Working with variable length number
-
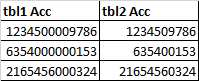
please assist I have table 1 and table 2, join them on account number. the problem is that table 1 has extra zeros in the middle and while table 2 does not have extra zeros in the middle, the account number is not always of the same length. see below I need to match the number on the left with the number on the right.

-
It looks as if tbl1 pads out the account numbers so that they're all the same length, by inserting 0s before the fourth to last digit. If I'm right, you can do something like this (not tested because the data itself would have been much more helpful than a picture of it):
ON tb1.Acc = STUFF(tbl2.Acc,LEN(tbl1.Acc)-4,0,REPLICATE('0',LEN(tbl1.Ac)-LEN(tbl2.Acc))You'll need to cast as varchar first if the data in your tables is stored as a numeric type. Even better than my solution above would be to fix the data, if that's an option.
John
-
Hi John,
thank you for the feedback. Fixing the data is not an option available to me. So I tried your solution but it runs too long as I'm applying it on the join and both tables have records well over 50 mil. So I opted to remove all the zeros from both columns and I got the results that I was looking for.
-
Yes, I meant to mention that performance would be horrible. You do realise you're going to get false matches the way you've ended up doing it? For example, 3045 would match up with 3405. You might consider an indexed view or a persisted column on tbl2 that would pre-pad the account number with 0s so that the calculation doesn't need to be done on the fly.
John
-
I can't see how you know exactly where to split the number, for example, how would you know if tbl2 number 1234050360 is 1234-050360 or 123405-0360?
If you are sure you know how to split the numbers then I would create a copy of one of the tables but with the conversion of the Acc to the value in the other table. This will give you the performance improvement you need.
For example:
SELECT *,
LEFT(Acc,5) + RIGHT(Acc,5) OtherAcc /* Whatever formula is for converting to other Acc */
INTO #tempTable
FROM tble1Then do the join to the temporary table.
-
Hi Johnathan,
you are right the values are of variable length so it is very difficult for me to use the left right functions as they only get me the partial result because LEFT(Acc,5) is not always 5 and Right(Acc,5) is not always 4 as I initially thought. what is constant in the other table thugh is that the account number field is stuffed with zeros in the middle. So what is need is to find the start of those zeros and where they end so that I can remove them.
for example: we take 123400000050360 and turn it to 1234050360
123456000001 to 1234561
if you can help me with an example of how to remove those zeros in the middle I would be greatful
-
You need to define your rules for removing zeroes. In your first example, you removed 5 of the 6. In the second, you removed all of them. How can we help if we don't know what your method is?
-
Have you ever heard the story about Levitan the tailor? It's a very old comedy routine from the 1930s.. A customer comes into the shop looking for a suit. Levitan puts him in the most horrible suit you can imagine. And when he complains about it. Levitan explains that all he needs to do is tuck his arm this way, twist the pants leg up here, etc. The routine has a lot of physical humor. The customer objects to this, so Levitan tells him that if you walk to the end of the block and come back to the store and if you don't get one compliment on this new suit, "You can have it for free!".
The customer walks to the end of the block and he is stopped by a little old lady who asked him who his tailor is. She then says, "Oh, I've got to get a suit for my husband from him, because if he can fit a hopelessly deformed cripple like you, he must be the best tailor in the world!"
The point of the story is that you need to clean up both tables, and build a data dictionary that defines the regular expression for all of your string implemented data elements. You're trying to fix it on the fly in your code and it doesn't really work that way in the real world.
Please post DDL and follow ANSI/ISO standards when asking for help.
- jcelko212 32090 wrote:
You're trying to fix it on the fly in your code and it doesn't really work that way in the real world.
Absolutely agreed but, unfortunately, the real world is much more cruel and you frequently can't fix it at the source. If you were to draw a map of this, next to where the source is, there would be a warning... "Beware... here there be idiots". 😀
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Example data :
---------------------------------------------------------------------------------------------------------------------------
-- Ben Brugman
-- 20200102
---------------------------------------------------------------------------------------------------------------------------
-- Create some example tables.
drop table if exists number1
drop table if exists number2
Create table Number1(nr1 bigint)
Create table Number2(nr2 bigint)
-- Insert some examples.
insert into number1 (nr1) values (1),(2),(34),(5678), (12300456)
insert into number2 (nr2) values (1),(2000),(30004),(5678),( 12300456),( 10002300456),( 1200300456),( 12300000456),( 1230040056),( 123004560000)A possible solution:
---------------------------------------------------------------------------------------------------------------------------
-- Ben Brugman
-- 20200102
---------------------------------------------------------------------------------------------------------------------------
;
With
C as (select nr1,nr2 from number1 join number2 on replace(nr1,'0','') = replace(nr2,'0',''))
, R1 as (select *, '1'+REVERSE(nr1) reverse_string1, '2'+REVERSE(nr2) reverse_string2 from C)
, R2 as (select *, convert(bigint,reverse_string1) reverse_nr1, convert(bigint,reverse_string2) reverse_nr2 from r1)
, L1 AS (SELECT *, reverse(convert(varchar(100),abs(reverse_nr2-reverse_nr1))) fstring
, reverse(convert(varchar(100),abs(nr2-nr1))) bstring FROM r2)
, L2 as (SELECT *, datalength(fstring)-datalength(convert(varchar(100),convert(bigint,fstring))) as front
, datalength(bstring)-datalength(convert(varchar(100),convert(bigint,bstring))) as back from L1)
,NO_Back AS (SELECT *,substring(reverse_string2,back+2,9999999) string01 FROM L2)
,Middle AS (SELECT *,substring(reverse(string01),front+2,9999999) string02 FROM No_back)
SELECT * FROM Middle WHERE REPLACE(string02,'0','') = '' or nr1 =nr2 order by nr1, nr2
-- Steps :
-- C combine potential rows which have the same digits and the same order except for zero's.
-- R1 create a reverse version string of both numbers. (For leading zero's a '1' or a '2' is added.)
-- R2 create a reverse version number of both numbers (indirect via de string).
-- L1 Number of zero's in the front show the number of same digits. (One for the sentinel is included)
-- L2 Count the number of zero's in the front.
-- No_Back Remove the last digits (back) which are the same from the second string number.
-- Middle Remove the first digits (front) which are the same from the second string number.
-- Now only a string of zero's should remain.
-- Show all occurences where removing the zero's an empty string is the result.
---------------------------------------------------------------------------------------------------------------------------For efficiency reasons the table C can be prepared before the CTE is started. Why then the 'complex' code only has to run over the possible candidates which already have a fairly good match.
The algoritme is based on: two numbers are the same if the second number can be created from the first number by inserting a single string of zero's somewhere in the number. This string of zeros can be 0,1,2 etc. zero's long. The algorithm removes the the back of the number if the digits are the same, it removes the front of the number if they are the same, a single string of zero's should remain for numbers which do confirm to the above rule.
The algorithm can not distinguish between a number 1230045 where three zero's are added behind the 3 giving (1230000045) and where the zero's are added behind the first or behind the second zero giving (1230000045). 🙂
I would appreciate a reply on if this is helpfull or not.
Greetings,
Ben
-
---------------------------------------------------------------------------------------------------------------------------
-- Same algoritm, but done in discrete steps.
---------------------------------------------------------------------------------------------------------------------------
drop table if exists C
Create table C(nr1 bigint, reverse_string1 varchar(100), reverse_nr1 bigint,nr2 bigint, reverse_string2 varchar(100), reverse_nr2 bigint, back bigint, front bigint, string2 varchar(100))
insert into C (nr1,nr2) select nr1,nr2 from number1 join number2 on replace(nr1,'0','') = replace(nr2,'0','')
UPDATE c SET reverse_string1 = REVERSE(nr1) -- Add an extra digit, to prevent leading zero's
UPDATE c SET reverse_string2 = REVERSE(nr2) -- Add an extra digit, to prevent leading zero's
UPDATE c SET reverse_nr1 = reverse_string1
UPDATE c SET reverse_nr2 = reverse_string2
--
-- Count the number of digits which are the same at the front and at the back.
--
Update C set back = DATALENGTH(reverse_string2)-DATALENGTH(REVERSE(CONVERT(VARCHAR(100),CONVERT(BIGINT,reverse(convert(varchar(100),abs(nr2-nr1)))))))
Update C set front = DATALENGTH(reverse_string2)-DATALENGTH(REVERSE(CONVERT(VARCHAR(100),CONVERT(BIGINT,reverse(convert(varchar(100),abs(reverse_nr2-reverse_nr1)))))))
UPDATE C set string2 = substring(reverse_string2,back+1,9999999) -- Chop of the back of the string which is the same.
UPDATE C set string2 = substring(reverse(string2),front+1,9999999) -- Chop of the front of the string which is the same.
UPDATE c SET string2 = REPLACE(string2,'0','') -- Remove any zero's from the remaining string.
select * from C order by nr1, frontThe same algorithm, but with 'in between' results.
The number of 'same' digits at the end is determined by subtracting both numbers, and then getting rid of the leading zero's by reversing the string and with the integer type removing the leading zero's and the determining the length of the string.
For the 'same' digits at the end, this is determined by doing some extra reverses on the string.
Although maybe this method is not efficient (or even elegant), it does avoid loops, it does avoid limitations on the number of zero's which can be inserted. With string manipulation the number of same digits can be determined in a number of ways. But in this algorithm there is no 'defined' limit about the length or the length of the inserted string of zero's. But there is offcourse the limit of the largest possible number in the datatype (in this case the bigint).
As for sanitizing the source data, there will always be situations where data comes together where there is a mismatch between data which is actually the same data. This can be because of history (in the past things were done and named differently), because of culture (American system in general can not handle European names, addresses etc.), or just because not everything is designed or modeled with all possible future uses in the mind.
All have a very good 2020,
Ben
-
Hi Ben, thanks for the response. I have since found out that the last 4 digits are the same in both tables, the variations come from the left side of the string where 1230000045 could sometimes be 12030000045 or even further 120300080045. what I need is as follows:
1230000045
120370000068
120300080025
get the last 4 digits (witch I can do with right function) concatenate with the digits from the left preceding the zeros. simply put I need to remove the noise between the last 4 and the numbers on the left.
-
with cte as
(
select *
from (values ('1230000045'),
('120370000068'),
('120300080025')) T(AcctNumber)
)
select cte.AcctNumber,x.firstDigits,x.lastDigits,x.firstDigits+x.lastDigits allDigits
from cte
cross apply(values (right(cte.AcctNumber,4),reverse(convert(bigint,(right(reverse(cte.AcctNumber),len(cte.AcctNumber)-4)))))) x(lastDigits,firstDigits) -
Trybbe, what are the results you want to see for your 3 examples?
The issue is confused by the 8 in the 8th position of the last account. Is that 8 significant or should it be removed? Based on your bolding, it looks like you don't want it. Jonathan's answer retains it.
Neat trick by Jonathan to convert the reverse of the leftmost digits into a bigint, because that strips leading zeros. (There is an implicit conversion in there to get it back to a string before re-reversing it.)
-
Hi gvoshol,
you are correct 8 should not be included. Jonathan's answer work's well until I get to accounts that have the variation like 8 on the last account.
Viewing 15 posts - 1 through 15 (of 22 total)
You must be logged in to reply to this topic. Login to reply