
In the previous level I discussed the difficulties of adding data to columnstore indexes, and the workarounds implemented in SQL Server 2014 to enable inserts into tables with columnstore indexes – even if the inserted data is not always immediately converted into column-oriented format.
But even in data warehouses, inserts are not the only modification that has to be supported. We must also be able to update and delete data. This level looks in detail at what happens when we update or delete data from a clustered columnstore index, the impact it has on concurrent data access, and how without careful maintenance the efficiency of columnstore indexes can degrade over time.
Challenges of modifying data in Columnstore indexes
Deleting or updating data in compressed column-oriented storage comes with a whole new set of challenges. Many compression algorithms replace a value with a shorter value that is derived from all preceding data. Changing or removing a single value at the start of a block of compressed data would mean that the compressed value for all successive values has to be recomputed. And even in a relatively simple compression method such as row-length encoding, a single update can result in having to rewrite many pages of data.
Cost of in-place update: example
One of the compression methods used for columnstore indexes, and one of the simpler compression methods to understand, is row-length encoding. This method relies heavily on sorting data efficiently before compressing it. If, for instance, the sorted data has 17 consecutive rows with the value Niko in the Name column, those 17 values would be replaced by a single {Value, Occurrences} pair: {Niko, 17} (which can be read as “repeat the value Niko 17 times).
If the 6th of those rows would be updated to Kalen , the most efficient choice would be to move it to the end of the block of 17. But because rows are tied together by the relative position of values in each segment that would necessitate moving values in the corresponding segments for other columns as well, so this is not possible. Hence, the only way to reflect this change in a row-length encoded column would be to replace the single pair {Niko, 17} with a sequence of three pairs: {Niko, 5} / {Kalen, 1} / {Niko, 11} . This obviously takes more space, so all the data following it now has to be moved down to make room for this expansion. If this happens at the start of a one-million row segment, you can imagine that a lot of pages will have to be updated for this one modification.
Deleting data
It is, in theory, possible to delete data directly from a columnstore index. But it’s not easy. The corresponding values need to be found in and deleted from each of the rowgroup’s segments. Depending on the compression type, this may require de- and recompressing parts or even all of the data in the segment. The end effect would be a DELETE statement that runs at a speed that most people would not find acceptable. It is for that reason that Microsoft has picked a different solution. To see how this works, let’s first run the code in listing 6-1. This code will delete one percent of the data, spread across all rowgroups.
USE ContosoRetailDW; GO -- Delete one percent of the rows, throughout all rowgroups DELETE FROM dbo.FactOnlineSales2 WHERE OnlineSalesKey % 100 = 33; -- Check the rowgroups metadata SELECT OBJECT_NAME(rg.object_id) AS TableName, i.name AS IndexName, i.type_desc AS IndexType, rg.partition_number, rg.row_group_id, rg.total_rows, rg.size_in_bytes, rg.deleted_rows, rg.[state], rg.state_description FROM sys.column_store_row_groups AS rg INNER JOIN sys.indexes AS i ON i.object_id = rg.object_id AND i.index_id = rg.index_id WHERE i.name = N'CCI_FactOnlineSales2' ORDER BY TableName, IndexName, rg.partition_number, rg.row_group_id;
Listing 6-1: Deleting data from a columnstore
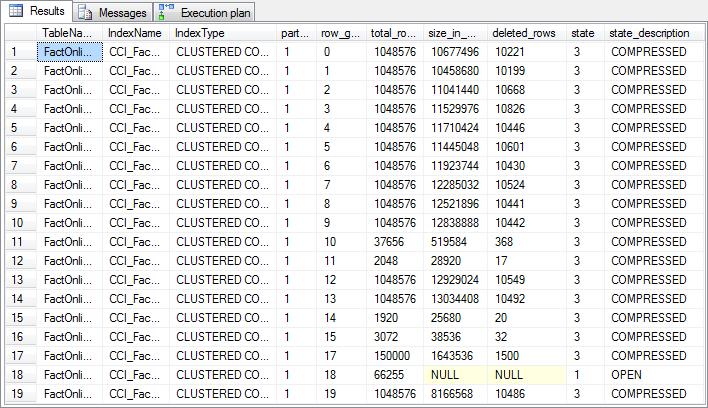
Figure 6-1: Metadata after deleting data
In comparison to the queries in the previous level, I added one additional column to the resultset of the DMV query: deleted_rows . This column is not used for deltastore rowgroups: as these are stored in traditional row-oriented format, it is easy enough for SQL Server to simply delete these rows. So that is what SQL Server will do, for all rows to be deleted from both open and closed deltastores. If you compare total_rows of rowgroup 18 to what it was before deleting data, you will see that 669 rows were deleted from this rowgroup.
But for rowgroups that are already in columnstore format (state 3, COMPRESSED ), a different method was used. These rows were not actually deleted from the columnstore blobs. Instead, SQL Server simply marks the row as deleted without removing any data. The data itself is still present in the index, but the “deleted” mark tells SQL Server to ignore this data and pretend it isn’t there. The data returned by the DMV query reflects this method of logically deleting the data without physically removing it – the total_rows of the rowgroups has not been changed, because all the rows are still there; the deleted_rows column tells us how many of these rows are no longer valid. If you have a clustered columnstore index that is frequently modified, you should monitor these numbers to decide when it is time to free up wasted space (and regain performance) by physically removing the deleted data – I’ll cover more about that in the next level of this series.
The bitmap that is not a bitmap
When rows in a columnstore index have to be marked as deleted, an extra storage structure is added to the index. This storage structure is often referred to as the “ Deleted Bitmap ”, but that is actually a misleading name. The delete marks are not stored as a bitmap, but in an internal, row-compressed B-tree, as a virtual two-column table storing only rowgroup number and row number of the row within that rowgroup.
Luckily, we do not have to concern us with these implementation details. I do want to point it out, because bitmaps tend to have a fixed size, whereas the actual storage of delete marks grows as more rows in the rowgroup are deleted.
Updating data
Logically speaking, updating data can be considered as equivalent to deleting the old version of the data and inserting the new data. In the case of SQL Server, this is exactly what happens when rows in a columnstore are updated. Not the rows that are still in a deltastore: these are still in a B-tree, so they can easily be processed by the regular update mechanism. But for the rows that are already compressed in columnstore rowgroups, every update is processed by marking the old row as deleted and trickle inserting the new data in a deltastore.
You can see this in action by running the code in listing 6-2. This code updates about 20% of the data in the table, well over two million rows. That takes time (12 minutes on my test system, a VM on my laptop), but I chose this high number because I wanted to demonstrate that, even for extremely large updates, the new rows are always added as trickle inserts, not using the bulk load mechanism that loads the data directly in column-oriented format.
USE ContosoRetailDW; GO -- Update twenty percent of the rows, throughout all rowgroups UPDATE dbo.FactOnlineSales2 SET UpdateDate = CURRENT_TIMESTAMP WHERE OnlineSalesKey % 5 = 2; -- Check the rowgroups metadata SELECT OBJECT_NAME(rg.object_id) AS TableName, i.name AS IndexName, i.type_desc AS IndexType, rg.partition_number, rg.row_group_id, rg.total_rows, rg.size_in_bytes, rg.deleted_rows, rg.[state], rg.state_description FROM sys.column_store_row_groups AS rg INNER JOIN sys.indexes AS i ON i.object_id = rg.object_id AND i.index_id = rg.index_id WHERE i.name = N'CCI_FactOnlineSales2' ORDER BY TableName, IndexName, rg.partition_number, rg.row_group_id;
Listing 6-2: Updating data in a columnstore
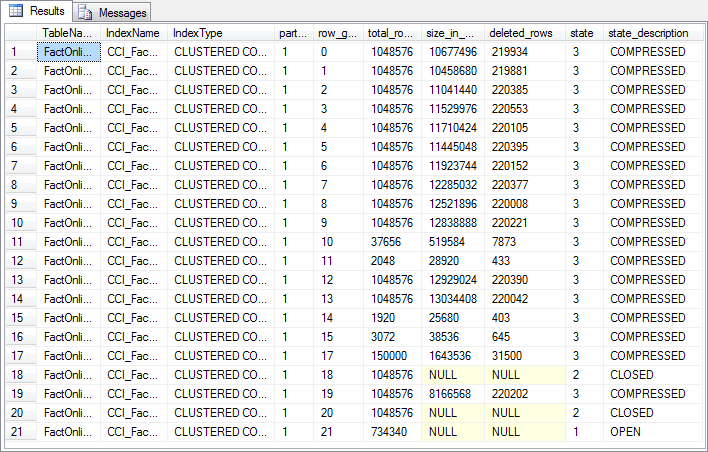
Figure 6-2: Metadata after updating data
If you look at the result after running the code in listing 6-2, you will see that there are now many rows marked as deleted in the compressed rowgroups. You also see two closed and one open rowgroup, the result of adding over two million “new” (updated) rows as trickle inserts into the deltastores. After at most five minutes, the tuple mover will kick in and start to convert these rowgroups to columnstore format. As explained before, this will be done for one rowgroup at a time, with intervals of 10-15 seconds between the rowgroups.
If we had updated the entire table, all originally compressed rowgroups would now be empty. They would still exist and contain all the original data, but all rows in them would be marked as deleted. At the same time, all 13.5 million rows in the table would have been inserted in 14 deltastores, that would then, over time, be converted to columnstore format by the tuple mover. As mentioned in the previous level, the tuple mover is a slow worker so it will take time until all rows are converted to columnstore format; during this time, queries that use the columnstore index will be slow. And after that, we still have all the old rowgroups taking up disk space because the deleted data is still there, until we take explicit action to rebuild the index. The mechanism used for updating data in a columnstore index has not been designed for this type of mass update. It works very well and with only minimal performance impact for occasional updates of single rows or small subsets of the population, but not for mass updates of the entire table or large subsets.
Locking and blocking
The read-only limitation of the nonclustered columnstore index automatically limited the options for data modification to just two strategies: either you would disable the index, make the modifications, then rebuild the index; or you would swap in and out entire partitions of the table – a very common strategy for the incremental load of a data warehouse. Both of these strategies will normally be done when there is no concurrent activity. But the option of modifying data in a clustered columnstore index in SQL Server 2014 means that we will now see modifications during business hours – so obviously we can also expect to see locking and blocking. To check how these modifications affect concurrency, let’s investigate the locks taken for a simple update of a single row. First, run the code from listing 6-3. Note that the ROLLBACK statement has deliberately been put in a comment block. We will later undo the change by selecting just the line with the ROLLBACK statement and then executing that selection, but we need the transaction to remain open for now.
USE ContosoRetailDW; GO -- Start a transaction, so we can investigate the locks taken BEGIN TRAN; -- Update just a single row UPDATE dbo.FactOnlineSales2 SET UpdateDate = CURRENT_TIMESTAMP WHERE OnlineSalesKey = 30000002; -- Do not rollback the transaction yet! /* ROLLBACK TRAN; */
Listing 6-3: Updating a single row
After running this update, open another tab in Management Studio and use it to run the code in listing 6-4 to get an overview of all locks currently held in the database.
USE ContosoRetailDW; GO -- Check the locks that are taken -- (Query adapted from http://www.nikoport.com/2013/07/07/clustered-columnstore-indexes-part-8-locking/) SELECT l.request_session_id, DB_NAME(l.resource_database_id) AS database_name, CASE WHEN l.resource_type = 'OBJECT' THEN OBJECT_NAME(l.resource_associated_entity_id) ELSE OBJECT_NAME(p.[object_id]) END AS [object_name], i.name AS index_name, l.resource_type, l.resource_description, l.request_mode, l.request_status FROM sys.dm_tran_locks AS l INNER JOIN sys.partitions AS p ON p.hobt_id = l.resource_associated_entity_id INNER JOIN sys.indexes AS i ON i.[object_id] = p.[object_id] AND i.index_id = p.index_id WHERE l.resource_associated_entity_id > 0 AND l.resource_database_id = DB_ID() ORDER BY l.request_session_id, resource_associated_entity_id;
Listing 6-4: Checking the locks

Figure 6-3: Locks for a single update
As you see, updating a single row results in two exclusive locks, both on a full rowgroup. To see which rowgroup is locked, check the last part of the resource_description column. On my system, rowgroups 21 and 23 are locked. Rowgroup 23 is where the updated row used to be stored; the lock is needed to mark the row as deleted. Rowgroup 21 is the open deltastore, where the contents of the row after the update are added. When you run this code, you may see different rowgroup numbers. That’s because how rows are distributed among rowgroups, and even the number of rowgroups created, depends on factors like processors and memory available when the columnstore index is created. Even when dropping and recreating the same columnstore index on the same instance, the rowgroup distribution can be different. You may also see only a lock on the open delta store; in that case the row you updated was moved there as a result of a previous update.
In figure 6.3 above, you also see U locks on rowgroups 0 through 3. SQL Server takes a U lock on all rowgroups it scans for an UPDATE statement. Normally that U lock is released when the rowgroups is scanned with no rows found to be updated, but due to internals of the processing mechanism that are out of scope for this article, these U locks are sometimes held. Do not worry if these locks do not show up when you run the code.
Locking full rowgroups is not very granular. However, it gets worse when you investigate the actual result of these locks. To see why, open a third query window and execute the code in listing 6-5, to retrieve data about a single row. On my system, this row resides in rowgroup 2. (I verified this before running the code in listing 6-3, by running that same code with OnlineSalesKey 31000000, using the code in listing 6-4 to check the locked rowgroups, and then rolling back the change). This rowgroup has only a U lock, which does not block queries that read data, so you might expect that this query will return. That is not the case. It will wait indefinitely, because it is blocked by the update from our first query. We can easily verify this by rerunning listing 6-4 to check the locks, which now returns eight rows as shown in figure 6-4.
USE ContosoRetailDW; GO -- Run a simple query SELECT OnlineSalesKey, StoreKey, CustomerKey FROM dbo.FactOnlineSales2 WHERE OnlineSalesKey = 31000000;
Listing 6-5: Trying to read a single row
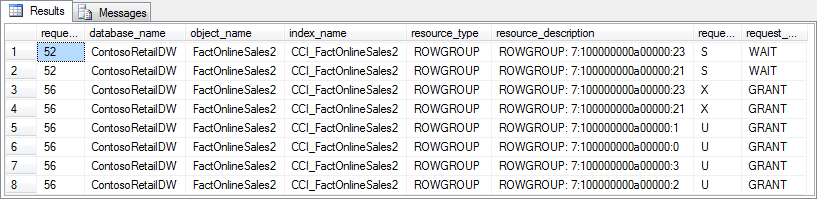
Figure 6-4: Select blocked by the update
These blocks occur because the optimizer doesn’t know that values in the OnlineSalesKey column are unique. We were unable to tell SQL Server, because one of the many restrictions for clustered columnstore indexes is that they don’t support PRIMARY KEY or UNIQUE constraints on the table. (We’ll see more details on these restrictions in a later level). So even though SQL Server does find a row in rowgroup 2, it still wants to search all other rowgroups to see if there are more matching rows; hence it has to wait until the locks on rowgroups 21 and 23 are lifted. If you go back to listing 6-3 and execute only the ROLLBACK statement, you will see that the query running listing 6-5 now finishes, and rerunning listing 6-4 will not return any results. Committing the update would of course have had the same effect.
Effectively, the locks taken at rowgroup level block almost all concurrent access to the table. There are only a few very specific scenarios where this is not the case. To see one of them, rerun listing 6-3 to acquire the same locks again, then run listing 6-6. This is the same as listing 6-5, but with a TOP( 1) clause added. This query will actually return results immediately. After finding the matching row in rowgroup 2, SQL Server no longer needs to check for matches in other rowgroups. It does not need to take locks on those rowgroups anymore, and if it already was waiting for locks on one or both locked rowgroups, it will cancel the lock request. (Note that in order to reproduce this effect on your system, you will need to use a value in the WHERE clause that will be found before the locked rowgroups are processed, unless your degree of parallelism is higher than the number of locked rowgroups).
USE ContosoRetailDW; GO -- Run a simple query SELECT TOP(1) OnlineSalesKey, StoreKey, CustomerKey FROM dbo.FactOnlineSales2 WHERE OnlineSalesKey = 31000000;
Listing 6-6: Another attempt to read a single row
Another reason why SQL Server can sometimes execute a SELECT query even when rowgroups are locked is because of segment elimination. This only works if the locked rowgroups are in compressed columnstore format – a deltastore does not have min_data_id and max_data_id recorded in sys.column_store_segments , so it never qualifies for segment elimination. So in order to see this in action, we will have to change the modification type from an update to a delete – this will still lock the compressed rowgroup because it needs to mark the row as deleted, but it will not lock the deltastore because no new data is added. Rollback all open transactions, then run the code in listing 6-7 to generate just a single X lock on rowgroup 2 (on my system). You can verify this, if you wish, by rerunning listing 6-4.
USE ContosoRetailDW; GO -- Start a transaction, so we can investigate the locks taken BEGIN TRAN; -- Delete just a single row DELETE dbo.FactOnlineSales2 WHERE OnlineSalesKey = 31000000; -- Do not rollback the transaction yet! /* ROLLBACK TRAN; */
Listing 6-7: Deleting a single row
In order to demonstrate how some values can bypass the locked rowgroup, I first need to find a column that does not store string values, and that has values that exist in some rowgroups, but for which the locked rowgroup (rowgroup 2 in my case) can be eliminated. The code in listing 6-8 helps me to quickly locate such a column and the appropriate values. (Don’t forget to change the number 2 to whatever rowgroup has the X lock on your system if you want to run the same code)
USE ContosoRetailDW; GO SELECT c.name AS ColumnName, s.segment_id, s.min_data_id, s.max_data_id, s2.min_data_id AS min_data_id__segment_2, s2.max_data_id AS max_data_id__segment_2 FROM sys.column_store_segments AS s INNER JOIN sys.column_store_segments AS s2 ON s2.[partition_id] = s.[partition_id] AND s2.hobt_id = s.hobt_id AND s2.column_id = s.column_id AND s2.segment_id = 2 INNER JOIN sys.partitions AS p ON p.hobt_id = s.hobt_id INNER JOIN sys.indexes AS i ON i.object_id = p.object_id AND i.index_id = p.index_id INNER JOIN sys.index_columns AS ic ON ic.object_id = i.object_id AND ic.index_id = i.index_id AND ic.index_column_id = s.column_id INNER JOIN sys.columns AS c ON c.object_id = ic.object_id AND c.column_id = ic.column_id AND c.collation_name IS NULL -– No strings WHERE i.name = N'CCI_FactOnlineSales2' AND ( s.min_data_id < s2.min_data_id OR s.max_data_id > s2.max_data_id);
Listing 6-8: Helper code to find the values to use next
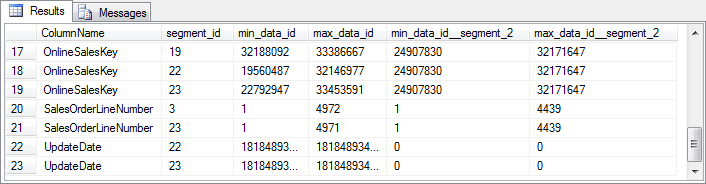
Figure 6-5: Data to use to demo segment elimination
As can be seen from the partial query results (for my system) in figure 6-5, the segment for the SalesOrderLineNumber column in rowgroup 2 has a max_data_id of 4439 in sys.column_store_segments ; two other rowgroups have a higher max_data_id . If I run the SELECT statement from listing 6-9, it will finish, even though rowgroup 2 is locked. Even before it requests an S lock on the rowgroup, it checks the metadata and sees that the rowgroup can be skipped because of segment elimination. Change the WHERE clause as indicated in the comments, and now the rowgroup no longer can be eliminated – now the query will be blocked by the DELETE . Once you roll back that connection, the query will finish.
(Note that, in order to reproduce this example, you will probably have to change the columns and values used, depending on the results returned on your system by listing 6-8).
USE ContosoRetailDW; GO -- Run a simple query SELECT COUNT(*) FROM dbo.FactOnlineSales2 WHERE SalesOrderLineNumber = 4500; -- Does not block --WHERE SalesOrderLineNumber = 4400; -- Does block
Listing 6-9: Deleting a single row
Apart from these two special cases where a query can read data even when rowgroups are locked, there is one final option: explicitly reduce the transaction isolation level. The snapshot isolation level is not supported on tables with a clustered columnstore index, but you can set the transaction isolation level to READ UNCOMMITTED or use the NOLOCK hint (which is equivalent). This allows SQL Server to ignore all locks and simply read the data it encounters. The effect is that you may read dirty data – if I roll back an update, the new data logically never existed. But an aggregation with NOLOCK would still count the affected rows under the “new” values. You can also encounter the same row twice, for example when a scan reads a row in an compressed rowgroup before it is marked as deleted by a concurrent update, then reads the same row with new values again when it scans the deltastore. In the same way it is also possible to miss an existing row completely. However, with all these caveats in mind, allowing SQL Server to read uncommitted data can be an acceptable way to avoid blocking on reports if those reports aggregate their data to such a level that a small margin of error is acceptable.
Another locking hint you can use to ignore existing locks is the READPAST hint, which instructs SQL Server to simply skip locked rows. This is supported for columnstore indexes, but because locks are taken at the rowgroup level the effect will not be to skip a single row, but a complete rowgroup. I cannot imagine any case where it would be acceptable to occasionally skip millions of rows for a report, so I would not recommend using this locking hint to avoid blocking by concurrent updates.
Conclusion
In this level, we looked at what happens when you update or delete data from a clustered columnstore index. The data is not really deleted but marked as deleted, and the new version of the row is inserted in the deltastore, the same way trickle inserts are. Because columnstore indexes have no way to identify single rows, all modifications will always lock entire rowgroups. Unless you deliberately accept reading dirty data, this effectively blocks almost all concurrent access.
Over time, modifications to data in a columnstore index will deteriorate its usefulness. Rows marked as deleted still take up space, trickle inserts and small bulk loads will not compress as effectively, and the global dictionary will never change after the initial index build; all this impacts the compression ratio, resulting in more IOs for the same query. And bulk loads and trickle inserts will also rarely result in rowgroups that are optimized for segment elimination. So the price we have to pay for allowing modifications to the columnstore index is that we now will have to monitor and maintain the quality of these indexes. We’ll look at that topic in more detail in the next level of this series.