very slow select
- ScottPletcher - Wednesday, January 23, 2019 11:15 AM
I'm not trying to be condescending, Scott. And I don't care if you've been a DBA for 30 years or 30 seconds. I'm just trying to share some things that, from our conversation, that I don't believe you understand. Heh... and stop and think about what you just said. What the hell does it matter if I'm a DBA or not? For that matter, what is YOUR definition of DBA? Are YOU being condescending? 😉
Totally agreed on the simplistic 10 and 30% rules. According to Paul Randall, MS asked him to come up with some generic guidelines for when to rebuild indexes and those numbers were it. He also states throughout the BOL entry for sys.dm_db_index_physical_stats that you have to take other things into account such as REORGANIZE not making new pages and things like evenly distributed indexes, etc, etc, but, to your point, most people only see the 10/30% recommendations (which have recently changed to 5-10/30%).
As for REORGANIZE, I'm done with that. I had a 146 GB "Ever Increasing" Clustered Index that had only 12% Logical Fragmentation due to "ExpAnsive" updates and only at the logical end of the index. Reorganize took 1 hour and 21 minutes and caused the log file to explode from 20GB to 227GB. Not exactly the light-weight, low-resource usage tool that it's advertised to be. After a restore from the same backup to my test system where I tested the REORGANIZE, I did a rebuld in the Bulk-Logged Recovery Model on the same index in the same condition it was before. It took a little over 12 minutes and only caused the log file to grow from 20GB to 37 GB.
Yep... I know that won't work if you're using AG or log-shipping or anything else that relies on the log file being in the Full Recovery Model but it sure made life easy on the clustered node via the SAN clustering that we use.
To be honsest, I did the REBUILD twice and so it actually took 24 minutes (which is still well shy of and hour and 21 minutes). The first rebuild was to a temporary file group, The second was back to the primary and then I dropped the temporary file group. That kept the rebuild from creating an unwanted 146GB (+20% of that) are of freespace on my primary filegroup.
As for not seeing a need for a Fill Factor as low as 80%, I agree that's pretty low and should be avoided if at all possible. However, to prevent massive numbers of page splits for GUIDs and "Random Silos", it can be critical. I have to tell you that "Random Siloed" indexes are not uncommon. In fact, the index you recommended on this thread will probably turn out to be a "Random Silo".
Yes! Such an index can cause a HUGE drop in the I/Os associated with a query or two. But it will be a killer for page splits during the out of order, mid index (the definition of a "Random Siloed Index" inserts it will cause and the huge number of log file entries that will cause especially if the index carries a lot of rows per page. Combined with the usual "ExpAnsive" updates that most Clustered Indexes suffer and you end up with large areas of pages that have only 1 to 30% page density and that destroys the concept of an efficient index especially when it's loaded into memory for use. Heh... and speaking of I/O, you should see the misery in the form of I/O that those page splits cause.
You also keep harping on the benefits of the Clustered Index being on the right columns but you never state what happens to your I/O if you have Clustered Indexes like the ones I have to put up with. They're extremely wide (more than 140 wide columns in many cases and, no, not by my design) and have a page density of 4-9 row per page. It would be stupid to think that a query working by key on the clustered index on such a low page density table would be faster than a properly formed non-clustered index that contained only 4 or 6 columns. Heh... and talk about a drop in I/O!
And all of that is why I keep trying to share information with you. I'm not trying to be condescending. Trust me, there will be no guesswork to it if I ever go vertical on you in such a way.
Ah.. and BTW... On the subject of clustered index keys in non-clustered indexes. If the clustering key is unique and the non-clustered index is not, the clustering key will automatically be added to the B-Tree of the non-clustered index as a uniquifier whether you intentionally add it or not. Since most non-clustered indexes are NOT unique, that makes it even more important for the clustered index to be unique.
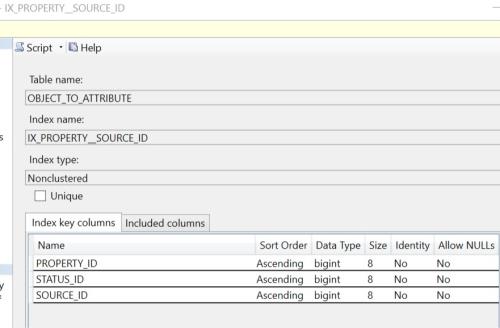
With that in mind, I hope that you meant that the addition of the clustered index on Property_ID and Source_ID would be a UNIQUE clustered ID or the leaf level of the non-unique non-clustered indexes will end up with a uniquefier for duplicate entries in the B-Tree and both the clustered index keys and that uniquefier and the uniquifier for the clustered index in the leaf level, as well.
ScottPletcher - Wednesday, January 23, 2019 11:15 AMTrust me on this... I'm just sharing information. To me, it doesn't matter if you've been a DBA for 30 years or 30 seconds. If I think you don't know something because of the conversation taking place, I'm going to try and share what I know with you. If I was going to be condescending, you'd definitely know for sure. And, speaking of condescending, what the hell does it matter if I'm a DBA or not? Are YOU being condescending? I'm starting to think so.
As for not being able to imagine using a Fill Factor as low as 80%, that's a part of what I'm talking about. And, no... it's not unusual where such a thing could benefit. Such Fill Factors will seriously benefit GUID based indexes because of their extremely even distribution. I've got demonstrable tests that clearly demonstrate that, done the right way, such indexes can be made to go literally for months without any page splits at all and still not be a waste of memory.
Non-GUID keyed indexes can also benefit the same way in the areas of "Random Siloed" indexes and a whole lot of non-clustered indexes fall into that category, so they're not as unusual as you may think.
Speaking of "Random Siloed" indexes, unless Property_ID in the index you recommended is an IDENTITY column (the things you hate), you will have a "Random Siloed" index and that's absolutely the worst thing to have for a clustered index.
You say that you got I/O to drop dramatically with your changes in clustered indexes. That may be true for what you've worked on but it's patently not true for what I have to work on. Certainly not by my design but we have a great number of wide tables that consist of more than 130 columns. Many of the columns are also wide. The resulting row density per page falls in the range of 2 to 9 rows per page. Changing the clustered index to satisfy even a single query would be devastating to performance. Instead of reading a nice narrow non-clustered index of something like 4 to 6 columns per row with hundreds of rows per index leaf page, we'd now be reading between 2 to 9 rows per page and the I/O would skyrocket.
The other thing that you don't seem to understand is that, even if you do reduce I/O, that's only for the queries that would benefit from such a thing on a narrow clustered index. You're not taking into consideration what the massive amount of page splits in many of the clustered indexes that you've posted will do to other SELECTs while even just a relatively few number of inserts or "ExpAnsive" updates have their way with your index, memory, and your log file. And then there's the end result of having the most used areas of the index weighing in at 1 to 30% page density because of the resulting "Silos" in the indexes.
Heh.. and to be sure (bringing up a previous subject) most non-clustered indexes are not unique. Because of that, if the clustered index is unique, then the clustered index key for the lowest row on each of the non-clustered leaf level pages will, in fact, be copied up to the B-Tree to act as a uniquifier for duplicated rows. If the clustered index is not unique, then the B-Tree of the non-unique, not clustered index will carry a uniquefier for duplicated rows in the B-Tree and will be added to the Leaf level along with the non-unique clustered keys and its unquifier. Let's hope that the clustered index of Property_ID and Source_ID that you recommended for a unique combination and that you meant to say that it should be a UNIQUE clustered index or any non-clustered indexes on that table are going to take a beating and I/O is going to go up right along with all that. And then also understand that since the table being used isn't the PROPERTY table, pray that the Property_ID (or the Source_ID, whichever ends up first in your clustered index) is based on an IDENTITY column (the thing you loath) so that the resulting clustered index doesn't turn out to be a "Random Siloed" index and all the hell that goes with it.
And finally, I appreciate experience as much as the next guy but leave your 30 year "ring" at home. You knocking your ring doesn't add anything to the conversation.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden - Wednesday, January 23, 2019 10:53 PM
You seemed 100% locked in on the idea that the only possible clustered index is a single, narrow column. That's just not true. Not every table that's not automatically clustered on an identity column is going to descend into vast empty spaces in the table. Again, I'd love to see a specific example of the data you're talking about. I just haven't run into that issue often enough for it to be a major consideration.
Since I cluster child tables first by the parent identity, I don't see how it could be that serious a fragmentation issue. I really don't see any justification for insisting on clustering child tables only by their own identity. That's just inefficient.
Now, for this specific q, yes, what to cluster has not been based on a full examination of the data as should be done. What I do know is that a majority of the time, a clus index should not be based first on identity, so I start there. A posteriori, yes, I assume a column named _ID is not a random value, but one assigned sequentially in some way. Perhaps that's wrong, but we have no firm info one way or the other, so I go by general occurrences. What gives you the impression that it's a completely random value?
The other problem with creating a covering index for (almost) everything is that you end up with 3-8x times the disk space used, and those reads don't get shared. Query1 uses covering index A, query 2 uses B, etc. All are separate, non-shared I/O, even when all are in the buffers at the same time. And the total size of all those non-clus indexes is often 2-5x times the size of the main row anyway. Those situations occur frequently also, but the index-separately-for-everything perhaps doesn't really consider that as well as it should.
Again, with best clustering, you greatly reduce the number of covering indexes and total I/O goes down drastically. After that, you can tune the problem queries as needed, adding non-clus indexes as required.
The merge joins on the child tables are extremely efficient, and remain so even over large numbers of rows (indeed, for the entire table). You don' have the incessant tipping point issues you do with covering indexes. Or the constant growth of them as more columns get added to the queries they cover.
As to 80% fillfactor, yes, GUIDs could be the rare case. Even then, can't imagine wasting a minimum of 20% of the space for historical data (i.e. that data that's past changes occurring to it). I'd be much more inclined to have a current table with an 80% (or less, if really needed) and a non-current table; a view can be used to treat them as the same table for query purposes. Or, as I noted above, to use partitions to do that. But I can't imagine leaving an entire table of any real size with 20% of space wasted in the older parts of the table. I stick by that.
Certainly not by my design but we have a great number of wide tables that consist of more than 130 columns. Many of the columns are also wide. The resulting row density per page falls in the range of 2 to 9 rows per page.
Yes, also a genuine issue. Typically you can still remediate these developer-"designed" tables fairly well. Most common are "encoding" values (using a numeric id in place of the actual value) and/or adding a paired 1-1 table to hold wide and/or not frequently accessed columns. For example, I prefer to encode all street addresses (all the better to scrub them!) and at least the domain part of email addresses (all the better to change them! and it makes much more sense to store a 2-byte code meaning "yahoo.com" rather than storing the string over and over, row after row; btw, you don't ever need to actually physically store the "@" sign, of course).
I'm sure there are legitimate cases of a lot of columns for one table. That's still no reason they must necessarily be stored physically all together. Usually you can eventually get most "core" tables down to a reasonable size. Certainly at least to a more reasonable size.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
- ScottPletcher - Thursday, January 24, 2019 10:28 AM
No where did I suggest making a covering index for everything.
Also, encoding the wider tables would be awesome (great suggestion and, like you, I suggest it and normalization, as well) except for one thing... that would also require recoding of a whole lot of code and involve a whole lot of regression testing. As with many companies, they're just not willing to spend the time doing such a thing (even with the substitute updateable view and sister-table tricks) if there's a work around (and there are a couple of things that can help in this area)
Totally agreed on partitioning to help with index maintenance but that's only going to be worth while if the partitioning is capable of solving the page splitting problem (and it's frequently not). The other problem is that doing the wrong kind of index maintenance (the 10/30% stuff) causes huge problems across hundreds of smaller indexes. You can't partition the "Death by a Million Cuts". It IS, however and as you state, a huge maintenance saver on larger tables.
Also, if you think that an 80% Fill Factor when used with GUIDs wastes 20% of the memory, then you're one of the folks that I'm trying to educate about GUIDs and indexes in general. Don't get me wrong... I wouldn't intentionally use GUIDs as an index key ever but, when it comes to index maintenance and the prevention of page splits, most people are doing it totally incorrectly. Like I said, in the tests that I've done I was able to go simulated months between index maintenance with 0 page splits and the resulting 0 logical and physical fragmentation just by changing how I maintained the indexes. There weren't even any good page splits. If you're stuck with a system that uses GUIDs as keys, then you need to see my presentation on the subject.
Heh... and again, with the "best" clustering index, you have to remember that I/O going down may only be for the queries that benefit from such an action and that you can actually cause severe problems in other places that people don't even consider and will just say SQL Server is slow instead of understanding the real problems.
And, we're both repeating ourselves now so I'll have to say I agree with you on a lot of things and disagree with you on others. Thanks for talking.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden - Thursday, January 24, 2019 1:32 PM
No, you make the existing table a view with exactly the same format as the current table. You can do all the changes transparently.
Please explain to me how clustering child tables by ( parent_identity, child_identity ) rather than just ( child_identity ) [it's narrower, so it must be better ... but it's NOT] could lead to any type of serious issue.
To me it's bizarre to insist that anything other than an identity key will essentially automatically lead to "random silo" and massive gaps in pages. Can you provide a single table structure and pattern of updates that would cause this that would be repeated in multiple tables under typical company structures?
Unquestionably poor initial table design is a huge problem. It is vastly harder to retrofit a decent design. But most companies insist on allowing developers to faux-design tables, so that problem isn't easily addressed.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
- ScottPletcher - Thursday, January 24, 2019 1:40 PM
Making the view with the same format of a table doesn't buy you anything unless the underlying table is split up (which will require Instead-Of triggers to make it updateable) or the view is indexed. If you have something else in mind, please explain.
And, no ... I'm not suggesting that a narrow clustered index would be better than a wide one. I'm suggesting that you changing to a wide one will do nothing except maybe help one or two queries that are based on the clustered index you've chosen and at the expense of possibly rampant page splits and the fragmentation and log file writes that go with it. To your point, though, one good test is worth a thousand expert opinions. If you'd like to provide the CREATE TABLE statement and a method to populate it with, say, a million rows, then we can play and perhaps see more clearly what each other means.
And, no.. it's not just IDENTITY columns that can help avoid Random Silos nor is it necessarily a prevention in the face of ExpAnsive Updates. What will cause silos is the insertion of rows to an index (Clustered or otherwise) in an out-of-order fashion. Since the CI is generally much wider than any NCI, there comes a need to protect that order not for read performance but to prevent the need to recover disk space (and memory) by having to defrag such large tables more often than necessary.
As with all else, though, "It Depends" and I'm looking forward to working on an example with you.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jonathan AC Roberts - Tuesday, January 22, 2019 9:50 AM
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Tomys - Tuesday, January 22, 2019 9:23 AM
Backing up a bit, Did you ever end up changing this index? A couple of us believe that you need to add an INCLUDE of the VALUE column to this index.
Also, if you can afford to do so, when you drop the index above and replace it with the same index keys and have added the INCLUDE, if you can be in the BULK LOGGED recovery model when you do that, the drop and the build will occur much more quickly. The only thing to remember is that you should take a log file backup just prior to that action and just after you complete the action to minimize the amount of time where a mid-file T-Log restore (Point in time) of the 2nd backup won't be possible because of the "Minimally Logged" actions taken.
Also, does the combination of Property_ID and Source_ID form unique values in this table or not?
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden - Sunday, January 27, 2019 7:24 PM
Hi Sir, thank you very much for the suggestion, and sorry to respond late.
I haven't yet tried the adding the Include value, I am actually scared if this would create any blocks to other process and eventually cause the server to shutdown or anything of this sort?thanks again,
- Tomys - Wednesday, January 30, 2019 10:48 AM
You should really have a test environment where you can try these things out.
Would it be possible for you to take a backup and restore it on another machine and try it there? - Jonathan AC Roberts - Wednesday, January 30, 2019 10:58 AM
Dear, I would like to try on a test environment, but currently we don't have the same storage allocated for it.
The size on the database in production is around 3 TB. But this idea of testing on DEV definitely sounds good. I may try to request more storage and restore the database on to DEV. - Tomys - Wednesday, January 30, 2019 10:48 AM
That Index is 3TB? Maybe the whole table is 3TB but not likely that one index?
I'll also state that if you have a 3TB table, then you either need to drop out some legacy data or you need to plan on some partitioning so that you can actually do things like index maintenance without bringing the whole table to it's knees.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally)
Viewing 11 posts - 46 through 56 (of 56 total)
You must be logged in to reply to this topic. Login to reply