

Background
In the previous article we discussed the need for a SaaS solution my past clients and the various Multi-Tenant data architecture options. This time we will focus on how to address the challenges posed by the chosen architecture.
Challenges and Goals
To recap we chose the hybrid option where we have a single multi-tenant database and ETL code. Within the database server we have separate staging and data warehouse databases. In the staging database we have customer specific areas where we land our extracts. This allows for varying table formats from different sources and versions of our clients’ data. We also have a generic staging area in the staging database where data is normalized into a common, multi-tenant format. The data warehouse database is multi-tenant also.
The places where we have multi-tenancy poses several challenges:
- How to segregate the data for performance reasons
- How to prevent the stepping on tenants’ data during loads
- How to allow for multiple separate data transformation (ETL) loads for each tenant
- How to handle tenant specific business rules for each tenant
Each of these topics could be a separate post but I will focus on items 1 and 2 from above in this article. My main goals on resolving these challenges were:
- Use best practices to address these challenges
- Utilize pre-built tools to minimize development costs
Segregate the data and avoid wiping out other tenants data
We added a customer identifier to every table that was multi-tenant. We want to segregate the data for both security and performance reasons. Security is important because if developers write queries without the customer ID, all of the customers’ data would be returned. Also, we don’t want to load over the wrong customer’s data either.
On the performance side, when running relational queries, customer #1 only looks at their slice of the data and thus less data is read, leading to faster query response time. Also the customer id is used in the BI layer to ensure only the applicable data is seen. The vast majority of reporting will be isolated. However one of the benefits of having the data for all tenants in one table is that we could do cross customer reporting if needed.
We used SQL Server table partitioning to further implement the data segregation using the customer identifier as the partitioning key. For details on how to implement table partitioning in detail, please see Kimberly Tripp’s blog (http://technet.microsoft.com/en-US/library/ms345146(v=SQL.90).aspx ).
To give room for future customer growth I setup the partition function and scheme to handle 10 tenants (It can be expanded later with a little work).
The high level steps for table partitioning are:
- Create the file groups, files, partition function, partition scheme
- Partition the tables.
- Later resize the files in the file groups after moving them away from PRIMARY which is the default file group
When performing ETL the partitioning strategy needs to be considered. Often Data Warehouses or Marts have some fact tables which need to be truncated and reloaded nightly. This truncate and reload scenario causes challenges for a multi-tenant architecture. Suppose we have customer 1’s data load that runs from 6-7AM and customer 2’s load that runs from 8-9AM. If we have a fact table that is truncated and reloaded, the data loads will wipe out each customer’s data. By having the data segregated with partitioning we can address this concern.
Here is how we leveraged SQL Server table partitioning and partition switching to resolve this challenge. Note, most DW resources use partition switching/merging for the time sliding window scenario which is not covered in this article. For our multi-tenant model we have a different usage of these tools. Remember that we partitioned the data on our tables by customer Id. For this example we are loading customer 1’s data and we only have two customers. Customer 1’s data is already loaded in partition 1 and customer 2’s data in partition 2.
- The first thing we do is switch out the partition #1 (or slice) of the partitioned table to a non-partitioned table. Done correctly, this is a metadata operation only and completes quickly. Switching out this partition creates a non-partitioned table.
- Truncate this non-partitioned table (thus clearing out the old data for customer 1). This avoids truncating the whole partitioned table and clobbering other customers’ data.
- Load the new / incoming data into the non-partitioned table
- Switch the newly loaded table back into the partitioned table. Now we have the new customer #1 data along with the old customer #2 in the table (Their load hadn’t taken place for the day yet).
- Remove the non-partitioned table
Below is how this looks inside of one of our SSIS packages (see figure #1). The details of this implementation will be covered in detail in a previous article.
One of the tricky parts of step 1 is making sure the non-partitioned table is in the same filegroup as the partition number in the partitioned table. Also the indexes and constraints need to be exactly the same on both tables.
In order to reduce development time I utilized the ManagePartition command line utility available on Codeplex (http://sqlpartitionmgmt.codeplex.com/). This tool assigns the correct filegroup, creates the switch-out table like the original. It also ensures that if the base table changes, that the newly created non-partitioned table would mimic that change. Aside from fact tables, many of our tables in our Staging database were shared and thus also needed to employ the switching technique there as well.
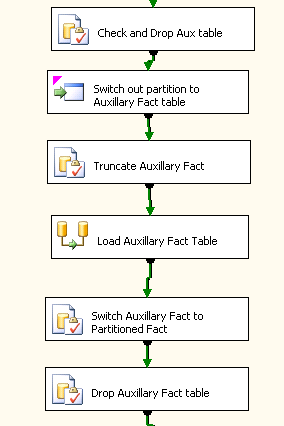
Figure1 Snippet of an SSIS package that handles partition switching
Summary
We addressed data storage and loading by using partitioning techniques. This allows us to segregate the data for both security and performance reasons. Each customer ends up having its own partition in a larger partitioned table. It also addresses challenges in the truncate and reload scenario with multi-tenant table. We also discussed how the partition switching scheme used here is different than traditional uses. In the next article we will dive into the details of implementing partition switching in SSIS.
