

This is Chapter 10 of my Data Mining articles. If you want to see the earlier chapters, you can read the previous articles in this series using the links below:
- An introduction to data mining
- Decision trees
- Clusters
- Naïve Bayes
- Neural Network
- Time series
- Microsoft Association
- Microsoft Sequence Cluster
- Linear Regression
This is the last Data Mining Algorithm. It is similar in the application and in the creation to the Neural Networks. The algorithm is similar in many aspects to the neural network, but it is faster and simpler. This is used to increase the performance to get the results when there is a large amount of data.
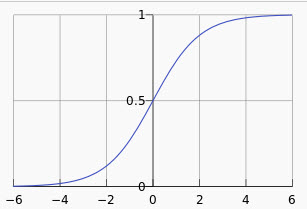
The algorithm is more complex than the linear regression, but it is a simple formula (if you like maths) to represent a model. It is common to use this algorithm to detect binary values (0 or 1) according to a limited number of variables. For example, the probability of dying of cancer or the probability of a customer to buy a product.
In this chapter, we will create the Adventure Work sample used in other lessons like the neural network and the cluster algorithm.
Getting Started
We are going to work with the AdventureWorks sample. If you are not familiar with the AdventureWorks project, you can check other lessons like the first one. In this sample, we are going to see the probability to buy or not an AdventureWorks bike based in the information provided by the table vTargetmail.
We will have information about the customer like the age, number of children, number of cars, education and we will determine if the customer will buy or not a bike. The value to buy bikes is 1 and 0 if the customer will not buy a bike.
1. In the Solution Explorer, create a New Mining Structure.
2. In the Welcome Window, press Next.
3. In the select the Definition Method, select the From existing relational database option.
4. In the Select Data Source View Window, select the Adventure Works.
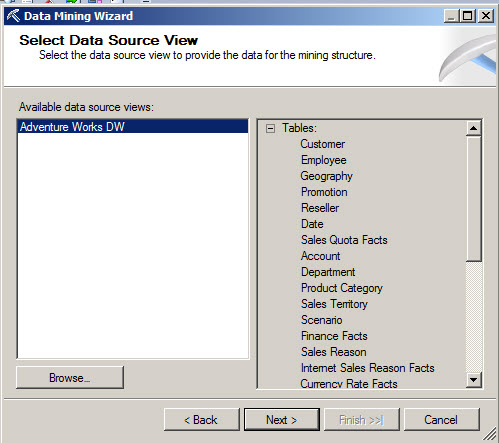
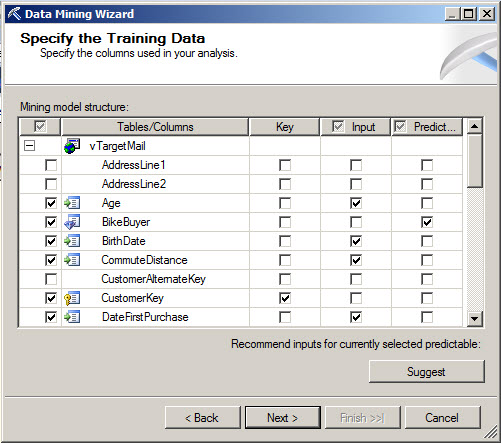
5. In the Specify the Training Data, select the Age, BirthDate, CommuteDistance and all the information related to the customer as input. The BikeBuyer will be the data to predict (1 if the customer is a buyer and 0 if not). You can use the suggest button for help.
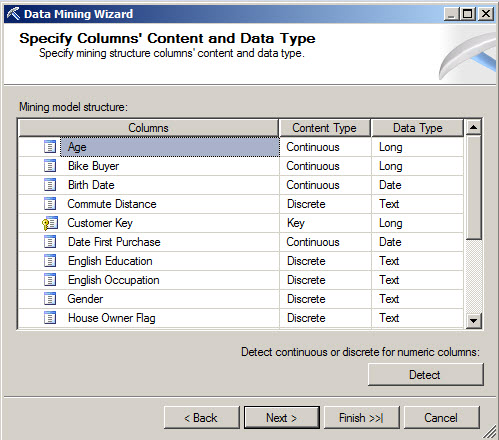
6. Leave the Specify Columns windows with the default values.
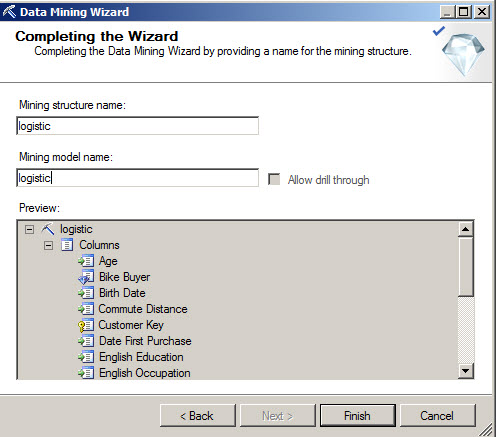
7. Specify a name for the Mining Structure and Mining Model and press Finish.
8. Go to the Mining Model Viewer. You will receive a message to deploy the model. This process is similar that other models in earlier chapters.
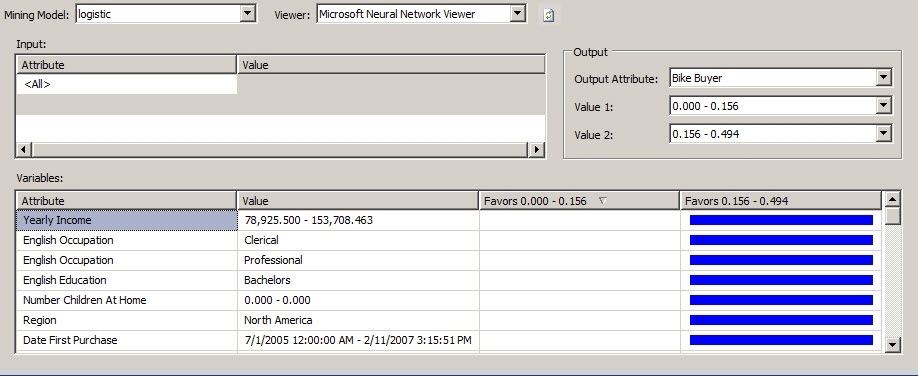
9. Once deployed, in the Mining Model Viewer tab, you will be able to see the relationship between atributes and the relationship to buy or not a bike. You will be able to see the relashionship between professions, Incomes, etc and the fact to buy or not a bike here.
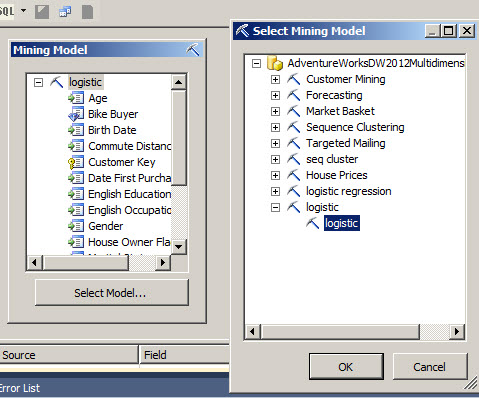
10. In order to test the model, let's go to the mining prediction Tab and in the Mining Model press the Select Model button and select the logistic model just created in step 7.
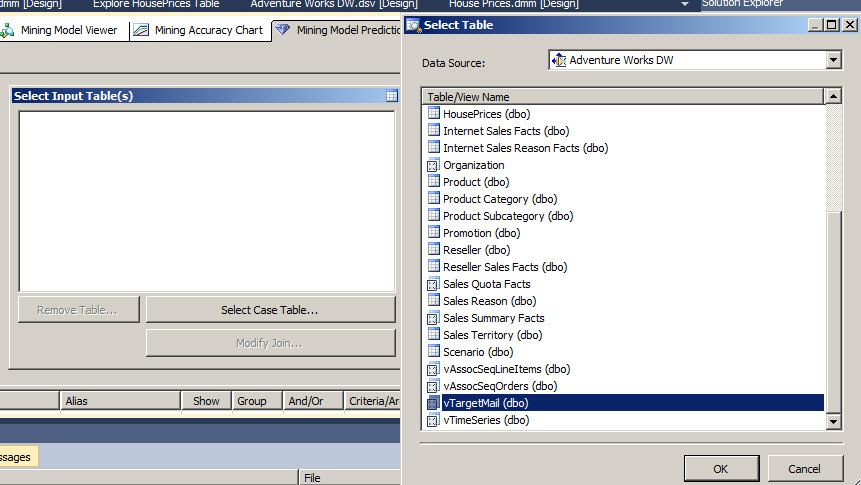
11. In the Select Input Table, press the Select Case Table and select the vTarjectMail view.
12. Select the Singleton query option to query the Data Mining Model
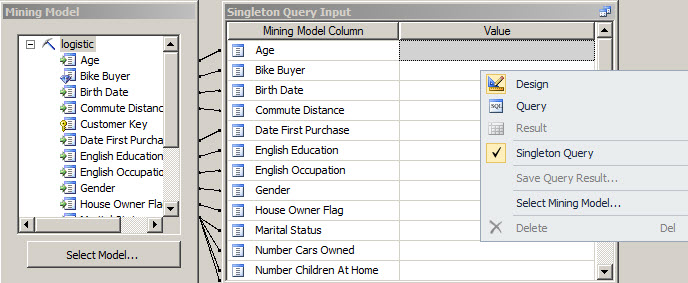
13. In the source section, select the logistic source and the bike buyer fields. Also, select a prediction funcion, and in the Field choice, select the PredictHistogram function to create a histograms with the probabilities to buy a bike. In the criteria/argument, make sure you chose the prediction value.
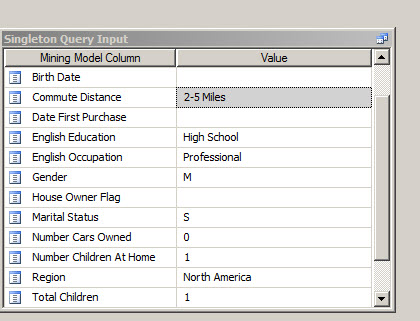
Assign values to the Commute Distance, English Education, English Occupation, Gender, Number Cars Owned, Number Children At Home, Region, Total Children as shown in the picture below:
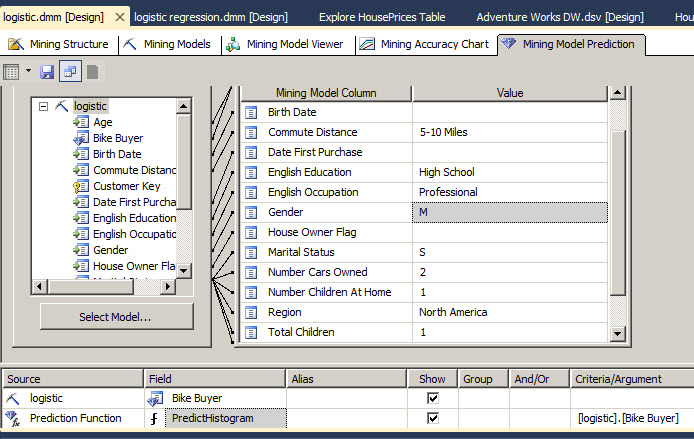
14. Go to the result.
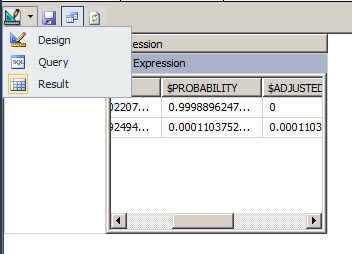
15. As you can see, the probability to buy a bike for male, professional customers with a commute distance between 5 and 10 miles and 2 cars is too low.
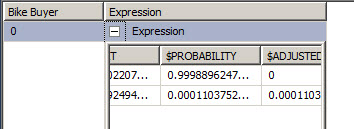
16. What about customers with a commute distance of 2-5 Miles and no cars?
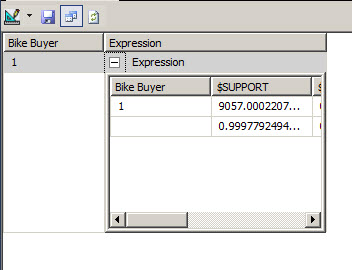
17. As you can see in the Histogram, the customer will probably buy a bike with the caracteristics of step 16.
Conclusion
In this lesson, we learned the basic concept about logistic regression and we created an example using Microsoft Analysis Services. We created a Data Mining Model to predict if a customer will buy or not a bike based on the personal information like the age, number of children, cars, etc.