

Join Operations - Nested Loops
Microsoft has provided three join operations for use in SQL Server. These operations are Nested Loops, Hash Match and Merge Join. Each of these provides different benefits and depending on the workload can be a better choice than the other two for a given query. The optimizer will choose the most efficient of these based on the conditions of the query and the underlying schema and indexes involved in the query. This article is the first of three in a series to explore these three Join Operations.
Nested Loops
The Nested Loops operation is sometimes referred to as the Nested Iteration. This is a join condition where there is an inner table that is looped through to meet the query criteria and compare it to each row of the outer table. A Nested Loop may be used for any of the following logical operations: inner join, left outer join, left semi-join, left anti-semi-join, cross apply, outer apply and cross join. It supports all join predicates.
In a Graphical Execution Plan, the Nested Loops Operator looks like the following image.

When using the "set statistics profile" option, you will notice that the Nested Loops will appear in your results as shown in the following image.

In Action
How can we see the Nested Loops join in action? Let's do a little setup to demonstrate the Nested Loops join. First let's create a couple of tables and then populate those tables with the following scripts.
SELECT TOP 10000 OrderID = IDENTITY(INT,1,1), OrderAmt = CAST(ABS(CHECKSUM(NEWID()))%10000 /100.0 AS MONEY), OrderDate = CAST(RAND(CHECKSUM(NEWID()))*3653.0+36524.0 AS DATETIME) INTO dbo.Orders FROM Master.dbo.SysColumns t1, Master.dbo.SysColumns t2 go CREATE TABLE [dbo].[OrderDetail]( [OrderID] [int] NOT NULL, [OrderDetailID] [int] NOT NULL, [PartAmt] [money] NULL, [PartID] [int] NULL) ; Insert Into OrderDetail (OrderID,OrderDetailID,PartAmt,PartID) Select OrderID, OrderDetailID = 1, PartAmt = OrderAmt / 2, PartID = ABS(CHECKSUM(NEWID()))%1000+1 FROM Orders
As you can see, I have created two tables for this simple example. Neither table has an Index or a Primary Key at this point. Let's run a query against these tables and see the results.
Select O.OrderId, OD.OrderDetailID, O.OrderAmt, OD.PartAmt, OD.PartID, O.OrderDate From Orders O Inner Join OrderDetail OD On O.OrderID = OD.OrderID
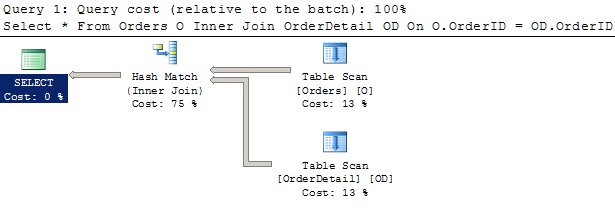
Here, we see that the query results in a Hash Match at this point. I could force a Nested Loops if I were to use a query option such as shown in the following query.
Select O.OrderId, OD.OrderDetailID, O.OrderAmt, OD.PartAmt, OD.PartID, O.OrderDate From Orders O Inner Join OrderDetail OD On O.OrderID = OD.OrderID -- This is a hash match for this example Option (loop join) --force a loop join
This will provide us with a Nested Loops Join by forcing the optimizer to use one. However, this is not recommended unless you know for certain that the Nested Loops Join is better in this case. The optimizer takes into account the number of records as well as the indexes involved in the query.
Let's take it a step further now. I will put some Primary Keys (with Clustered Indexes on the Primary Keys) on the tables and then I will run the same query again and check the results again.
ALTER TABLE dbo.Orders ADD PRIMARY KEY CLUSTERED (OrderID) ALTER TABLE dbo.OrderDetail ADD PRIMARY KEY CLUSTERED (OrderID,OrderDetailID)
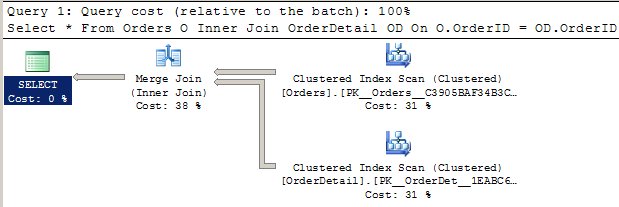
As can be seen we now have a Merge Join. This Merge Join is happening due to the large number of records in both tables (relatively). The optimizer has chosen this operation as the fastest method to achieve the results. Notice that the execution plan now performs CI scans on both tables. Previously, we saw that the optimizer had performed table scans on both tables. (Note: A CI scan is essentially a table scan. The use of a Clustered Index scan here is merely to denote the subtle difference in the graphical execution plan.) We also see that relative cost has shifted somewhat from the Join Operator to the Index Scans.
I will now take this one step further. I will now change the query ever so slightly and you will see that we will get a Nested Loops Operator in place of the Merge Join.
Select O.OrderId, OD.OrderDetailID, O.OrderAmt, OD.PartAmt, OD.PartID, O.OrderDate From Orders O Inner Join OrderDetail OD On O.OrderID = OD.OrderID Where O.OrderID < 10
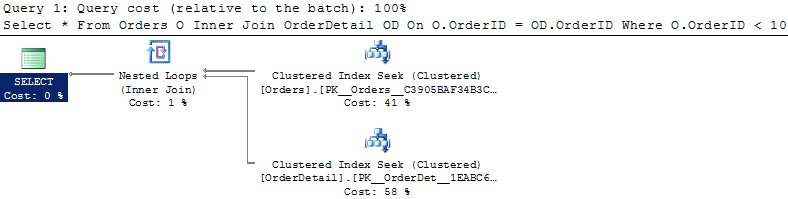
The change employed is to reduce the result set from one of the tables. In this case, I chose to return all records from both tables where Orders.OrderID was less than 10. With indexes being placed on the Join columns and the Orders. Orderid having a condition on it, we now reduce the number of operations and we also reduce the IO required to perform this query. This correlates with the following statement from MSDN:
If one join input is small (fewer than 10 rows) and the other join input is fairly large and indexed on its join columns, an index nested loops join is the fastest join operation because they require the least I/O and the fewest comparisons. http://msdn.microsoft.com/en-us/library/ms191426.aspx
Let's evaluate that from another perspective. Let's take a look at the IO statistics and execution time for the Merge Join and Hash Match in comparison to the Nested Loops, as shown to this point with the progression of the queries. (This may not be a fair comparison at the moment. I intend this more of a demonstration for this example as the query became more optimized.) As a reminder, this applies specifically to only this particular example.
| Merge Join | Hash Match | Nested Loops | |
|---|---|---|---|
| OrderDetail Physical Reads | 0 | 0 | 0 |
| OrderDetail Logical Reads | 38 | 37 | 18 |
| Orders Physical Reads | 0 | 0 | 0 |
| Orders Logical Reads | 38 | 37 | 2 |
| Elapsed Time | 604 ms | 775 ms | 261 ms |
From this we see that the logical reads on both tables and the Elapsed Time decrease substantially. In this case, we have fewer records and are using the indexes to query for the result set. Referring back to the Execution Plan, one sees that we are using Clustered Index seeks. In this example that I am using to this point, I only have a 1 to 1 relationship in the table, though I could have a 1 to many. I need to add a few more records to create a result set indicative of a one-to-many relationship. This is done through the following script.
Insert into OrderDetail (OrderID,OrderDetailID,PartAmt,PartID) Select OrderID, OrderDetailID = 2, PartAmt = OrderAmt / 2, PartID = ABS(CHECKSUM(NEWID()))%1000+1 FROM Orders
Now I will re-run those stat comparisons. For brevity I will just compare the Merge Join and the Nested Loops Join.
| Merge Join | Nested Loops | |
|---|---|---|
| OrderDetail Physical Reads | 0 | 0 |
| OrderDetail Logical Reads | 74 | 18 |
| Orders Physical Reads | 0 | 0 |
| Orders Logical Reads | 38 | 2 |
| Elapsed Time | 851 ms | 1 ms |
This further demonstrates how the Nested Loops is a better fit in this particular query. Due to the indexes and the where condition, the query optimizer can use a Nested Loops and the performance will be better. But what if I use a query hint and force the Merge Join query to become a nested loops join, how will that affect the outcome?
| Merge Join forced to Loops join via query hint | Nested Loops | |
|---|---|---|
| OrderDetail Physical Reads | 0 | 0 |
| OrderDetail Logical Reads | 21374 | 18 |
| Orders Physical Reads | 0 | 0 |
| Orders Logical Reads | 38 | 2 |
| Elapsed Time | 473 ms | 1 ms |
By trying to force the optimizer to use a Nested Loops where the query didn't really warrant it, we did not improve the query and it could be argued that we caused more work to be performed.
Conclusion
The Nested Loops join is a physical operator that the optimizer employs based on query conditions. The Nested Loops can be seen in a graphical execution plan and can be employed when one of these logical joins is used: inner join, left outer join, left semi join, and left anti semi join. The Nested Loops Join is also more likely to be the choice of the optimizer when one table has fewer records (e.g. <=10) and there are good indexes on the join columns in the query.


