Introduction
Azure Synapse Analytics is a PaaS resource. It provides a single, cloud-scale platform for different analytical workloads through support for multiple data storage, processing, and analysis technologies. A Synapse Analytics workspace is an instance of the Synapse Analytics service. The workspace helps in managing the services and data resources needed for the analytics solution.
Evolution of Synapse Analytics
Microsoft Analytics Platform System (APS) is a data platform designed for data warehousing and Big Data analytics. Analytics Platform System hosts SQL Server Parallel Data Warehouse (PDW), which runs the massively parallel processing (MPP) data warehouse. APS powers many on-premises data warehousing solutions.
Around 2016, Microsoft adapted its massively parallel processing (MPP) on-premises Data Warehouse to the cloud as “Azure SQL Data Warehouse”. Azure SQL DW adopted the constructs of Azure SQL DB such as a logical server where administration and networking are controlled. SQL DW could exist on the same server as other SQL databases.
In 2019, Azure Synapse Analytics was introduced. Dedicated SQL Pool (formerly SQL DW) is a component of Synapse Analytics now. Any existing Dedicated SQL Pool (SQL DW) can be migrated to Synapse Analytics. However, the SQL DW still resides on the same logical server. Microsoft provides separate documentation for Synapse Analytics and Dedicated SQL Pool.
MS Documentation Link: https://learn.microsoft.com/en-us/azure/synapse-analytics/
Detailed documentation on the history and evolution of Synapse Analytics Workspace: https://techcommunity.microsoft.com/t5/azure-synapse-analytics-blog/what-s-the-difference-between-azure-synapse-formerly-sql-dw-and/ba-p/3597772
About this Series
This series aims for the end-to-end understanding of the working of different analytics components of Synapse Analytics. The stairway series will cover the following topics:
- Create a synapse workspace
- Analyze data in storage account using serverless SQL pool
- Analyze data in storage account using serverless spark pool
- Analyze data in storage account using dedicated SQL pool
- Analyze data in storage account using Data Explorer pool
- Create and execute Synapse Pipeline
- Visualize Synapse data using Power BI
- Implement Synapse Link with Cosmos DB and SQL
- Create and use delta lake
Let us start with the creation and introduction of Synapse workspace.
Fabric and Synapse
Microsoft Fabrics is an end-to-end analytics solution having different service capabilities including data movement, data lake, data engineering, data integration, data science, real-time analytics, and business intelligence. It has a single storage layer, named OneLake. Fabric offers a broad range of data management and analytics capabilities whereas Synapse specializes in analytics and data warehousing solutions.
Fabric has some components similar to Synapse but with some significant feature differences.
- Fabric Data Warehouse --> Synapse Dedicated Pool
- Fabric Lakehouse --> Synapse Spark Pool
- Fabric Real Time Analytics --> Azure Data Explorer
- Fabric Data Science --> Synapse Data Science
Fabric is a SaaS resource. Fabric is generally available (GA) for purchase, but most of the features are still in preview. The following MS Documentation link can be referred for detailed information: https://learn.microsoft.com/en-us/fabric/get-started/whats-new
Create a Synapse Workspace
I will explain the step-by-step process to create the Synapse Workspace and upload files in the primary Data Lake Storage Account linked with the Synapse Workspace. Four types of supported files (CSV, TSV, Parquet and JSON) will be uploaded. Synapse Studio and its different components will be discussed as well.
Step 1: Create a Synapse Analytics resource
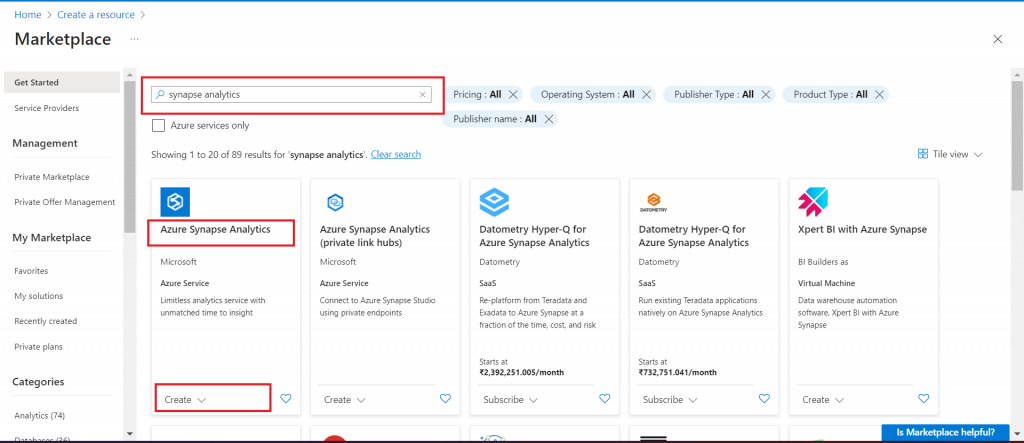
Go to Azure Portal and select the link to Create a resource. Search for the term 'synapse analytics'. Select the Azure Synapse Analytics Azure service and click on the Create button.
Step 2: Provide details for Workspace creation
In the next screen, fill in the required details. A Data Lake Storage Gen2 account is required. I select the option to create a new account. Then, I provide the Account name and the File system name. I select the checkbox to assign the required permission for the Storage account.
It is possible to use any existing Data Lake Storage Account as well. Any existing container can be selected or a new container can be created. The users should have adequate permission in the Data Lake Storage Account Container to ingest and retrieve data files.
Storage Blob Data Contributor role at the level of a container grants read, write, and delete access to all the blobs in that container.

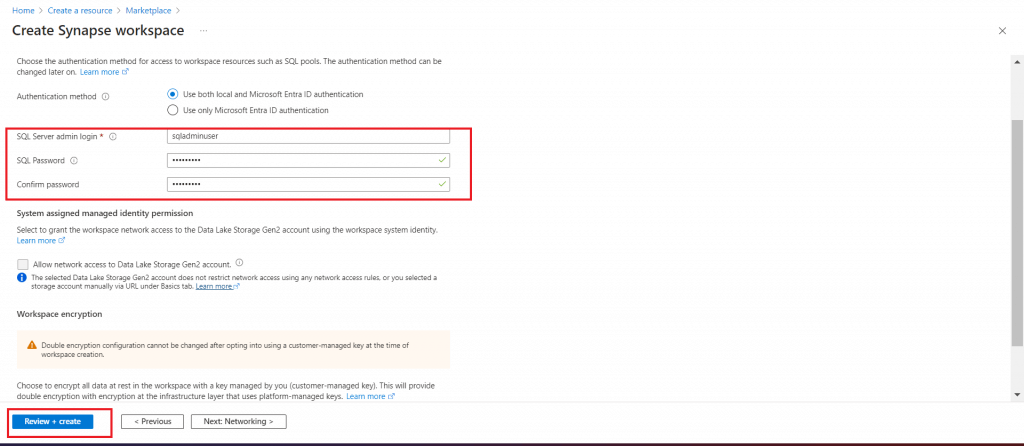
Step 3: Provide SQL login details
In the Security tab, I need to provide the SQL Server admin login and password. This authentication information will be required to use the dedicated SQL pool later. I keep rest of the field values with the default options and press the Review+Create button. The Synapse workspace will now be created.
Step 4: Upload csv file in Data Lake Container
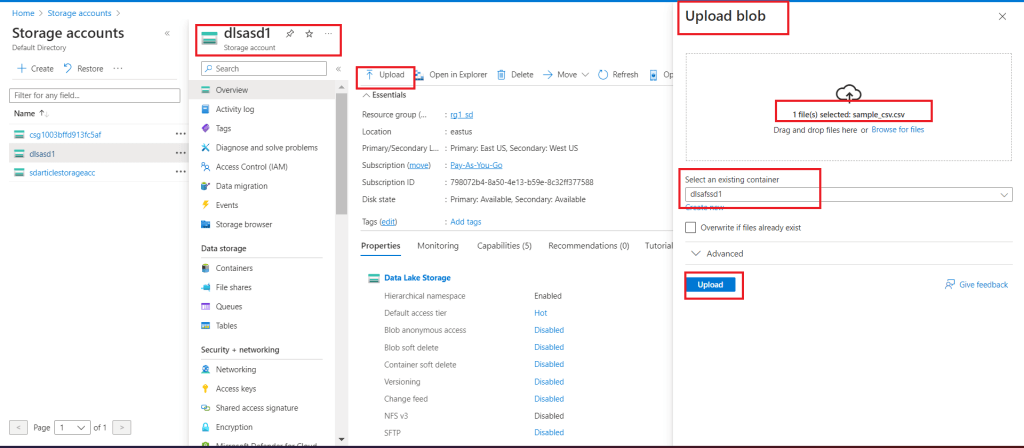
Once the Synapse workspace deployment is completed, I select the Data Lake Storage account attached with Synapse workspace. I go to the Overview page and press the Upload button. A pop-up window opens. I upload a csv file in the Container as selected during Synapse Workspace creation. I press the Upload button to complete the upload.
Step 5: Upload tsv, parquet and json files in Data Lake Container
I upload three other files (.tsv, .parquet and .json) in the same container. All the four files are now available in the Data lake storage account container linked with the Synapse workspace.

Step 6: Visit Synapse Analytics Overview page and go to Synapse Studio
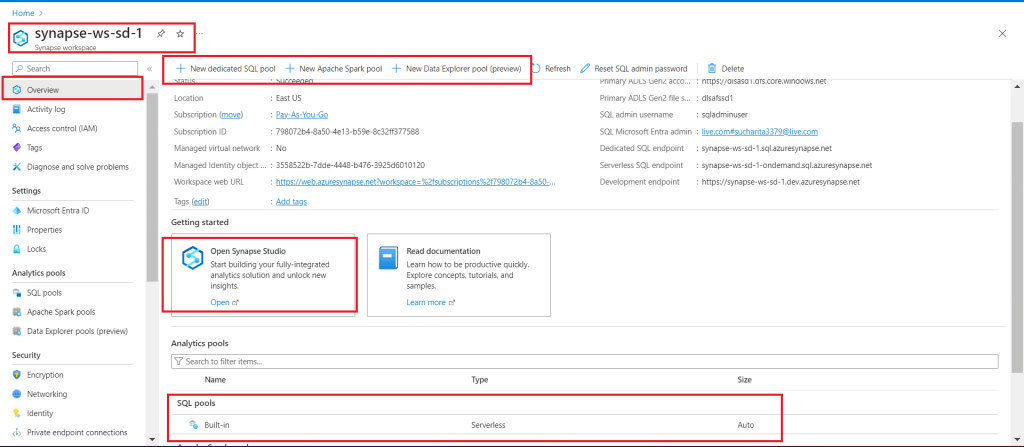
I select the Synapse workspace. Then I go to the Overview page. At the top bar, links are provided to create different types of pools (dedicated SQL pool, Spark pool and Data Explorer Pool) for data processing. I will discuss the creation and use of different types of pools in detail in the coming episodes of the Stairway series.
The built-in Serverless SQL Pool is available for immediate data processing. I will use the Serverless SQL Pool to process the input files present in Data lake in the next article.
Synapse Studio is a workspace for data management, preparation, exploration, and analytics. I click on the Open Synapse Studio link.
Step 7: Overview of Data tab in Synapse Studio
In the Synapse Studio, I go to the Data section. The Linked tab lists the primary Data lake storage account created at the time of creation of the Synapse workspace. Once the container is selected, all the four files uploaded are displayed. Different types of pools can be used to query data from these input files.
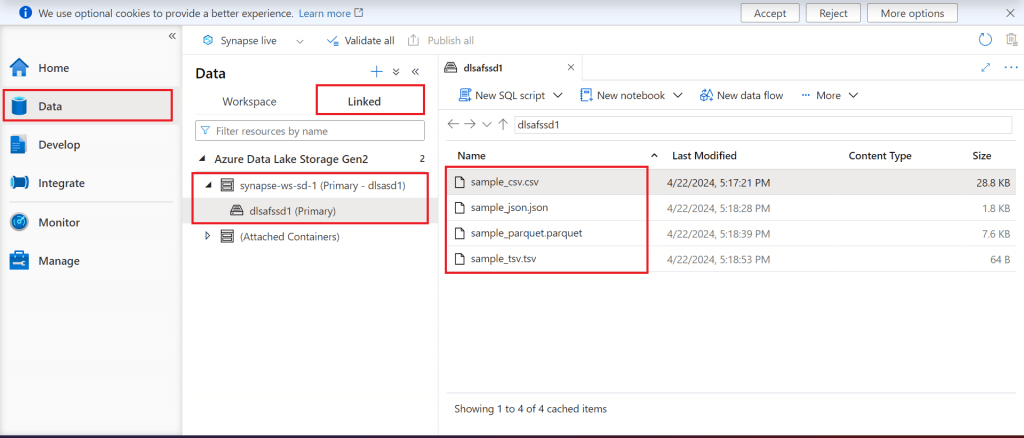
Step 8: Overview of Develop tab in Synapse Studio
I go to the Develop section. Here, I can create script, notebook, data flow and spark job for data processing. I will discuss some of them during this series.
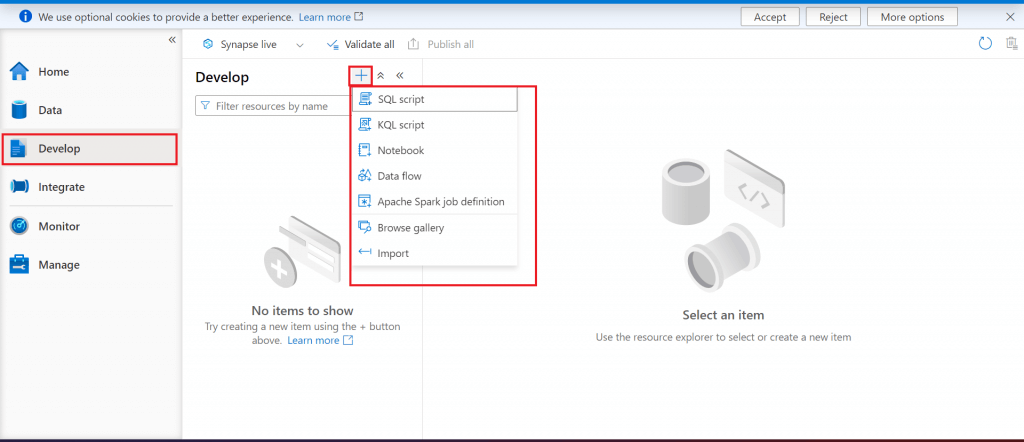
Step 9: Overview of Integrate tab in Synapse Studio
I go to the Integrate section. Here, I can create pipelines. I will discuss in detail during the series.
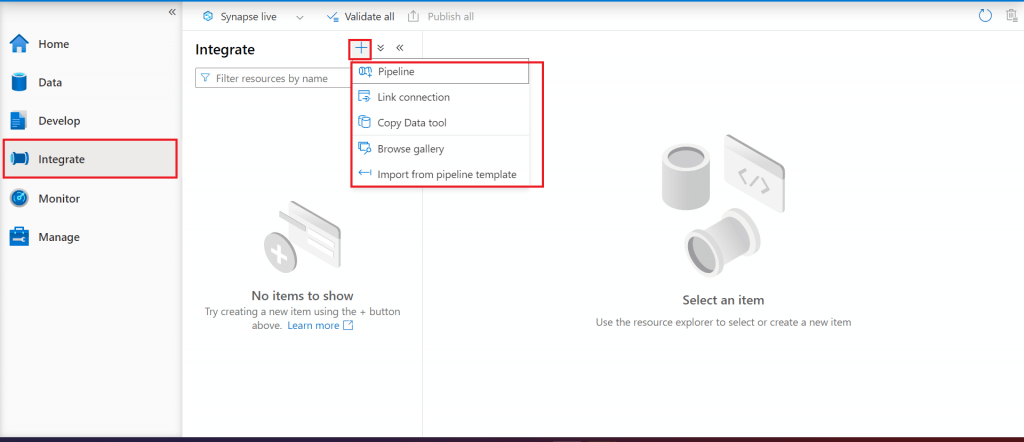
Step 10: Overview of Monitor tab in Synapse Studio
I go to the Monitor section. This page is used for monitoring the different pools and activities and the status for pipeline runs and trigger runs. As the different pools and activities will be explored in this series, monitoring will be done accordingly.
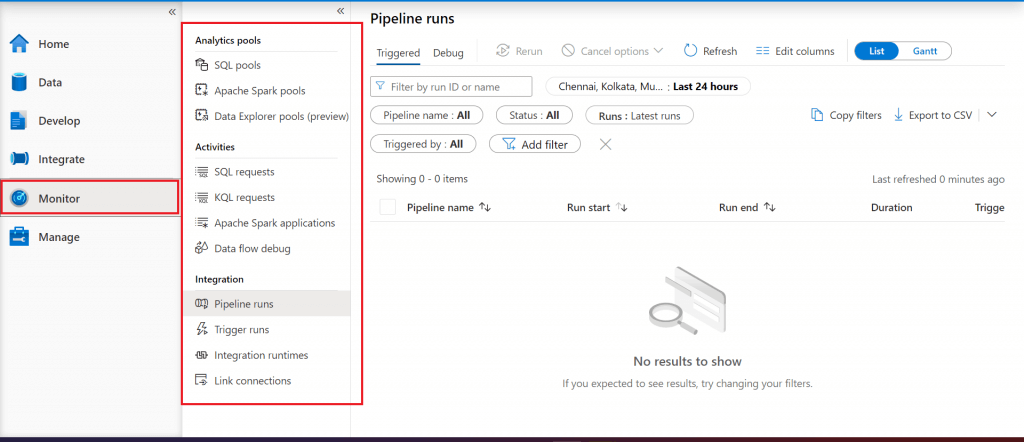
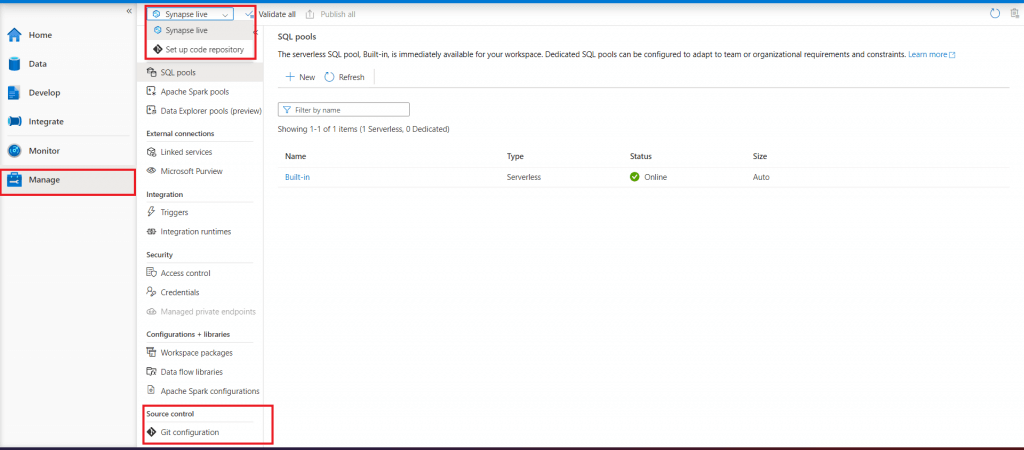
Step 11: Overview of Manage tab in Synapse Studio
The last one is the Manage section. Various components of Synapse Studio can be managed from here. Git Configuration for CI/CD Implementation can be done from here. At the top left, there is a drop-down to select the option to either work directly in Synapse or integrate the changes with the Git Repository.
Conclusion
Azure Synapse Analytics can be considered for various workloads including Large-scale data warehousing, Advanced analytics, Data exploration and discovery, Real time analytics, Data integration, Integrated analytics. SQL Pool, Spark Pool and Data Explorer pool help in batch and real time data processing. Integration with Azure ML helps in machine learning model implementation on synapse data. Integration of Power BI workspace with Synapse helps in seamless generation of datasets and reports. It is possible to query Cosmos DB using Synapse pools via Synapse link. All these feature make Synapse Analytics a very significant choice for any Data Analytics solution.
