
Welcome to level 7 of the stairway to Always On. In this level we will look at how a Failover Cluster Instance of SQL Server integrates as a replica in an Always On Availability group. We'll look at the ramifications this has and also how the complexity increases by combining these two technologies. By the end of this level you should understand the feature integration and will be able to make the decision as to whether you actually need to implement this type of system or not.
There should be no illusion, this type of system will be complex to setup and maintain. There are also various constraints that will be applied to the Availability Group(s) and these will be a direct result of the integration between the standalone instances and the Failover Cluster Instance.
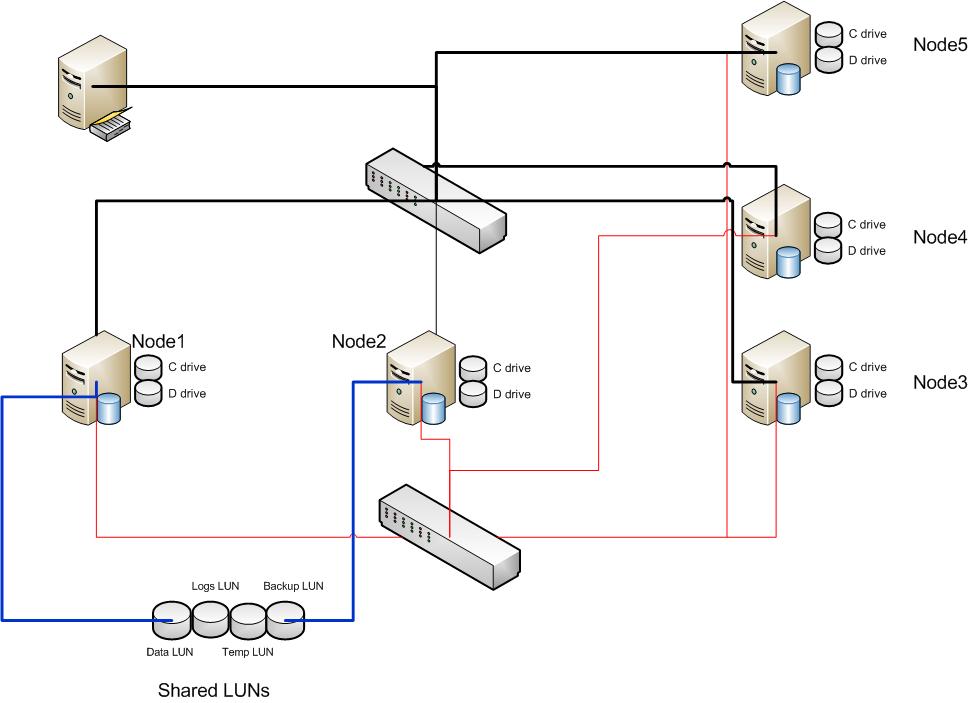
Let's take a look at a typical representation of a traditional Always On Availability group utilising cluster nodes with two standalone replicas. This is a fairly simple setup. There are two nodes, each with an instance of SQL Server, and their own local disk storage directly attached to the server. There is an Always On Availability group across the two instances\replicas. The two nodes could be on separate sites and the configuration would still be extremely simple to manage.
Diagram 7.1
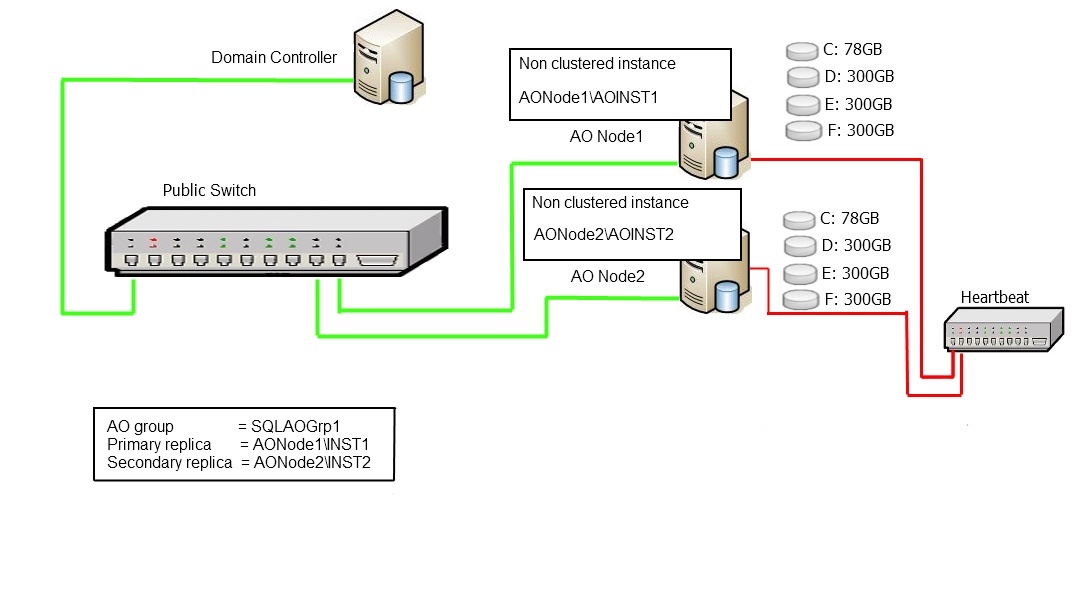
Now let's look at an FCI integrated Always On Availability group system utilising one standalone replica and one Failover Cluster Instance replica. The complexity over the previous system should be fairly evident.
Diagram 7.2
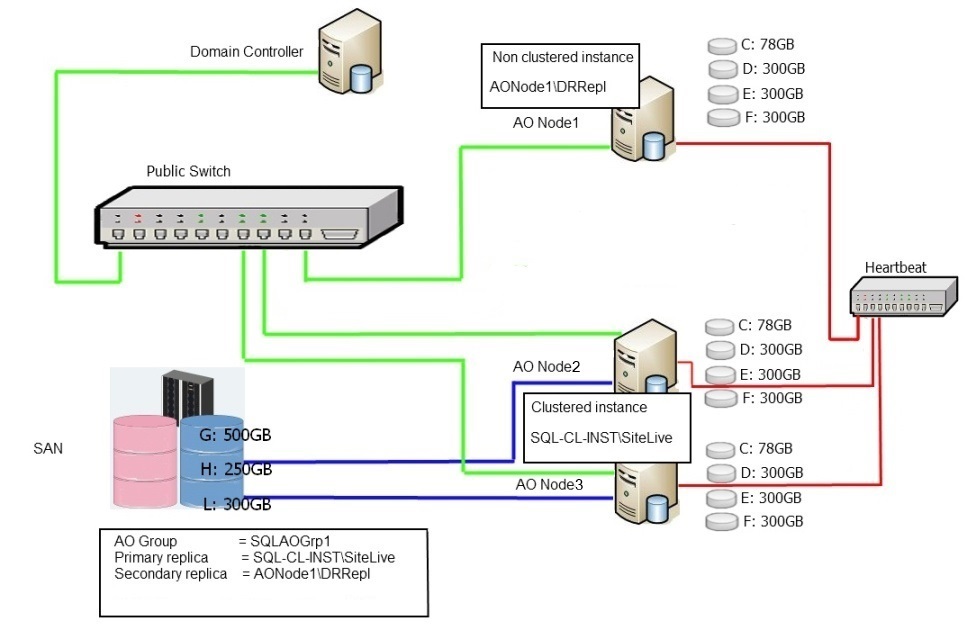
If you look at the immediately obvious difference between the two systems, you'll see three nodes instead of two. One of the Primary constraints\restrictions that are enforced in an Always On Availability group is that any single replica (clustered or non clustered) must reside on a separate physical node to partner replicas in the same group.
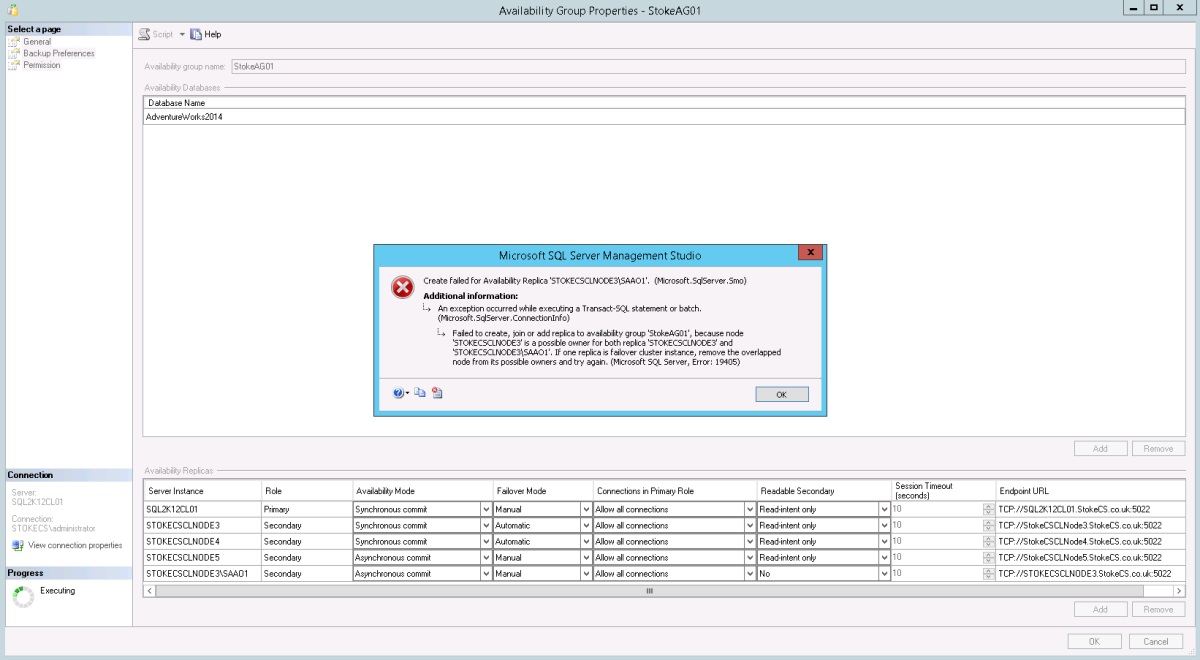
When attempting to add two replicas from the same physical node you will see the following error dialog.
The error message states “Failed to create, join or add a replica to availability group xxx, because node xxxxx is a possible owner for both replica xxxx and replica xxxx. If one replica is a failover cluster instance, remove the overlapped node from the possible owners list and try again”.
Diagram 7.3
As we have integrated an FCI on Node 2 and Node 3, any Always On group we add this replica to must automatically exclude nodes 2 and 3. This is because the FCI may be serviced on either node at any time.
So, from this we can see that integrating an FCI potentially increases the number of cluster nodes required to support the overall configuration. In fact, if the FCI were to be installed across three nodes instead of two, this would push the scenario above to a four node cluster. How much does the average enterprise class server cost nowadays?
Also, you should have noticed by now the reliance on shared storage to service the FCI. This is usually anything but cheap or easy to implement and even maintain. When you start cross site replication things get even more interesting (and expensive). Once cross site storage replication is introduced, the hardware costs and management requirements rise rapidly.
There's another problem that you may not have noticed yet if you've worked with the standard configuration of standalone replicas in an Always On Availability group. The issue is disk drive assignments. When you install a Failover Cluster Instance of SQL Server, all of the disk assignments used are claimed within the whole cluster. This prevents more than one Failover Cluster Instance from using the same drive assignments.
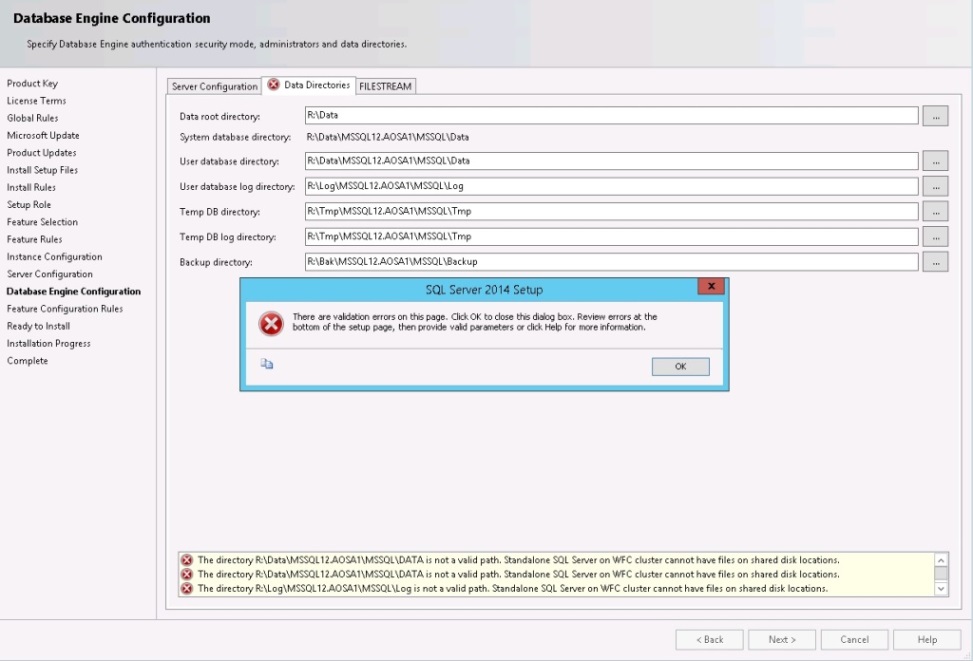
Unfortunately, this also affects a standalone installation of SQL Server when the computer node is part of a Windows Server Failover Cluster that has FCIs deployed. During the server configuration section of the stand alone install, where you configure the disk paths, if you select assignments already in use within the cluster the installer will throw an error and prevent Setup from completing any further. See Diagram 7.4
Let's take a closer look to see how this becomes an issue. Looking at our diagram 7.2 above we have Node 2 and Node 3 with shared SAN presented disks using the drive letters
- G:
- H:
- L:
We have a further node, Node 1, which has local disks
- C:
- D:
- E:
- F:
On Node 1 where we wish to have the standalone instance installed, If we changed the drive letters thus
- D: -> G:
- E: -> H:
- F: -> L:
And attempt a standalone install, we would see the installer error message as shown below in Diagram 7.4
Diagram 7.4
Now, there is a workaround floating the internet, but I'm fairly certain it's not supported by Microsoft. The workaround is as follows. If you remove your node from the cluster first and then install the standalone instance, when you join the node back to the cluster you'll have no issues. Be careful here, if you ever wanted to extend your FCI across this node you would be unable to do so.
The fact that standalone instances and FCIs cannot legally share the same disk assignments within the same cluster, is probably one compelling reason why automatic failover is unavailable when FCIs are used in Always On Availability groups. Notably, add file operations would fail due to the requirement to use disparate file paths. A database could not be brought online automatically if database files were unavailable.
So, whilst FCIs are supported in Availability Groups there are issues around doing this. Let's look at a slightly larger scenario to see how an FCI integrated group would look scaled up, In my scenario I have 5 nodes in the cluster, they are configured as follows
Diagram 7.5
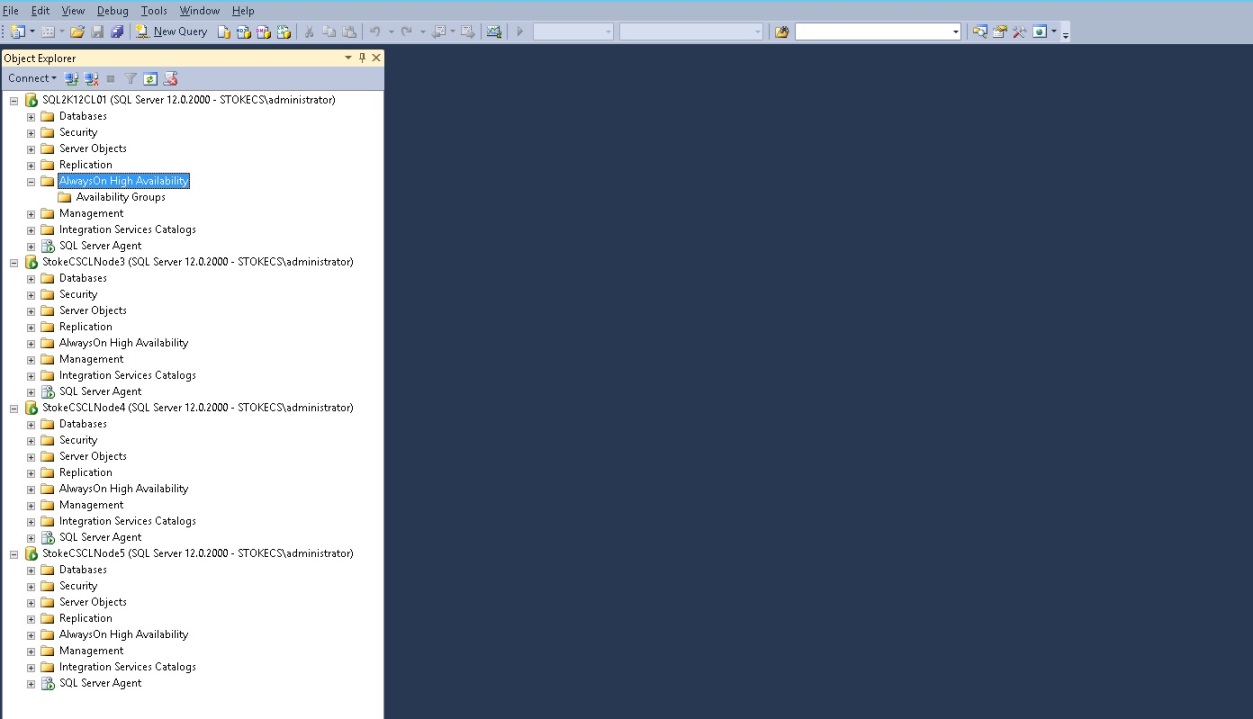
Installed Instances
StokeCSCLNode1 -Default Clustered Instance installed as SQL2K12CL01
StokeCSCLNode2 -Default Clustered Instance installed as SQL2K12CL01
StokeCSCLNode3 -Default standalone instance as StokeCSCLNode3
StokeCSCLNode4 -Default standalone instance as StokeCSCLNode4
StokeCSCLNode5 -Default standalone instance as StokeCSCLNode5
The instances, when registered in SQL Server Management Studio, appear as shown below in Diagram 7.6
Diagram 7.6
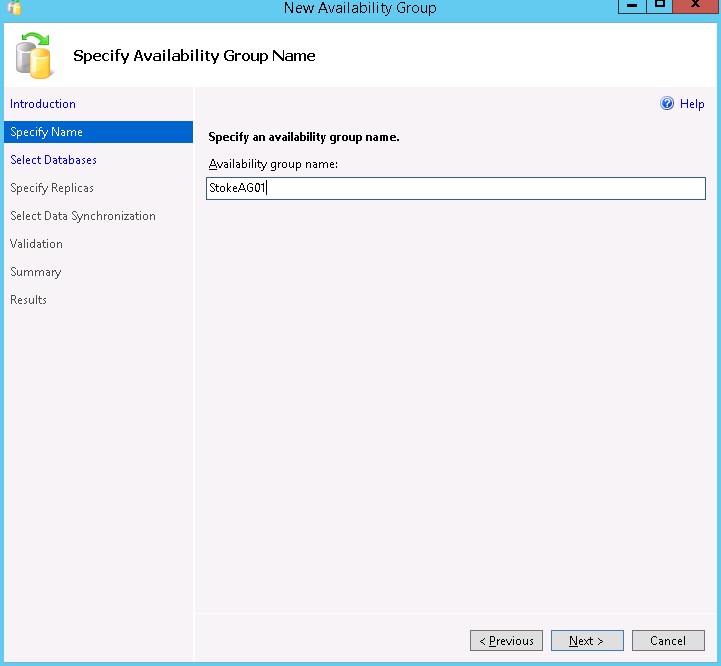
Looking at the wizard steps for my group, I'm creating an Availability group across the four instances\replicas. It's fairly simple here, and we've covered the wizard already in Level 6 of the Stairway, so I'll be brief. The group name step is shown below in Diagram 7.7
Diagram 7.7
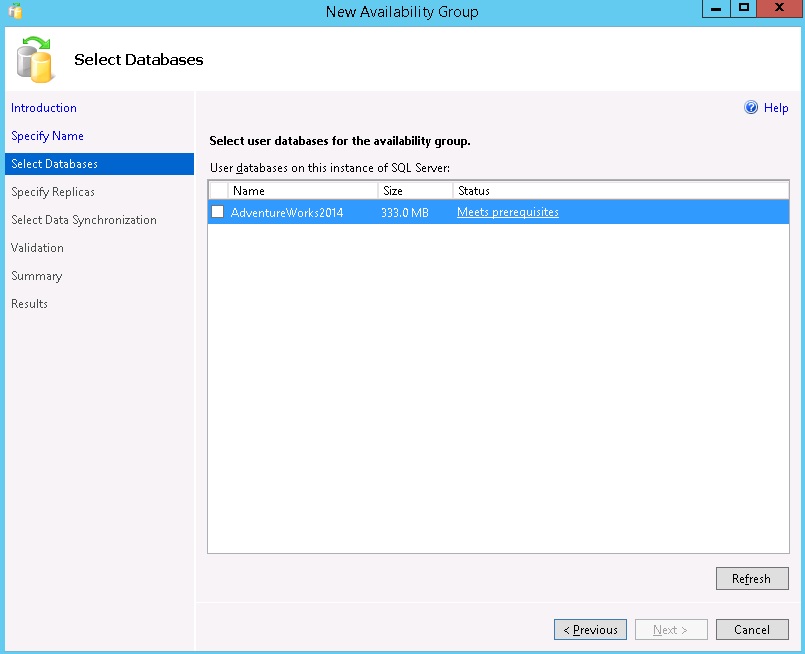
The wizard checks any databases on the initially selected replica. They must meet the pre-requisites enforced by the Availability group wizard. See Dia gram 7.8
Diagram 7.8
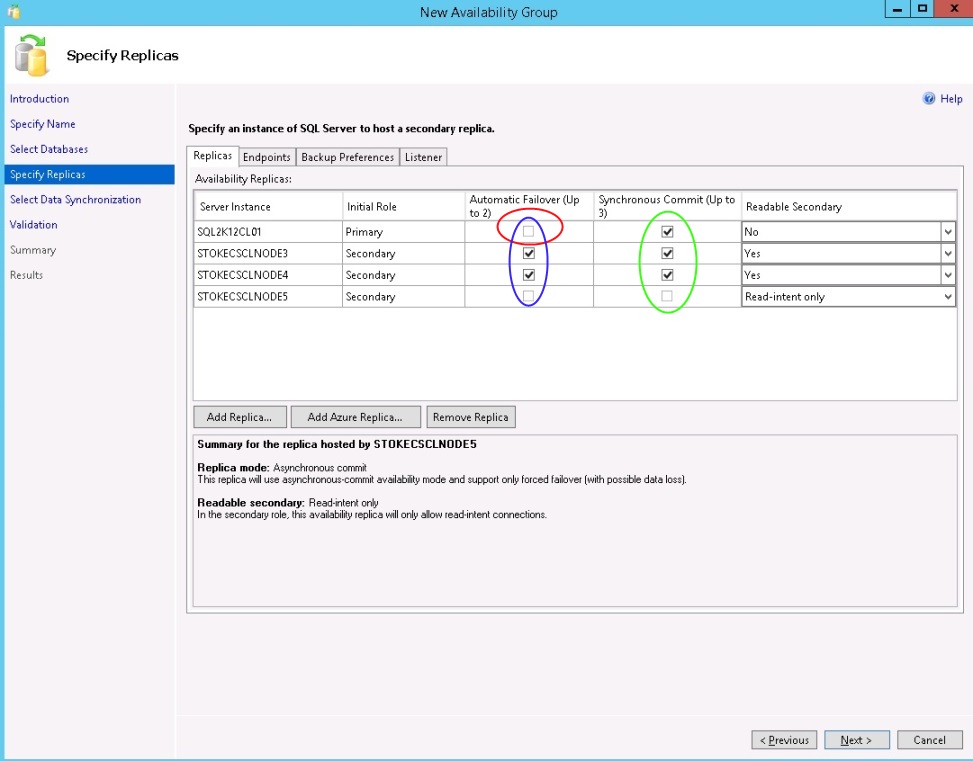
When we specify the instances\replicas, you will notice that the FCI is not configurable for Automatic Failover. Any failover must be a manual process (we'll see more on this later in the article). Let's review the options below to understand what restrictions are placed upon us for the group configuration.
- Red Ellipse - This shows us that the option to select automatic failover for this replica is unavailable, why is this? Because it is a Failover Cluster Instance of SQL Server.
- Green Ellipse - This shows the maximum number of synchronous replicas has been selected. Only three replicas may be selected for synchronous replication at any one time.
- Blue Ellipse - This shows that the maximum number of two replicas have been configured for automatic failover.
Diagram 7.9
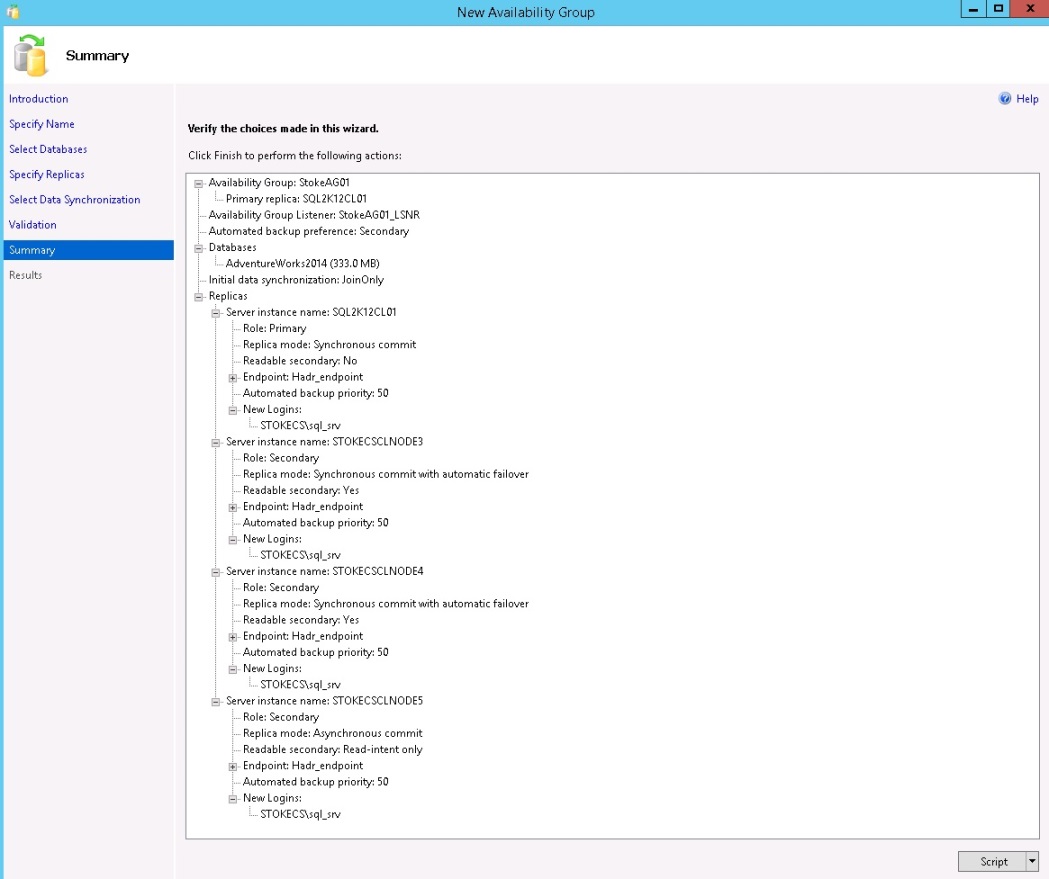
Here is the wizard summary for my FCI integrated Always On Availability group.
Diagram 7.10
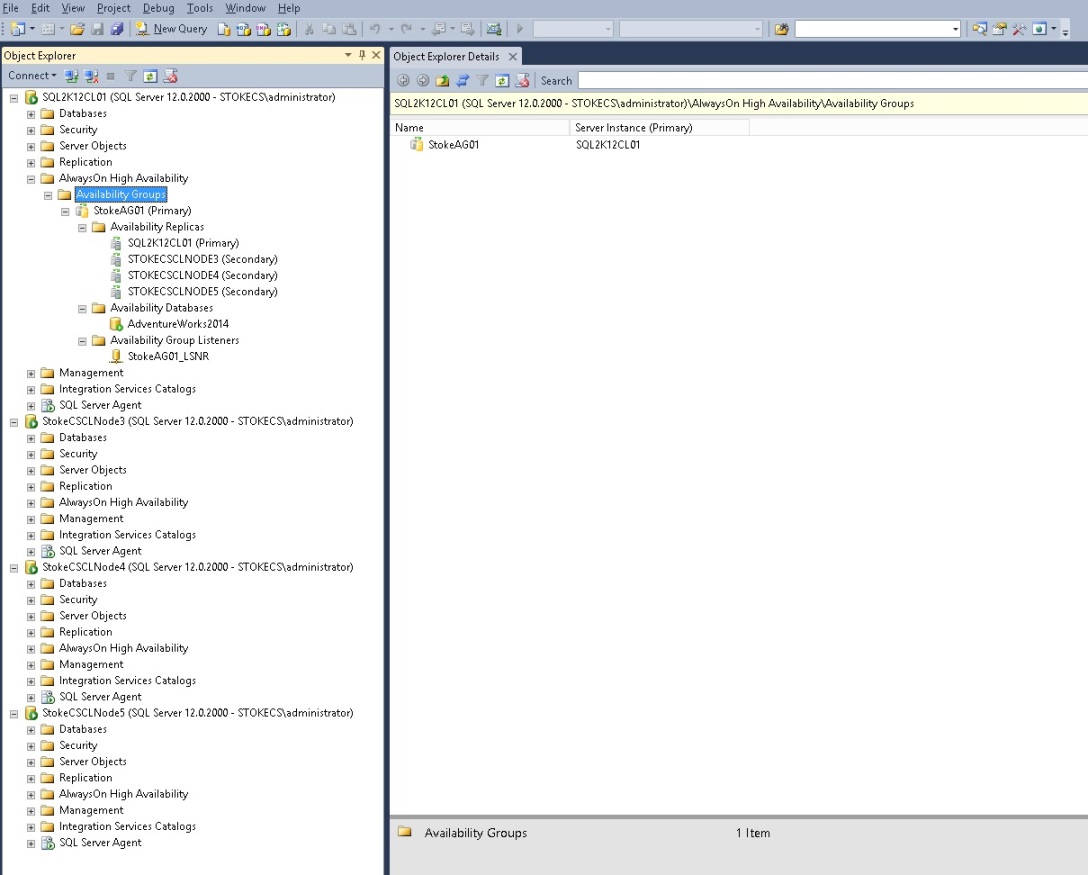
Here we see the new group with the four replicas defined during the wizard. Below we see the replica "SQL2K12CL01", which is a Failover Cluster Instance of SQL Server. It doesn't really look too different to what you would normally see.
Diagram 7.11
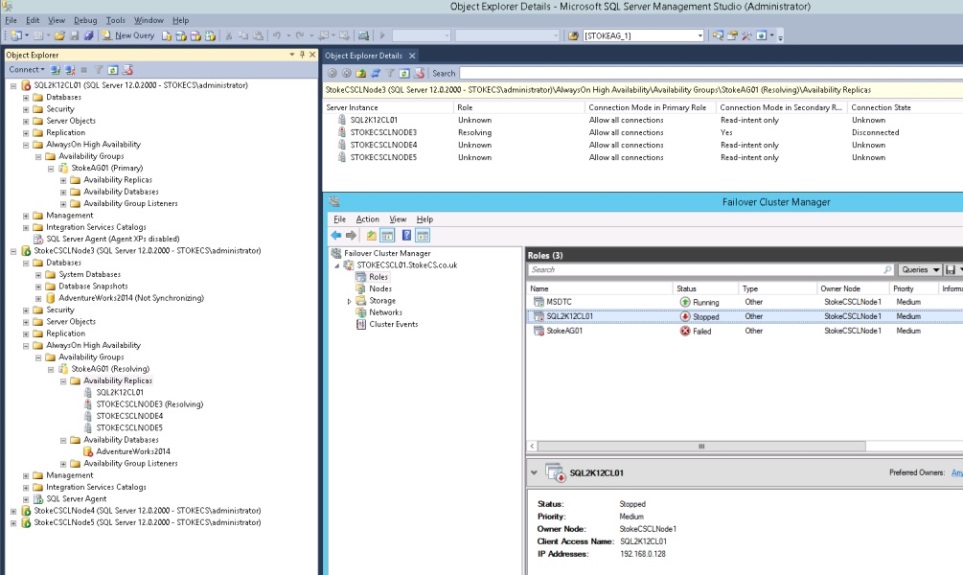
We now know that an Always On Availability group that utilises an FCI, will only support a manual failover between the FCI itself and any other replicas. How does this look when the FCI is offline?
Upon failure or prolonged outage of the FCI Primary replica, the Always On Group cluster resource is offline. No automatic failover is available. If no manual intervention is provided, the group will stay in this configuration. Providing high availability at an instance level for an Always On group replica has had a profound effect on the group uptime. This should be looked at in great detail to ascertain if your system can handle an outage of this magnitude.
Diagram 7.12
Integrating technologies can have its advantages, but here, when using FCIs, there are clearly more disadvantages it would seem. Opting for a traditional Always On Availability group with no shared storage keeps the design simple and potentially decreases the number of cluster nodes required to support the WSFC and the group configuration.
Great care should be taken during the design phase to ensure that budget constraints are adhered to and more importantly the system is supportable operationally by the support teams. In the last few years I have encountered many "over engineered" systems whereby the design team just merely looked to use all available technologies regardless of design complexity and budget costs.
Providing a well thought system within budget and fully documented for your operational support teams will likely get you noticed far more by the boss than providing a budget busting behemoth of a system that falls over at the first sign of trouble.
I hope this stairway series has been useful, you should now have a firm grounding with WSFCs and Always On. Setup your virtual test system and iron out any issue early on. As always, if you have any problems post in the discussion thread and I'll help all I can