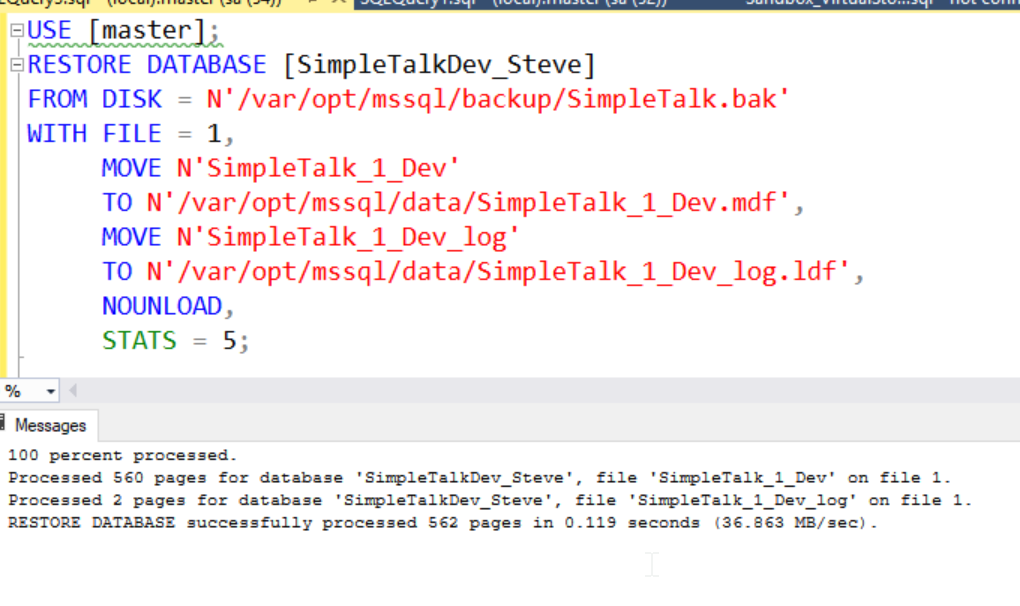
We can start a new container with the same mapping. When we connect to this container, we'll also see the same files. Note the name and port mappings are changed for this container.
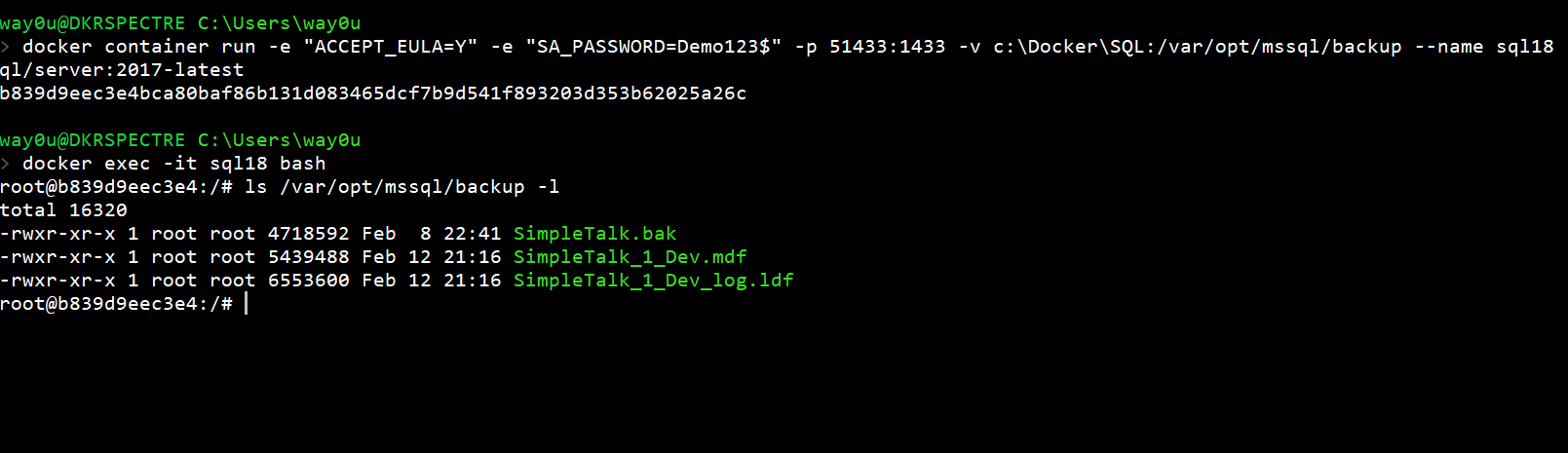
However, we don't see a database in SSMS. This is a separate instance, in a separate container.
Multiple Volumes
Let's approach this another way. Imagine that I want to have multiple volumes in a container, say one for backup files and one for data files. I can add multiple volumes with different -v commands. Here is what I can run with Docker.
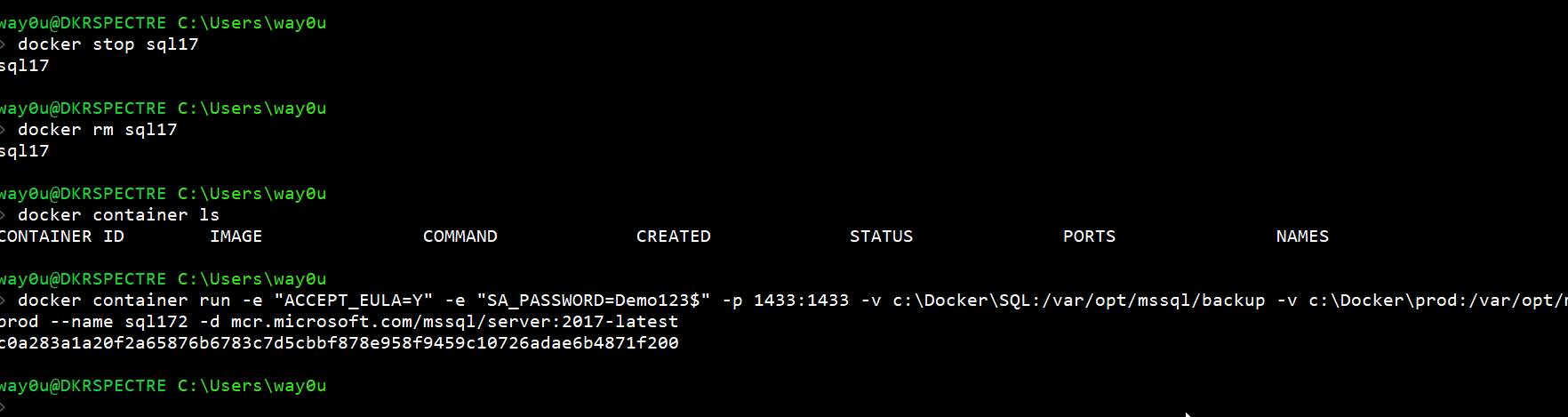
docker container run -e "ACCEPT_EULA=Y" -e "SA_PASSWORD=Demo123$" -p 1433:1433 -v c:\Docker\SQL:/var/opt/mssql/backup -v c:\Docker\prod:/var/opt/mssql/data/prod --name sql17 -d mcr.microsoft.com/mssql/server:2017-latest
I have already placed some database files in the /prod folder.
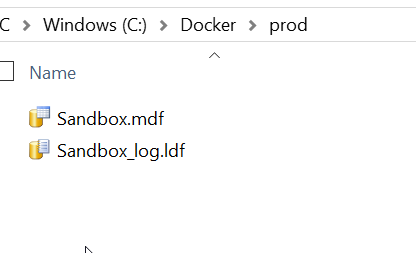
I can now attach these files to my container instance.
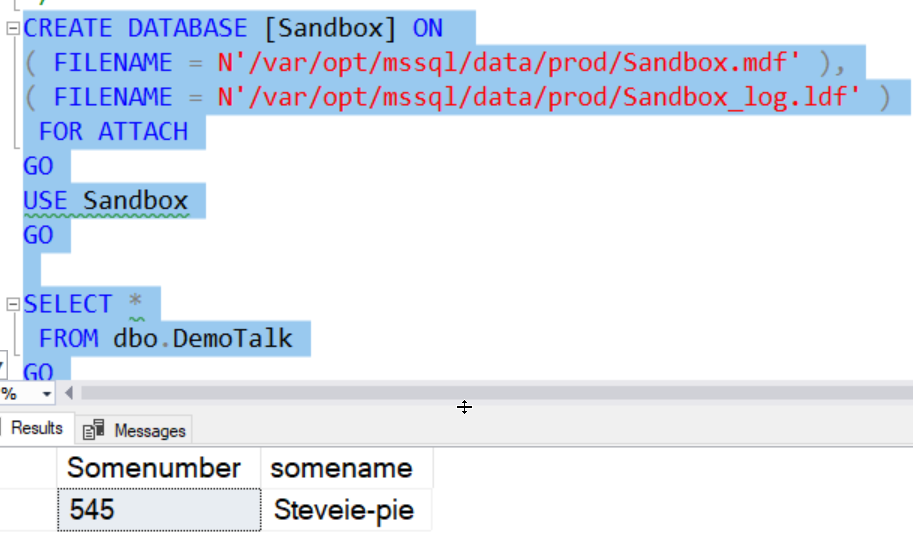
Let's now add a row to the database.
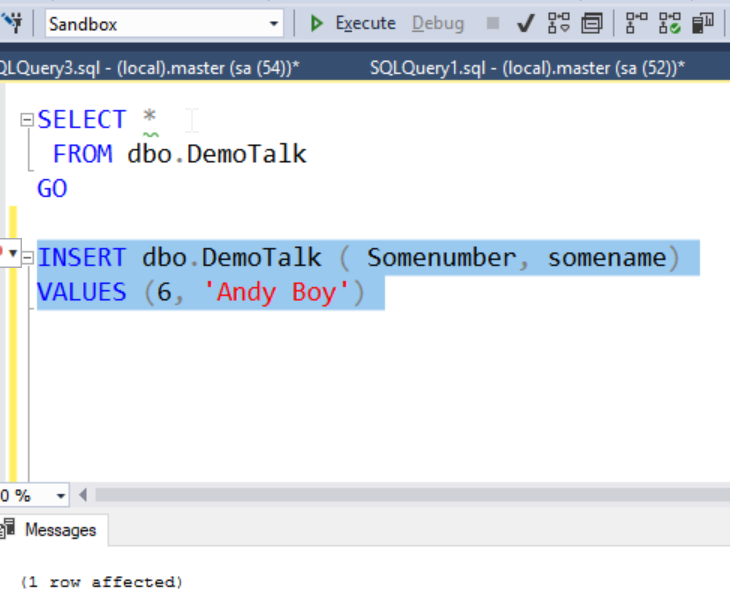
We can now stop and remove the container. This destroys all the ephemeral data in the container file system, except what's mapped on the host. We will restart a new container, called sql172, with the same mapping.
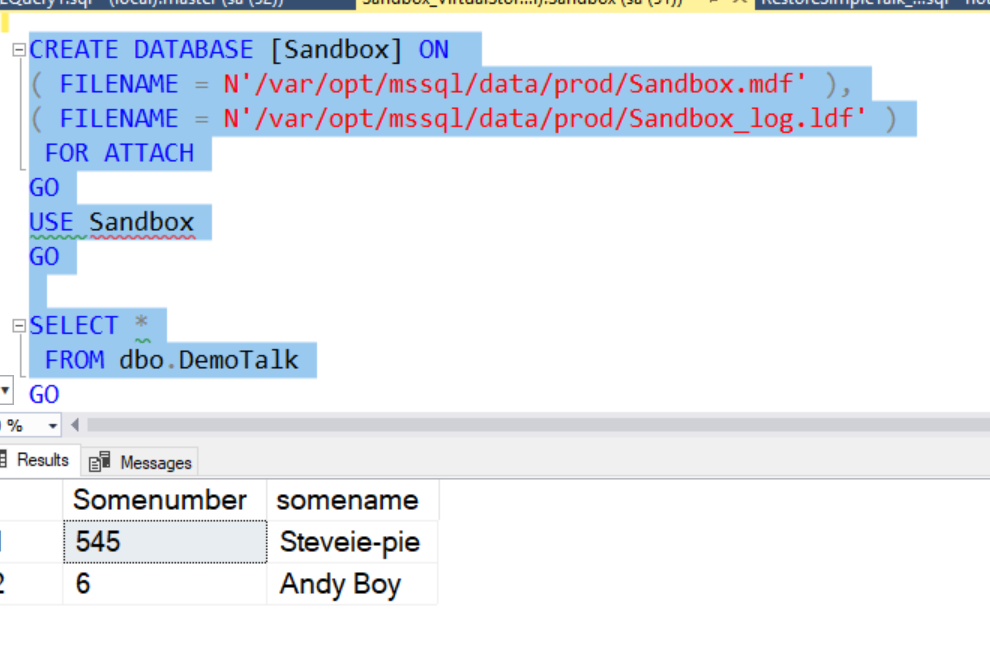
Now we'll run the attach and select script. Once we do that, we have the same data that the other container in this database.
Summary
Each container has a unified view of the read-only image filesystem and a thin writable layer created when the container starts. Each container sees a separate filesystem that only it can see. This filesystem functions as a normal file system for the lifetime of the container. It persists between pauses, stops, and restarts. When the container is removed, however, all changes in the writable layer are lost.
Volumes provide a way to persist data beyond the lifetime of a container. We can do this by mapping a folder on the host system to a folder inside the container. This volume is independent of the container, and can be mapped to multiple running containers. This is not recommended for SQL Server files.
Using volumes to persist a database is fine if we are changing containers, but we don't want to reattach or run other commands when the container starts. Instead, we would like to build our own images that contain the SQL Server instance in the state that we find useful. In the next level, we will look at customizing images.
