Introduction
In Level 1 of this series, I discussed Synapse Analytics basics and the steps for creating the Synapse Workspace. In Level 2, we analyzed Data Lake files using the Serverless SQL Pool. In Level 3, we analyzed Data Lake files using the Spark Pool. In Levels 4 and level 5, I will discuss the Delta Lake.
Delta Lake is open-source relational storage for Spark. Delta Lake acts as an additional layer over the Data Lake and can be used to implement a Data Lakehouse architecture in Azure Synapse Analytics. Delta Lake is supported in Azure Synapse Analytics Spark pools for PySpark, Scala, and .NET code.
Delta Lake supports the following features:
- ACID transactions
- Data versioning and Time travel
- Streaming and batch unification
- Schema enforcement and evolution
- Data modification
- Performance improvement
Data Analysis Steps
I will explain the steps to create and use the Delta Lake and explore the features.
Create Delta Lake from a dataframe
I create a new notebook in Synapse Studio. I attach the notebook to the Spark pool using the drop down at the top of the notebook. I add a code cell and write the code given below. This code populates a dataframe from the csv file present in the linked storage account.
from pyspark.sql.types import *
from pyspark.sql.functions import *
sampleSchema = StructType([
StructField("PassengerId", IntegerType()),
StructField("Survived", IntegerType()),
StructField("Pclass", IntegerType()),
StructField("Name", StringType()),
StructField("Gender", StringType()),
StructField("Age", FloatType()),
StructField("SibSp", IntegerType()),
StructField("Parch", IntegerType()),
StructField("Ticket", StringType()),
StructField("Fare", FloatType()),
StructField("Cabin", StringType()),
StructField("Embarked", StringType())
])
df = spark.read.load('abfss://dlsafssd1@dlsasd1.dfs.core.windows.net/sample_csv.csv',
format='csv',
schema=sampleSchema,
header=False)
display(df.limit(5))I save the dataframe to a new folder location in delta format in the below code. This is the easiest way to create a Delta Lake table from a dataframe.
delta_table_path = "/delta/passengers-data"
df.write.format("delta").save(delta_table_path)
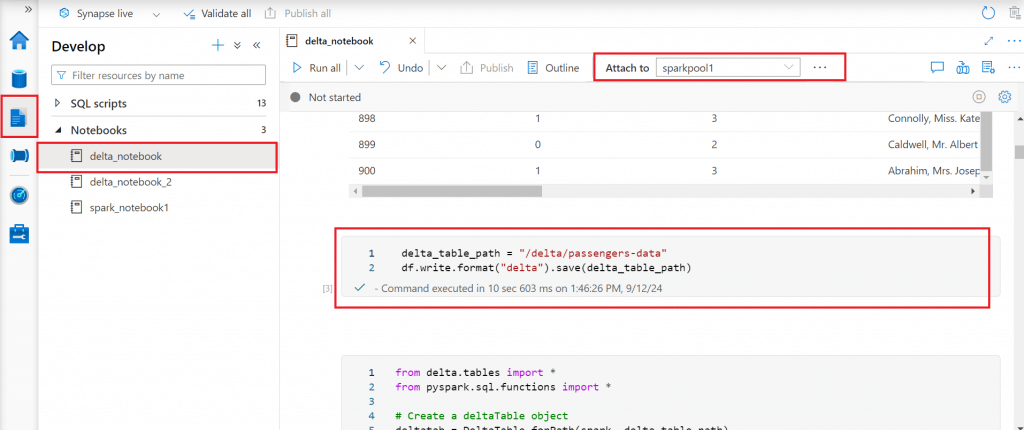
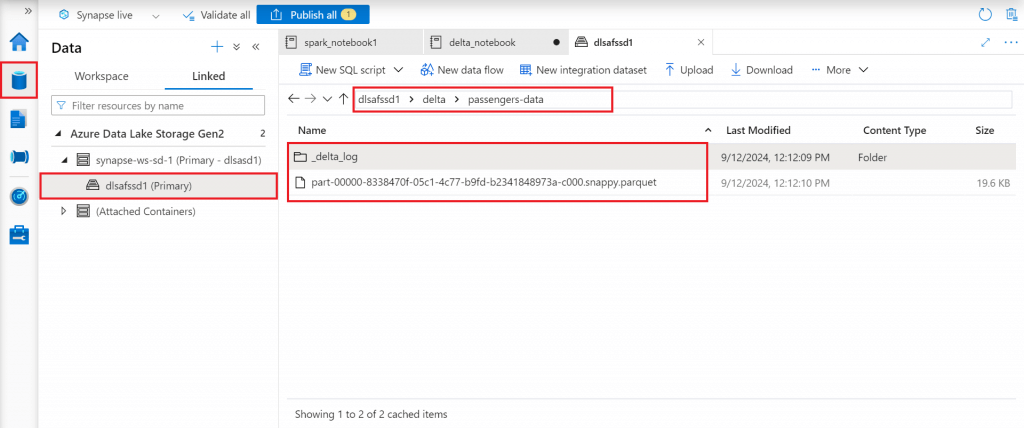
Verify the delta table path
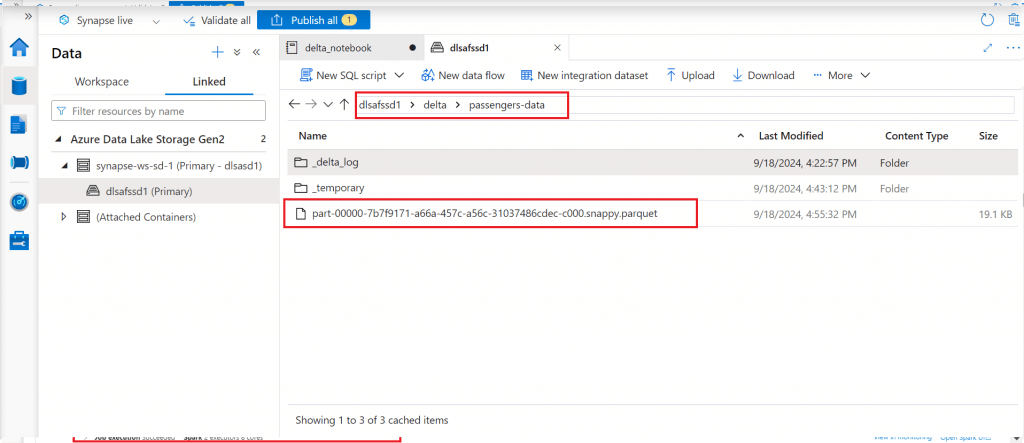
I go to the folder location where the data is saved in delta format. There is a parquet file present in the folder which contains the data. Also, there is a folder named _delta_log which contains the log details for each operation on the delta table. I will discuss more on the log while discussing the Delta Lake features.
Update and Delete Delta Table Data
Insert, update and delete can be made to an existing delta table. DeltaTable is the main class for programmatically interacting with Delta tables. A DeltaTable instance can be created using the path of the delta table.
I write code to update field values in delta table records based on a given condition. Then, I delete records from the delta table for a given condition. I print the total count of records in the delta table before and after the deletion.
from delta.tables import *
from pyspark.sql.functions import *
# Create a deltaTable object
deltatab = DeltaTable.forPath(spark, delta_table_path)
# Update the table
deltatab.update(
condition = "PassengerId == 892",
set = { "Name": "'TestName'" , "Pclass": "0"})
# View the updated data as a dataframe
display(deltatab.toDF().limit(10))
print("total count before delete: ", deltatab.toDF().count())
# Delete records from the table
deltatab.delete("Age > 60")
print("total count after delete: ", deltatab.toDF().count())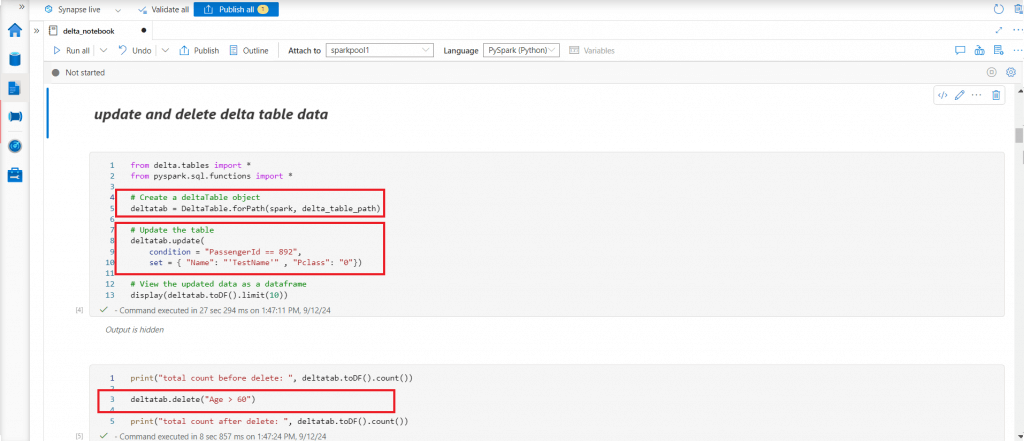
Create and use catalog tables
In the previous steps, I created a Delta Lake table instance from a dataframe and modified through the Delta Lake API. A Delta Lake table can be defined as a catalog table in the Hive Metastore for the Spark pool. I can work with the delta catalog table using SQL. A Hive Metastore in Azure Synapse Analytics is a relational database that stores metadata such as the data's format and paths to the data. It also stores definitions and schemas for each table. The Hive Metastore enables efficient data querying and analytics.
First, I create a new database and then create an external delta table using the previously defined delta table path. I use Spark SQL module to create the database and the table. Next, I use SQL command to retrieve the metadata about the table using Describe Extended statement.
spark.sql("CREATE DATABASE TestForDelta")
spark.sql("CREATE TABLE TestForDelta.PassengersExternal USING DELTA LOCATION '{0}'".format(delta_table_path))
spark.sql("DESCRIBE EXTENDED TestForDelta.PassengersExternal").show(truncate=False)
%%sql use TestForDelta; DESCRIBE EXTENDED PassengersExternal
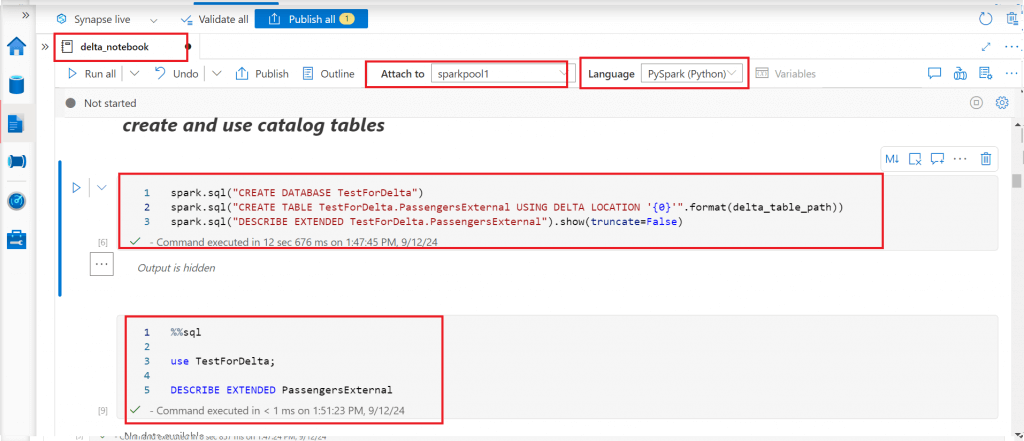
Use Delta Lake Table History
Each operation that modifies a Delta Lake table creates a new table version. Table history information can be used for auditing data changes, can rollback a table to a previous version, or query a table at an earlier point in time using time travel. The History command is used to return the table history in reverse chronological order. Table history is maintained for last 30 days by default. This duration can be changed using the table setting delta.logRetentionDuration.
I use the Describe History SQL command to retrieve the change history for the external catalog delta table. The output shows three records and the operations are write, update, and, delete. As a first step, data was written to the table and then data was updated, and deleted respectively. All the operations done on the table are displayed as shown in the image below.
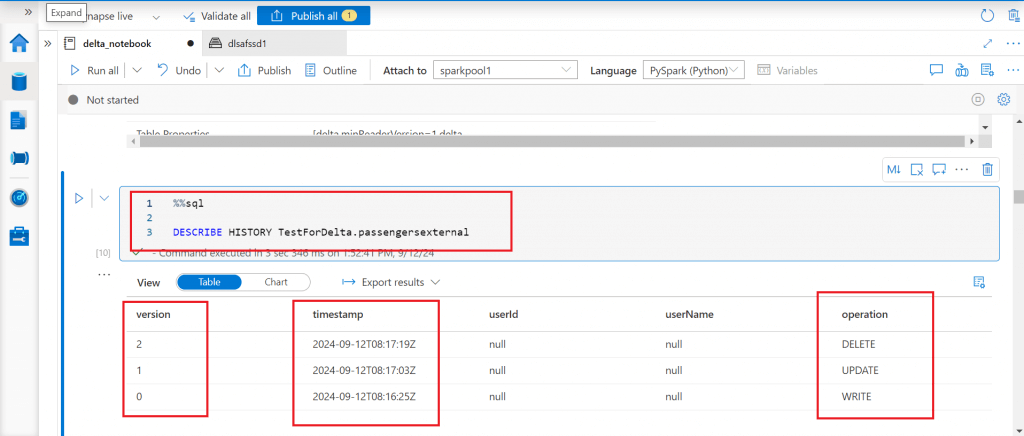
I write a Select statement to retrieve data at a particular timestamp and another Select statement to retrieve data for a particular version of the delta table. The code is as given below.
%sql SELECT COUNT(*) as Computed FROM TestForDelta.passengersexternal TIMESTAMP AS OF "2024-09-12T08:17:03Z" %sql SELECT COUNT(*) as Computed FROM TestForDelta.passengersexternal VERSION AS OF 1
I use insert statement to add records in the table from a previous version and use merge statement to update records in the table from a previous version. The history command output shows the details for all the changes done so far on the delta table.
%sql INSERT INTO TestForDelta.passengersexternal SELECT * FROM TestForDelta.passengersexternal TIMESTAMP AS OF "2024-09-12T08:17:03Z" WHERE Age > 60 %sql MERGE INTO TestForDelta.passengersexternal AS dest USING (SELECT * FROM TestForDelta.passengersexternal TIMESTAMP AS OF "2024-09-12T08:16:25.06") AS src ON src.PassengerId = dest.PassengerId WHEN MATCHED THEN UPDATE SET * %sql select Name, Pclass from TestForDelta.passengersexternal where PassengerId = 892 %sql DESCRIBE HISTORY TestForDelta.passengersexternal
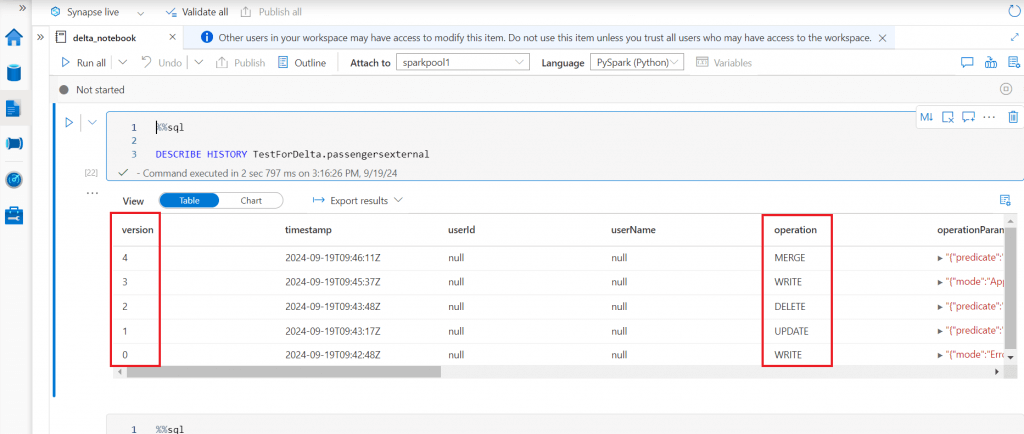
I use the Restore Table statement to rollback the table to a previous version.
%sql use TestForDelta; RESTORE TABLE passengersexternal TO VERSION AS OF 2
Work with the Transaction Log
The Delta Lake transaction log is an ordered record of every transaction that has ever been performed on a Delta Lake table since its inception. This transaction log helps to maintain atomicity for the delta table. When a Delta Lake table is created, the transaction log is automatically created in the _delta_log subdirectory. When any change is made to the table, the change is recorded as ordered, atomic commits in the transaction log. Each commit is written out as a JSON file. Once several commits are made to the transaction log, Delta Lake saves a checkpoint file in parquet format. The checkpoint file saves the entire state of the table at a point in time - in native Parquet format that is quick and easy for Spark to read.
I go to the _delta_log folder for the table. The json log files are available in the folder. A checkpoint file is also available in parquet format. The checkpoint file contains the state of the table upto the last log file present in the folder.
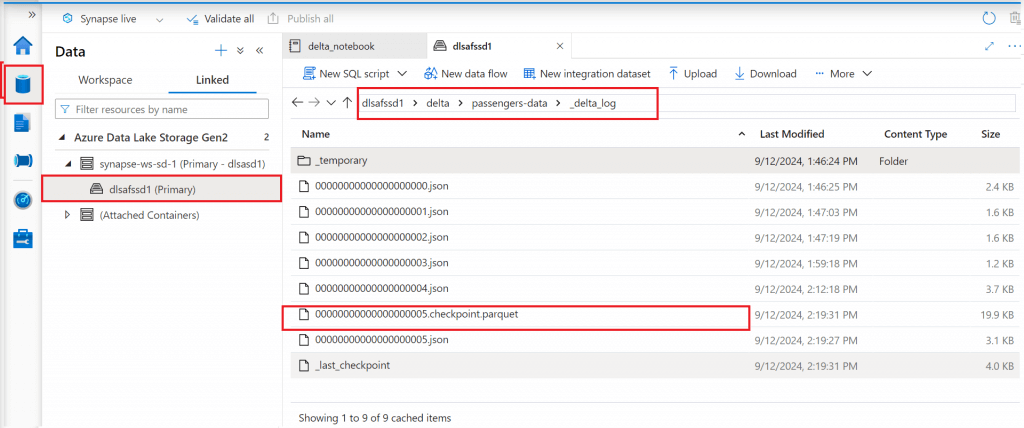
Use Schema Enforcement and Evolution
Every new write to a table is checked for compatibility with the schema of the target table at write time. If the schema is not compatible, the write does not happen. This feature is known as schema enforcement.
I create three dataframes in the code below from earlier versions of the delta table. In the first dataframe, the select statement schema is exactly matching with the existing schema. In the second dataframe, one column name is changed from camel-case to lower case. In the third dataframe, a new column named cons is added with an integer default value.
df_new1 = spark.sql("""
SELECT PassengerId, Survived, Pclass, Name, Gender, Age, SibSp, Parch, Ticket, Fare, Cabin, Embarked
FROM TestForDelta.passengersexternal VERSION AS OF 0
""")
df_new2 = spark.sql("""
SELECT PassengerId, Survived, Pclass, Name, Gender, Age, SibSp, Parch, Ticket, Fare, Cabin, embarked
FROM TestForDelta.passengersexternal VERSION AS OF 1
""")
df_new3 = spark.sql("""
SELECT PassengerId, Survived, Pclass, Name, Gender, Age, SibSp, Parch, Ticket, Fare, Cabin, Embarked, 3 AS cons
FROM TestForDelta.passengersexternal VERSION AS OF 2
""")Now I execute three write statements to load the dataframes in append mode to the delta table path in the code below. The first and second dataframes could be loaded to the delta table path as they match Schema enforcement rules. The third dataframe could not be loaded as the new column in the schema fails Schema enforcement.
df_new1.write.format("delta").mode("append").save(delta_table_path)
df_new2.write.format("delta").mode("append").save(delta_table_path)
#this command fails
df_new3.write.format("delta").mode("append").save(delta_table_path)
Schema evolution allows users to change a table's current schema to accommodate data that is changing over time. When performing an append or overwrite operation, the schema can be adapted automatically to include one or more new columns.
I can append a dataframe with a different schema to the Delta table by explicitly setting mergeSchema equal to true. The following code succeeds and data is available in the delta table.
df_new3.write.format("delta").mode("append").option("mergeSchema", "true").save(delta_table_path)I can also set the Spark property to enable autoMerge by default. Once this property is set, it is not needed to manually set mergeSchema to true when writing data with a different schema to a Delta table.
spark.conf.set("spark.databricks.delta.schema.autoMerge.enabled", "true")Improve Performance
For every change operation on the delta table, new parquet data files are written. As a result, many small data files are created which affect the performance of data operations on the table.
The Optimize command compacts multiple smaller parquet files into a larger parquet file. The larger parquet file helps in improved performance of data operation. The existing smaller data files are still remain in the folder location. Z-ordering used with Optimize command helps to co-locate related information in the same set of files. This behavior dramatically reduces the amount of data the Delta Lake needs to read for a data operation.
Before running Optimize command, the data file folder contains 9 data files reflecting the changes done so far on the delta table after creation.
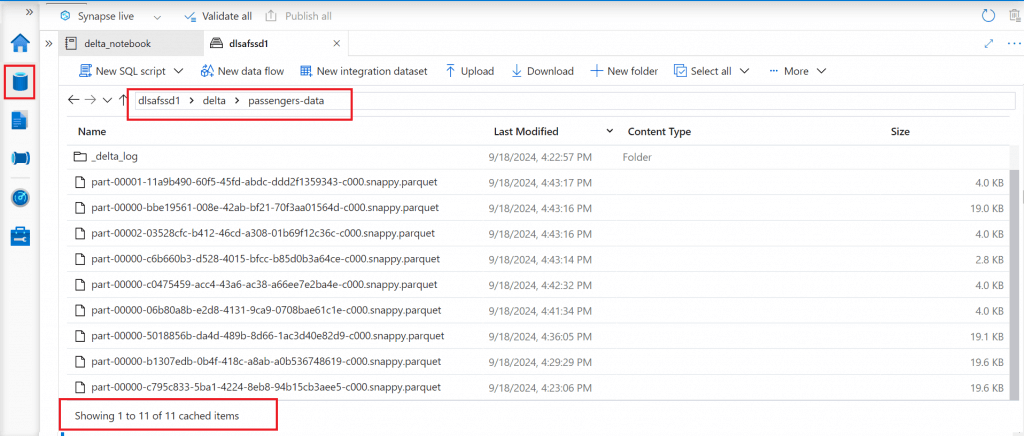
I execute the Optimize command.
%sql OPTIMIZE TestForDelta.passengersexternal ZORDER BY PassengerId
After successful execution, I check the data files again. There is a new data file created which combines the smaller data files in a larger one. But, the smaller files are still available in the folder. The Vacuum command can be used to clean the unused files.
The Vacuum command removes the previous versions of Delta Lake files and retains data history up to a specified period. It helps reduce the overall size of dataset by removing older unnecessary copies of data. By default, the older data is retained for 7 days. If Vacuum command is used to remove data not older than 7 days, the execution will fail. The settings need to be changed accordingly.
I try to execute the Vacuum command to remove all the older data. I get an exception initially. Then, I change the required settings and the command gets executed successfully.
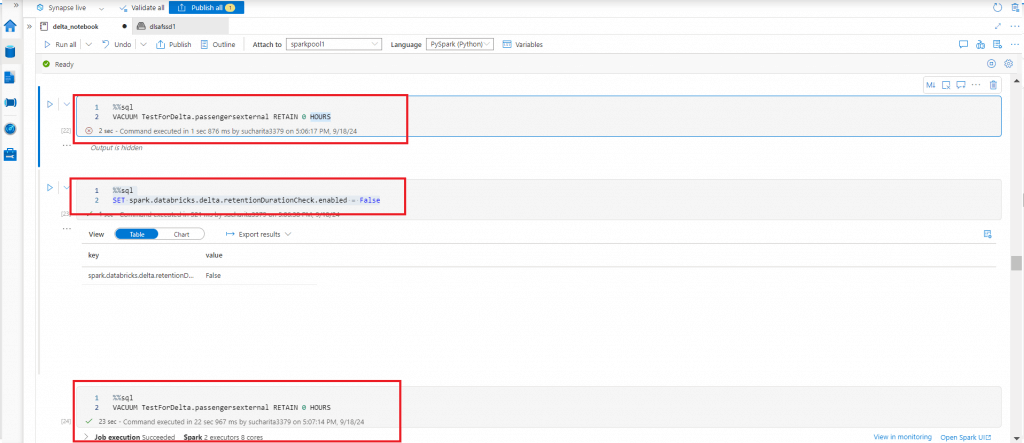
%sql SET spark.databricks.delta.retentionDurationCheck.enabled = False %sql VACUUM TestForDelta.passengersexternal RETAIN 0 HOURS
After the successful execution of the Vacuum command, I check the data files again. Now, the folder contains only the last larger data file created through Optimize command.
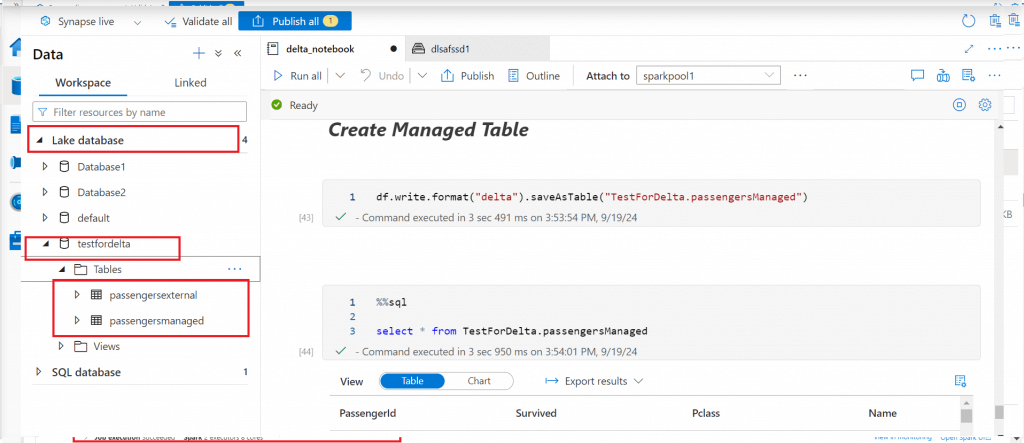
Create a Managed Table
Now I create a managed table from the original dataframe named df to show both the managed and external tables created from the dataframe in this example script.
df.write.format("delta").saveAsTable("TestForDelta.passengersManaged")
%%sql
select * from TestForDelta.passengersManagedBoth the managed and external tables are now available in testfordelta database under Lake Database section. The Describe extended statement on a table shows whether the table is an external table or a managed table.
Conclusion
In this level, I discussed population and retrieval of batch data in Delta Lake. The Delta Lake table can be used as Streaming source and sink as well. Delta Lake provides ACID (Atomicity, Consistency, Isolation, and Durability) transaction guarantees between reads and writes. Delta Lake uses optimistic concurrency control to provide transactional guarantees between writes. For reading, the snapshot of the last committed transaction is used. Change Data Feed (CDF) feature allows Delta tables to track row-level changes between versions. The delta table can be queried from Serverless SQL pool as well. In the next level, I will discuss these features of Delta Lake.
