Introduction
In Level 1 of this series, I discussed Synapse Analytics basics and the steps for creation of the Synapse Workspace. I had uploaded few files with different format (csv, tsv, json, and parquet) in the primary data lake container for the workspace.
In level 2, I will analyze data from the files uploaded in data lake container using Serverless SQL Pool. I will show the steps to create external table and lake database under the SQL Pool.
Serverless SQL Pool is a distributed data processing system of Azure Synapse Analytics. There is no infrastructure setup or cluster maintenance required for the working of this pool. Once the Synapse workspace is created, a default endpoint is provided for this pool to start querying data immediately from Azure storage. This pool is built for large scale data analytics with its various services and features.
Data Analysis Steps
I will explain the steps to use the Serverless SQL Pool to query data from the different files uploaded in the Data Lake Storage account. Also, I will create external table and lake database under the SQL Pool.
Step 1: Write a SELECT Query on the csv File
I select the CSV file in the Data section of Synapse Studio and click on Select Top 100 rows option in the New SQL Script dropdown. A new SQL Script is open with a SQL query written using OPENROWSET. The OPENROWSET function in Serverless SQL Pool helps to query external files present in Azure Storage. It supports three input types: CSV, PARQUET and DELTA.
I write the query in two ways. The first version of the query is executed in the default master database. I mention UTF8 collation for string columns in the WITH clause.
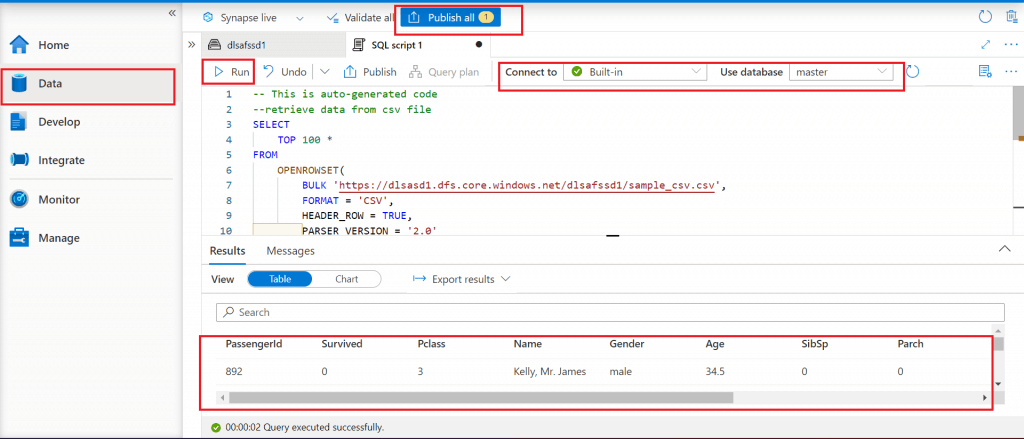
The SQL query is shown below. The query selects 100 records from the csv file using OPENROWSET function. The column names, data types and order of the columns are mentioned in the WITH clause. UTF8 collation is mentioned for all the columns with string data type.
--retrieve data from csv file
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK 'https://dlsasd1.dfs.core.windows.net/dlsafssd1/sample_csv.csv',
FORMAT = 'CSV',
HEADER_ROW = TRUE,
PARSER_VERSION = '2.0'
)
WITH (
PassengerIdINT 1,
SurvivedSMALLINT 2,
Pclass SMALLINT 3,
[Name] VARCHAR (100) COLLATE Latin1_General_100_BIN2_UTF8 4,
[Gender] VARCHAR (10) COLLATE Latin1_General_100_BIN2_UTF8 5,
AgeFLOAT 6,
SibSpSMALLINT 7,
ParchSMALLINT 8,
TicketVARCHAR (100) COLLATE Latin1_General_100_BIN2_UTF8 9,
FareFLOAT 10,
CabinVARCHAR (100) COLLATE Latin1_General_100_BIN2_UTF8 11,
Embarked CHAR(1) COLLATE Latin1_General_100_BIN2_UTF8 12
) AS [result]
In the second version, I create a database with collate option set as UTF8. Then, I write the query to execute in the newly created database. Here, UTF8 collation is not required to be mentioned for each string column.
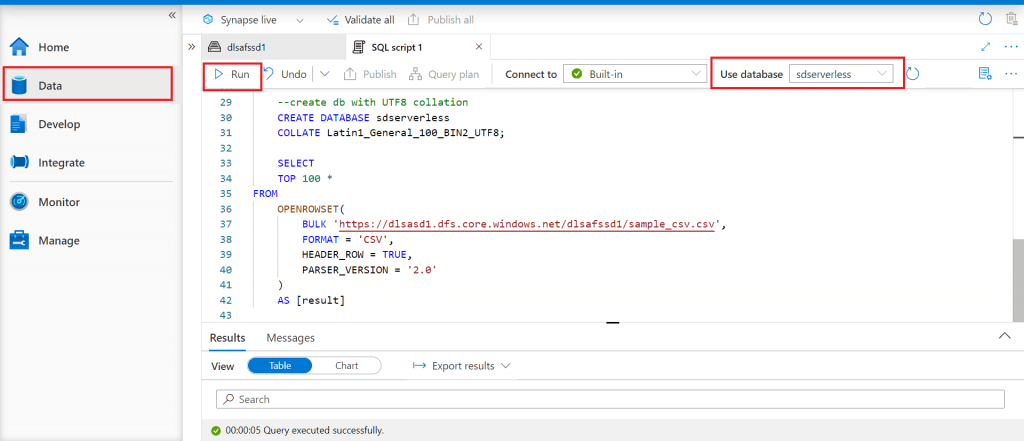
The SQL query is here. The query first creates a database named sdserverless with UTF8 collation, The select statement is written to retrieve the first 100 records from the csv file using OPENROWSET function. WITH clause is not used here as the database is already set with UTF8 collation. It is not required to mention UTF8 collation for the string columns.
----------------------------------------------------------------------
--create db with UTF8 collation
CREATE DATABASE sdserverless
COLLATE Latin1_General_100_BIN2_UTF8;
-- execute the Select statement in the database with UTF8 collation
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK 'https://dlsasd1.dfs.core.windows.net/dlsafssd1/sample_csv.csv',
FORMAT = 'CSV',
HEADER_ROW = TRUE,
PARSER_VERSION = '2.0'
)
AS [result]If the query is not written with UTF8 collation, it may fail due to collation issue.
Both the queries are executed and data is returned. Thus, the csv file present in the Data Lake can be queried directly from the Synapse SQL Pool without copying.
Step 2: Write SELECT Queries on tsv, JSON, and Parquet files
In the last step, I have written query to retrieve data from the csv file. There are other file types (tsv, parquet, and JSON) uploaded in the storage account. I will write queries to retrieve data from these files. The syntax varies for different file types. After execution, I publish the changes. The scripts get copied under SQL Scripts in the Develop section.
The SQL query to retrieve data from the JSON file is here:
-- This is auto-generated code
SELECT TOP 100
jsonContent
--> place the keys that you see in JSON documents in the WITH clause:
, JSON_VALUE (jsonContent, '$.date_rep') AS date_rep
, JSON_VALUE (jsonContent, '$.day') AS day
, JSON_VALUE (jsonContent, '$.month') AS month
, JSON_VALUE (jsonContent, '$.year') AS year
, JSON_VALUE (jsonContent, '$.cases') AS cases
, JSON_VALUE (jsonContent, '$.deaths') AS deaths
, JSON_VALUE (jsonContent, '$.geo_id') AS geo_id
FROM
OPENROWSET(
BULK 'https://dlsasd1.dfs.core.windows.net/dlsafssd1/sample2.json',
FORMAT = 'CSV',
FIELDQUOTE = '0x0b',
FIELDTERMINATOR ='0x0b',
ROWTERMINATOR = '0x0a'
)
WITH (
jsonContent varchar(MAX)
) AS [result]
The select query returns each document from the JSON file as a separate row. In the OPENROWSET function, format is mentioned as csv only. JSON_VALUE function is used to retrieve column wise data from each document.
The SQL query to retrieve data from the parquet file:
-- select data from PARQUET file
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK 'https://dlsasd1.dfs.core.windows.net/dlsafssd1/sample_parquet.parquet',
FORMAT = 'PARQUET'
)
WITH (
[column0] VARCHAR (50),
[column1] VARCHAR (50))
AS [result]The select statement uses OPENROWSET function to retrieve data from input file in parquet format. WITH clause can be used to read the specific columns from the file.
The SQL query to retrieve data from the .tsv file:
-- This is auto-generated code
-- select data from TSV file
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK 'https://dlsasd1.dfs.core.windows.net/dlsafssd1/sample_tsv.tsv',
FORMAT = 'CSV',
PARSER_VERSION = '2.0',
HEADER_ROW = TRUE,
FIELDTERMINATOR ='\t'
) AS [result]The select query is similar for data retrieval from csv file. The fieldterminator value is '\t' (tab) here.
Step 3: Create an External Table
An external table is an interface to query data present in the Storage from a Serverless SQL Pool database abstracting the connection to the data source. Let's create one.
External table creation has three steps:
- CREATE EXTERNAL FILE FORMAT
- CREATE EXTERNAL DATA SOURCE
- CREATE EXTERNAL TABLE
I go to Data Lake files in the Data Section of Synapse Studio. In the New SQL script dropdown, there is an option to create external table for csv, tsv and parquet files. External table creation is not available for JSON files. I select the csv file and click on the option to create external table. A new SQL script is generated.
The following SQL Script will create an external table from the csv file present in the Data Lake Container. The script has three parts:
- CREATE EXTERNAL FILE FORMAT: Creating an external file format is a prerequisite for creating an External Table. By creating an External File Format, the actual layout of the data referenced by an external table is specified.
- CREATE EXTERNAL DATA SOURCE: This is another prerequisite for creating an External table. The location of the data file is defined in this step.
- CREATE EXTERNAL TABLE: create external table statement is used to create the table. File format and data source created before this step are added in the WITH clause. The relative path of the input file in the data source is mentioned in the location parameter of the WITH clause.
-- creation of external table
-- CREATE EXTERNAL FILE FORMAT
IF NOT EXISTS (SELECT * FROM sys.external_file_formats WHERE name = 'SynapseDelimitedTextFormat')
CREATE EXTERNAL FILE FORMAT [SynapseDelimitedTextFormat]
WITH ( FORMAT_TYPE = DELIMITEDTEXT ,
FORMAT_OPTIONS (
FIELD_TERMINATOR = ',',
FIRST_ROW = 11,
USE_TYPE_DEFAULT = FALSE
))
GO
-- CREATE EXTERNAL DATA SOURCE
IF NOT EXISTS (SELECT * FROM sys.external_data_sources WHERE name = 'dlsafssd1_dlsasd1_dfs_core_windows_net')
CREATE EXTERNAL DATA SOURCE [dlsafssd1_dlsasd1_dfs_core_windows_net]
WITH (
LOCATION = 'abfss://dlsafssd1@dlsasd1.dfs.core.windows.net'
)
GO
-- CREATE EXTERNAL TABLE
CREATE EXTERNAL TABLE dbo.external_csv (
[PassengerId] bigint,
[Survived] bigint,
[Pclass] bigint,
[Name] nvarchar(4000),
[Gender] nvarchar(4000),
[Age] varchar(20) NULL,
[SibSp] VARCHAR(20),
[Parch] bigint,
[Ticket] nvarchar(4000),
[Fare] VARCHAR(20),
[Cabin] nvarchar(4000),
[Embarked] nvarchar(4000)
)
WITH (
LOCATION = 'sample_csv.csv',
DATA_SOURCE = [dlsafssd1_dlsasd1_dfs_core_windows_net],
FILE_FORMAT = [SynapseDelimitedTextFormat]
)
GO
-- Select data from the external table
SELECT TOP 100 * FROM dbo.external_csv
GO
-- drop the external table, if required
--DROP EXTERNAL TABLE dbo.external_csvStep 4: use CETAS statement
I will use CETAS statement (Create External Table As Select) to save the results of a SELECT statement to Azure Storage. CETAS Statement is particularly useful if it is required to transform source data and store as another file format such as from csv to parquet. There are few limitations of this approach. It is not possible to define a destination partition scheme, number of rows per file or the number of files created. These are done automatically.
In the below code block, parquet data files are created in the Data Lake container from the external table created from the csv file in the earlier step.
--use of CETAS Statement
--create the external file format
CREATE EXTERNAL FILE FORMAT SynapseParquetFormat
WITH (
FORMAT_TYPE = PARQUET
);
--CETAS statement
CREATE EXTERNAL TABLE dbo.external_parquet
WITH (
LOCATION = 'cetas_parquet.parquet',
DATA_SOURCE = [dlsafssd1_dlsasd1_dfs_core_windows_net],
FILE_FORMAT = SynapseParquetFormat
)
AS
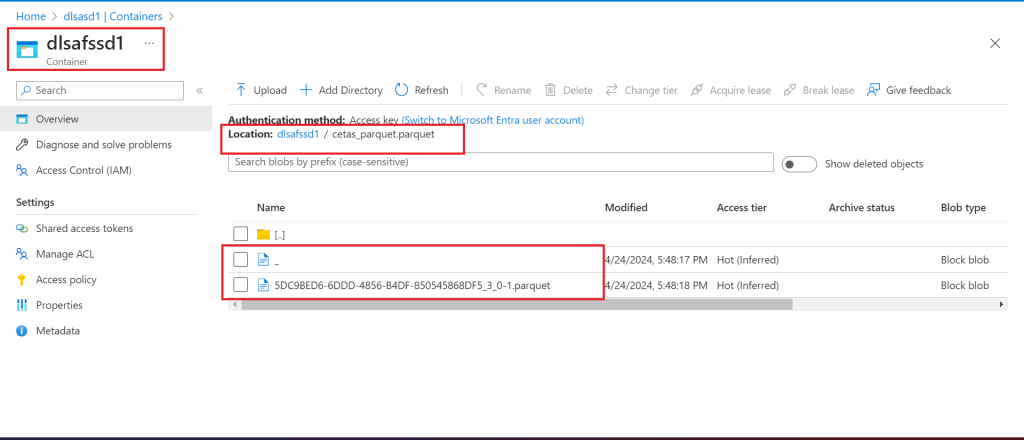
SELECT * FROM dbo.external_csvThe parquet files as available in the Data Lake container:
Step 5: Create a Lake Database
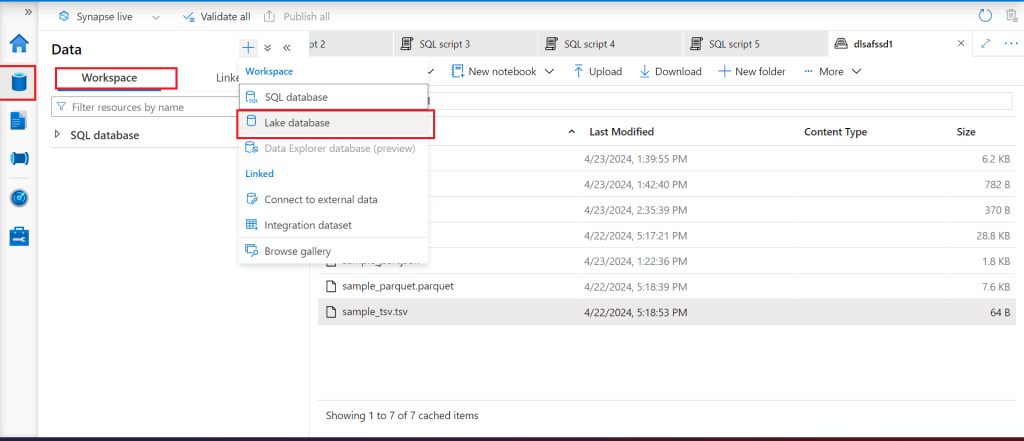
I go to the Workspace tab of Data section in Synapse Studio. Here, I start creating Lake database. The Lake Database can be used to define tables on top of data lake using Apache Spark notebooks, database templates, or Microsoft Dataverse. The lake database tables can be queried using T-SQL statement in the Serverless SQL Pool.
Lake databases use a Azure data lake to store the data. The data can be stored in Parquet, Delta or CSV format. Every lake database uses a linked service to define the location of the root data folder. For every entity, separate folders are created by default within this database folder on the data lake. Data loading can be done in the Lake database tables using pipelines. I will discuss pipelines in upcoming levels.
Step 6: Create a Table from a tsv File in the Lake Database
The Lake database, named Database1, is created. I open the database and start creating a table from Data lake. There is option to create the table from template and custom option as well. I provide the details of the tsv file in Data lake container to create the table.
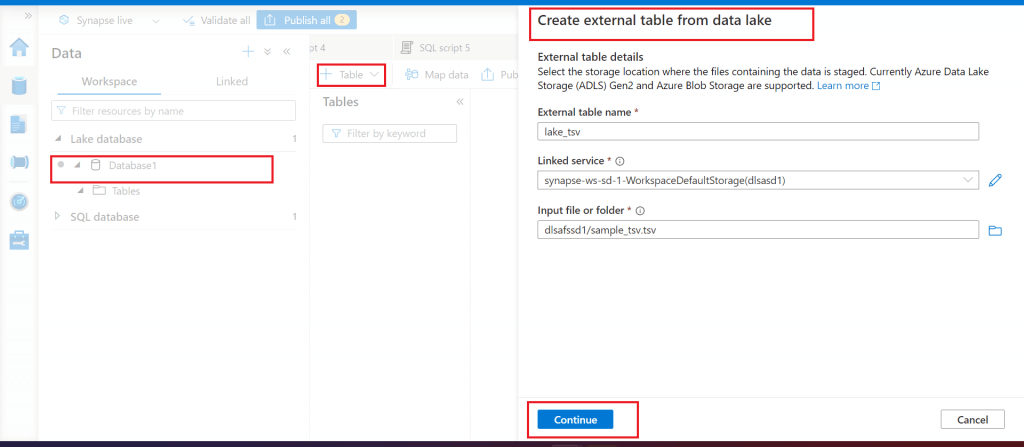
Step 7: Create a Table from a csv File in the Lake Database
I create another table from the csv file present in Data lake container. Table column details are available and editable in the Database designer. Relationship can be created on multiple tables present in the lake database.
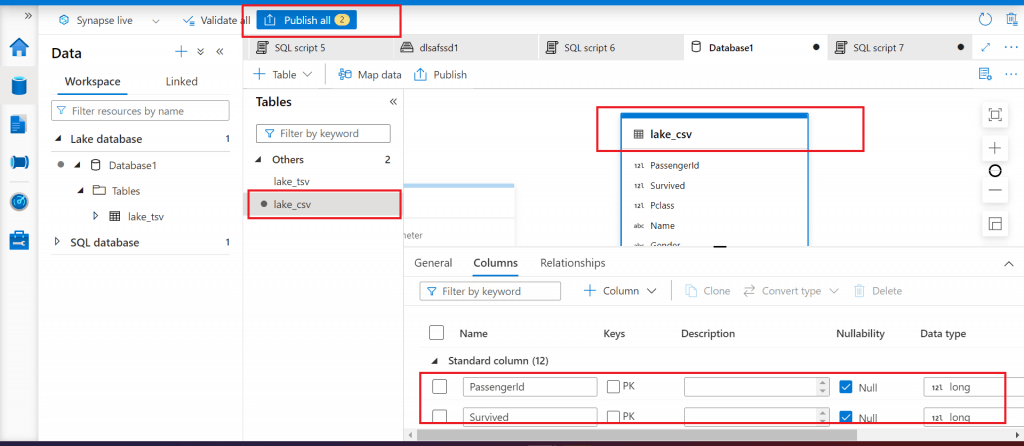
Step 8: Query the Lake Database Table
Lake database tables can be queried using SQL select statement, can be copied to a dataframe to be used in spark notebook or can be used in a machine learning model. Here yo can see a query run in the image.
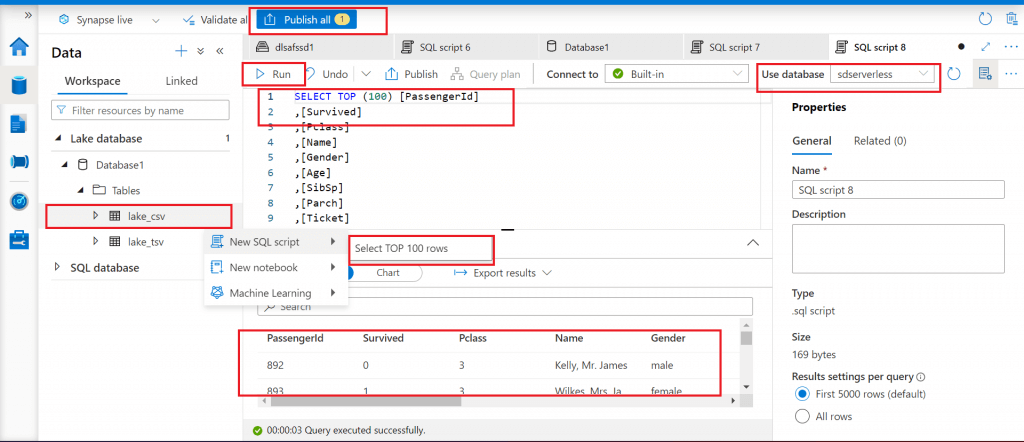
Conclusion
The Synapse workspace comes with the pre-configured pool called Built- in. By default, master database is used for data processing. A new database can be created in the pool to use for query processing. Cost for this service is based on the amount of data processed. The Serverless pool can be used to query data from Data Lake, Cosmos DB or Dataverse. It is possible to query multiple files from a specified folder. Nested JSON and Parquet files also can be queried. Other than external table, view and schema objects also can be created in the Serverless SQL Pool.
