

This is Chapter 8 of my Data Mining articles. If you want to see the earlier chapters, you can read the previous articles in this series using the links below:
- An introduction to data mining
- Decision trees
- Clusters
- Naïve Bayes
- Neural Network
- Time series
- Microsoft Association
The Sequence Cluster is similar and related to the Microsoft Association algorithm, but it includes sequences of events in a specific order. Sequence cluster is very popular when used to analyze the steps in a Web Site. We can analyze what the path used by the customers and optimize it. For example, if the customer goes to the "about us" page in a website, this model can predict which will be the next page they visit. The algorithm can predict the sequence of steps.
The other typical example is the market basket. In a supermarket we analyze the order of the products and optimize the position of the products to increase the sales. In this sample we will create the data mining model and then we will specify a product. The model will return the other products that the customer may buy in a specific order.
Getting Started
As we did in earlier chapters, we are going to work with the AdventureWorks Database. If you are not familiar with it, refer to the earlier chapters. I am working with SQL 2012, but you can use earlier versions.
In order to create the Model In the SQL Server Data Tools. In an Analysis Services project go to the Solution Explorer pane and in the Mining Structure folder right click and select the New Mining Structure option.
The famous Data Mining Wizard will be displayed. Click Next.
We are going to create the model from an existing relation database.
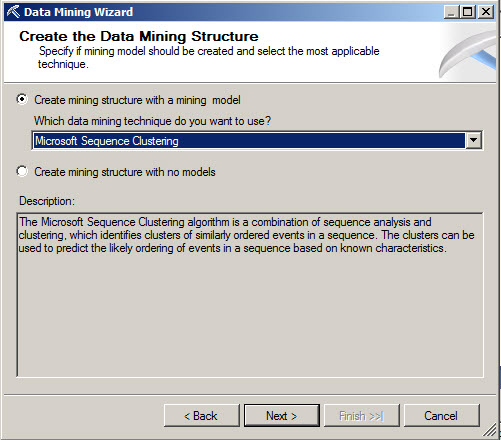
In this chapter we are learning the Microsoft Sequence Clustering mining technique.
The Data Source that we are going to use is the Adventure Works DW.
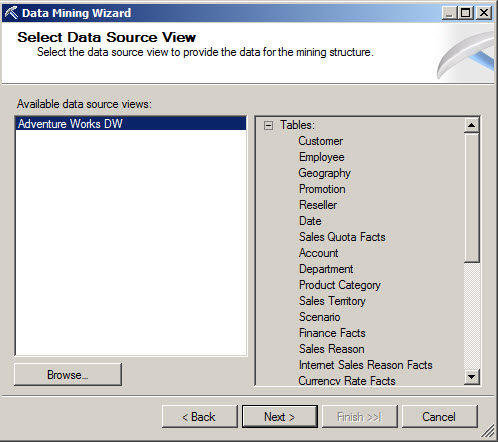
We now need to specify the Type of Tables. In this case, we are going to work with the tablesVAssocSeqLineItems, which contains the items to be sold and the table VAssocSecOrders contains the sequence of Orders. We are going to select the table of Line Items as nested and the case are the orders. The Nested table contains the variables to be evaluated and the case table contains the products to analyze.
For example, in the Adventure works we will analyze the sales orders contained in the case table. The nested table will be used as an input parameter to analyze the products. For example, the touring tire product can be analyzed to detect which products are related to it. In other words, the nested table contains the products to analyze in the sequence and the case table contains the sequences.
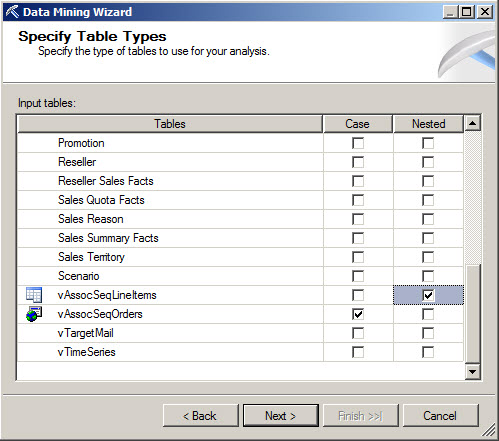
In the Window to Specify the Training Data you chose the key, the Inputs and the Predict column. We want to predict the sequence of products, the product name is contained in the model column. As an input we will use the IncomeGroup (high income, low and moderate).
The Region can be North America, Europe or Pacific. They are columns to analyze sequence per Income and region.
The LineNumber and Model are used as input as well. We will use the OrderNumber and LineNumber as Keys.
Once selected all the columns and keys, press next.
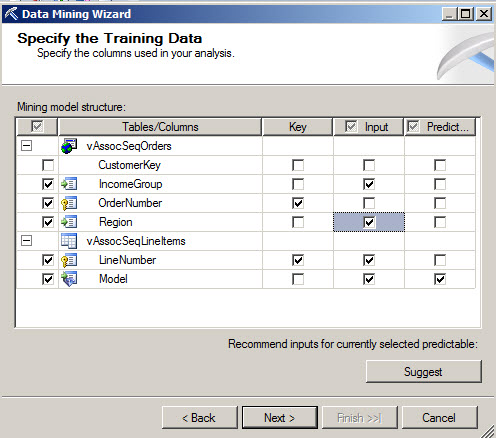
We use a percentage to test the model. By default is 30 %. Press next.
We can specify the structure and model name. Also enable the Allow drill through. Finally, press Finish.
Once done, go to the Mining Model Viewer. You will be prompt a message to deploy the project. Press Yes.
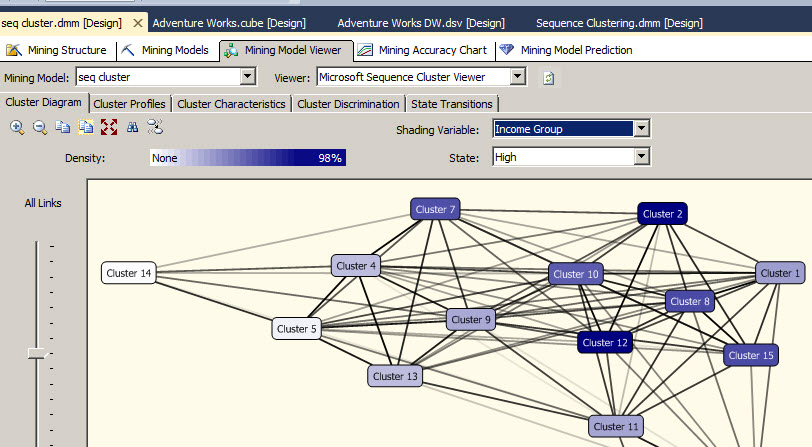
I am not going to give the details of the steps to process the model. You can refer to the previous chapter for the details to process the model. Once it is done, you will be able to see the nodes in sequences. The Cluster diagram is similar than the cluster algorithm. It shows different nodes according to different characteristics. The color of the nodes shows which one is more populated.
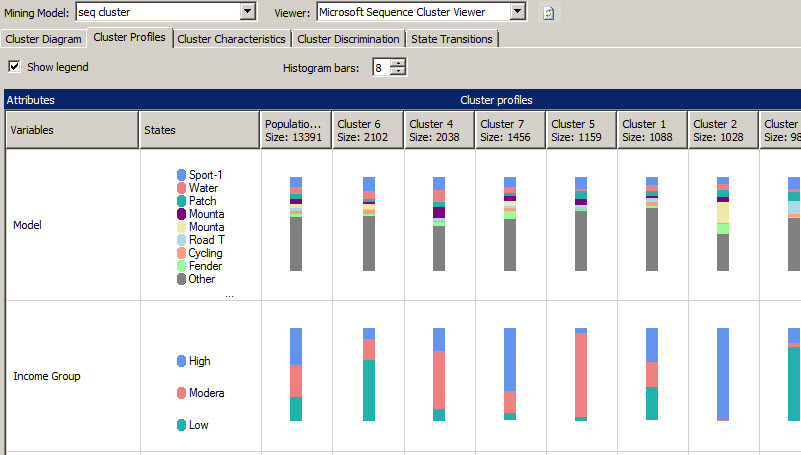
The cluster profile tab shows the population of each node according to the model, income groups and regions. You can watch in the diagram the population according to the characteristics.
As you can see there are many product with the model Sport-1 and many people with high incomes.
In the cluster characteristics you can see the probability according to the characteristics. You can analyze each node and notice the main characteristics. For example, the Cluster 1 belongs mainly to a group of people from the Pacific Region with High incomes. It also shows the main transitions in this node (Road-750, Road 550-W and Road 350-W.
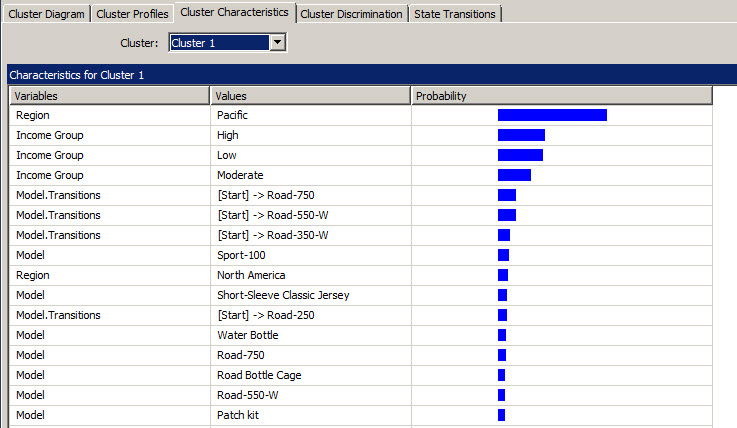
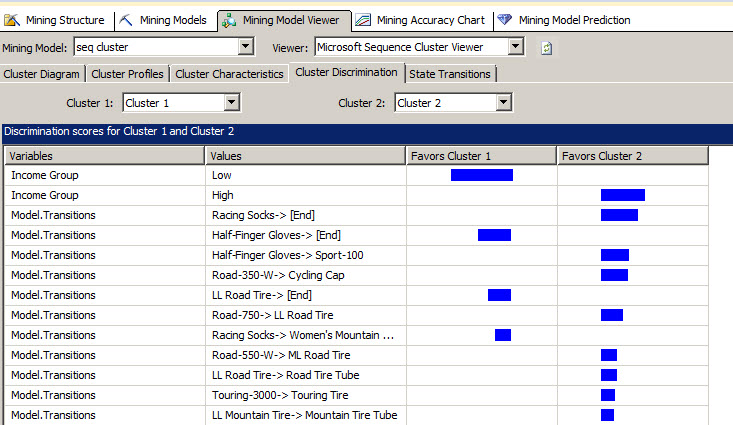
The cluster discrimination, is used to compare different cluster and verify the main differences and contrasts.
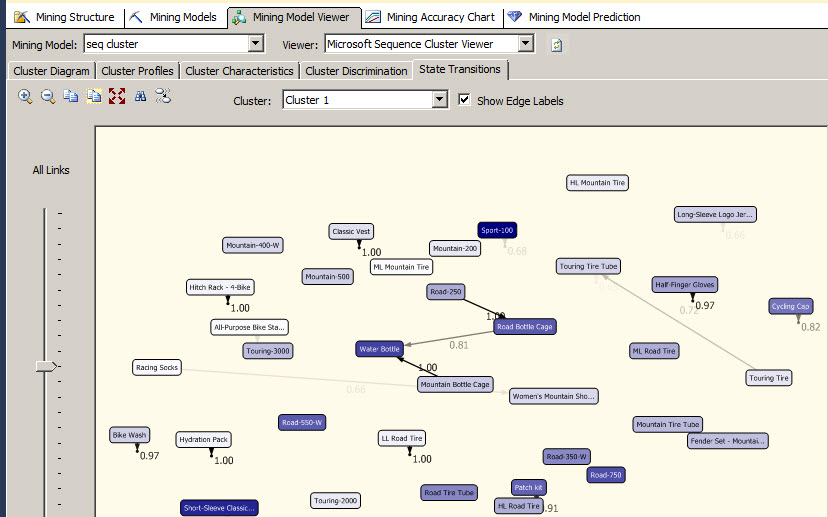
The state transition is the node that makes the difference between a Cluster and a Sequence Cluster. It shows the sequences between products. For example, The Road 250 product is related to the Road Bottle cage and if you buy the Road Bottle cage you will buy the water bottle next.
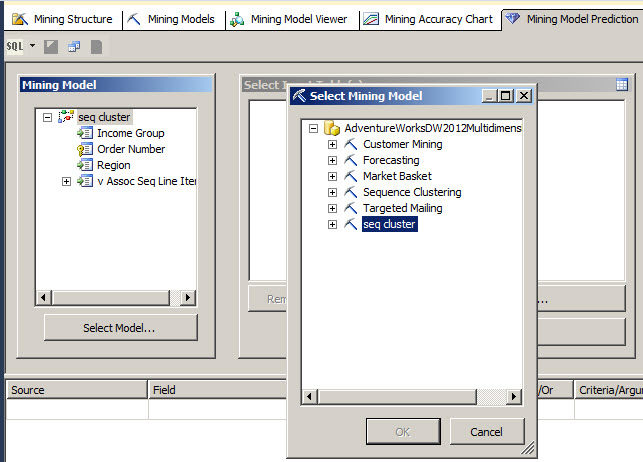
Now let's use the model select the sec cluster model using the Select Model button.
Right click on the select Input and select the Singleton Query.
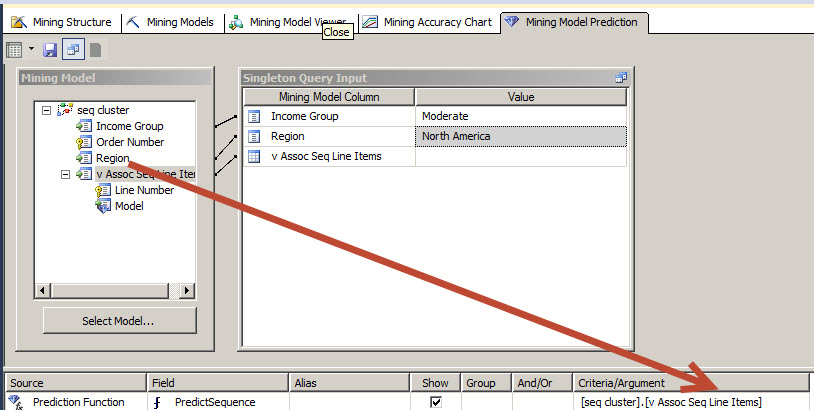
In the source, select The Prediction Function, in the Field select "Predict Sequence". Finally drag and drop the v Assoc Seq Line Items to the Criteria/Argument Field.
In the Criteria/Argument Field you can specify the number of rows to be display in the sequence. In this example we are going to select a sequence of 3.
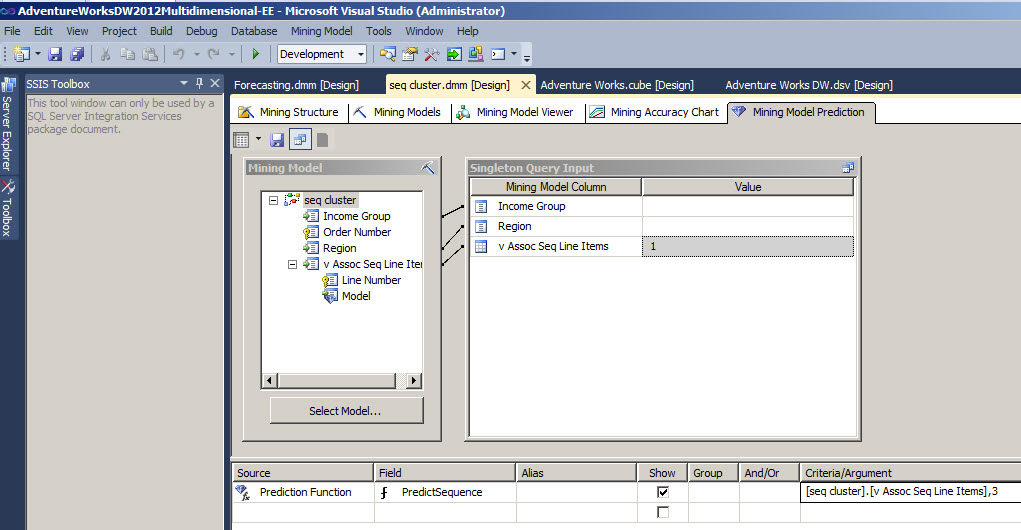
Once you have the results you now have the sequence of items related to the item selected. In this case, the touring tire tube, The Sport-100, the road bottle cage.
Press the ellipsis button in the Value of the v Assoc Seq Line Items.
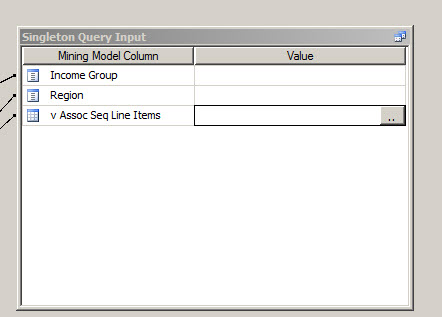
Press the Add button to add the product that you want to analyze and press OK. In this case Touring Tire. We are going to verify which product will the customer who buys a Turing Tire will buy after and in which order.
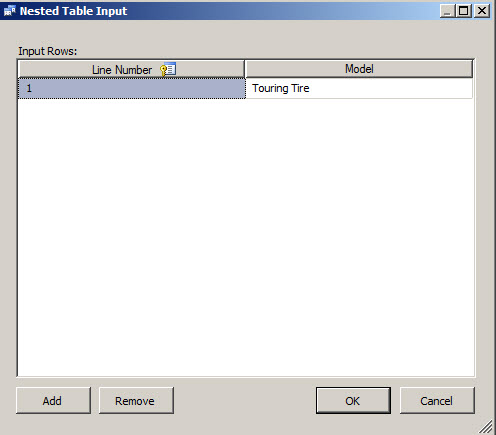
Now check the results. You will see the list of products related to the Touring Tire in a sequence:
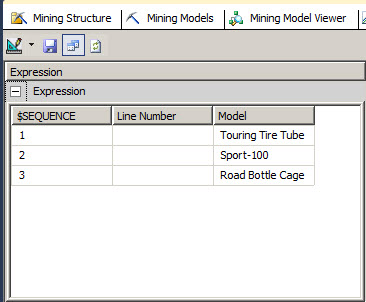
This result shows that the people who buys the Touring Tire, they also buy the Touring Tire Tube and the Sport-100 and finally they buy the Road Bottle Cage. Everything in that order. With that information the expert in marketing can offer in the web page the products related and increase sales.
In this chapter we learned how to create a Microsoft Sequence Cluster Model. We send a product to the model and the model predicted 3 possible products related in a specific order.
References