very slow select
-
You wouldn't typically want to cluster on status, since it tends to change.
However, you'd almost certainly be better off clustering by PROPERTY_ID and /or SOURCE_ID in whatever order. But to determine that we'd have to look at table index stats (missing and usage stats, at least, operational stats sometimes) and data cardinality (how often values appear). However, just because the keys are not highly selective does NOT mean they won't make a good clustering index key. Non-selective data is usually not good for non-clus indexes, but it can still be extremely helpful to performance for a clus index, as there's no tipping point for a clus index.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
- ScottPletcher - Tuesday, January 22, 2019 10:02 AM
You should go back an re-evaluate that when it comes t larger clustered indexes. There's a whole lot more at stake than just fast selects.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden - Tuesday, January 22, 2019 10:57 AM
Not as much as you think. Getting the best clustered index often eliminates a lot of non-clus indexes. I don't believe in creating gazillions of covering indexes, essentially one for every major query. They're just too picky and too difficult to maintain.
Child tables are the best example. They should almost always be clustered on the parent key first. Since the parent key itself is naturally ascending, this is not really an issue, as long as you update the stats when you need to. In rare cases I've had to partition the main table to keep the highly-active current rows separate from the older rows, but it's very rare you really have to do that.
A row is inserted once, but selected 100Ks or Ms of times. That's quite natural in a relational db. Some fragmentation -- ~4-8%, with a big "it depends" -- is not that big a deal (although I don't go nearly as far as some, who say that frag almost doesn't matter). But I do think it's overly hyped at times.
The sweet spot is to get the desired merge joins on most of the extremely common joins. That payback is huge. Two clustered seeks with a merge join is super-efficient.
That said, if you have very unnormalized tables and/or don't encode char data values as often as you should, then you will have bigger problems, since the rows will be much wider. But that's properly a design issue, not an indexing issue.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
- ScottPletcher - Tuesday, January 22, 2019 11:27 AM
Totally agreed about picking the BEST Clustered Index. The thing that I disagree about is that the BEST Clustered Index isn't always the one that people try to use as a panacea of performance for SELECTs, especially when such indexes get large enough to no longer fit in memory. When that happens, you actually do have to science out what is going to be SELECTed so that it will not only fit in memory but will also keep the current query from forcing the data for other tables out of memory. There's also the problem of index maintenance, especially in the world of the Standard Edition where the ONLINE option for rebuilds isn't an option and the amount of time the system is actually pounding its head against the wall trying to rebuild or {gasp} reorganize indexes and the effects that out-of-order INSERTs and "ExpAnsive" updates will have on page splits and the ensuing massive logical and physical fragmentation as well as the massive logfile activity that page splits cause.
For example, your recommended Clustered Index on Property_ID and Source_ID will, at best, result in a "Sequential Silo" pattern of inserts. While that causes do harm for Physical Fragmentation (Page Density), it causes MASSIVE logical fragmentation to the point where the fragment size will reduce to just "1" page. That's as bad as doing a Shrink File when it comes to performance of SELECTs that need to read from disk (even if they're SSDs) into memory. At the worst, you'll end up with "Random Silos" and you must NEVER allow a Clustered Index to fall into such a pattern because of all the problems previously stated.
And, what many people don't understand is that such Clustered Index keys can and will also cause serious fragmentation in the related Non-Clustered Indexes, which only exacerbates all of the problems I've mentioned. For those new to the game, this is because the keys of the Clustered Index become a part of the keys for every Non-Clustered Indexes and this problem is particularly nasty on single column Non-Clustered Indexes. Paul Randall has a great demonstration of this phenomenon. Don't let the fact that he uses GUIDs to demonstrate the problem throw your.
The bottom line is that there are some HUGE and painful consequences that will occur that most people aren't even aware if only the performance of SELECTs is the driving consideration for what the Clustered Index should be keyed on.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden - Wednesday, January 23, 2019 7:29 AM
this is because the keys of the Clustered Index become a part of the keys for every Non-Clustered Indexes
Not true. They become included columns only, they are not part of the non-clus key unless you make them so.
Haven't seen much of what you're talking about. Can't imagine how it would be a major issue. After a reorg/rebuild, only new rows should even have the potential for issues. If one had to, partitions could likely be used to get around this.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
- ScottPletcher - Wednesday, January 23, 2019 7:53 AM
Ah... quite right on where the clustered keys appear in the non-clustered index. I didn't write that correctly. The keys of the Clustered Index become a part of the Leaf Level of the related Non-Clustered Indexes. I made it sound like they automatically become a part of the B-Tree of the Non-Clustered Indexes and apologies for that.
I'll also add that if the Clustered Index Keys are not unique, you'll also have some serious extra overhead in the form of "uniquifiers" in the Clustered Index. Those also become a part of the keys that are expressed in the leaf level of the Non Clustered Indexes.
Haven't seen much of what you're talking about. Can't imagine how it would be a major issue. After a reorg/rebuild, only new rows should even have the potential for issues. If one had to, partitions could likely be used to get around this.
That's precisely what I'm talking about. Most people haven't seen what I'm talking about because they're not aware of it and haven't looked for it. For me, it all started when I started to have major blocking every Monday morning (and I proved that it was because I was doing index maintenance following "Best Practices" every Sunday night) and then performance would get better during the week. The only reason I became aware of it all is because it actually started to cause production issues for me. For a lot of people that experience such things, they never end up figuring out that it's their indexes that are actually causing the blocking issue. And most people just assume that the large transaction log backups they have are just due to "normal" activity rather than being totally unnecessary in a whole lot of cases. In other words, they may not experience major blocking issues that are noticeable in the same manner than they were for me but there's still unnecessary blocking issues slowing people's code down that they may never become aware of.
And, no... Although INSERTs can suffer greatly from this issue, the duration and locking of the system level page locking that occurs during during such inserts can and do have a huge affect in the form of blocking (4.5 to 43 times longer than a supposed "good" page split... I've actually seen more than that but his demo proves the numbers of 4.5 to 43) and that directly affects the performance of SELECTs. All Inserts basically ignore the Fill Factor and will attempt to fill pages to 100% no matter what the Fill Factor is. Yes, if you have room on a page and the new rows will fit, the inserts won't cause a page split. The trouble is that you're typically not spreading the inserts out in an evenly distributed fashion (although GUIDs are great for this although they suck for other reasons). Rather you're inserting (especially for non-clustered indexes) into "Silos" of data with identical index keys and they're not going to be inserted in an "ever increasing" manner. This has a devastating effect on fragmentation and, because the "Silos" also have a very low page density, the most used data (which is in the Silos) wastes a huge amount of memory..
People also say if you have a lot of fragmentation to simply decrease the Fill Factor. For large indexes, that leads to a huge amount of wasted space on disks and memory unless you have an evenly distributed set of keys and it affects not only inserts, but also affects any update that causes a row to grow, potentially even by just 1 byte.
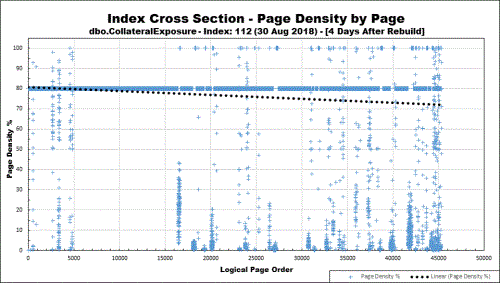
Here's an example of what a "Random Siloed" index does to a 5GB non-clustered index just 4 days after an index rebuild at 80%. The most actively read areas are also the areas that have been recently fragmented and have super low page densities as low as 5%. That means that we're wasting 95% of our memory when we load those pages for SELECTs. Imagine if this were a much wider clustered index. We're also wasting a huge amount of disk space because we used an 80% Fill Factor that isn't doing squat for us. (Note that the logical page order axis is NOT a count of the actual pages in the index).

All of the pages below the Fill Factor line formed at 80% are BAD page splits.
Like I said, most people have no idea that their indexes are going through this hell and they just think that the blocking they cause is "normal". Unfortunately, this IS "normal" for most people's indexes because they've never analyzed indexes in such a manner before.
I truly appreciate your tenacity about picking the right Clustered Index but the "right" one may not be what you think. As the knight told Indiana Jones when he was getting ready to pick which cup might be the "Holy Grail", "Choose wisely".
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden - Wednesday, January 23, 2019 9:46 AM
No, I've looked for fragmentation, and other page-size issues, and haven't seen it in the tables I've re-clustered. Of course I use all the factors I stated above -- and a few more -- to determine the best clustered index, which includes key issues.
and they're not going to be inserted in an "ever increasing" manner.
Why not? Typically the lead key is a parent id, datetime or some other naturally ascending value. The last key can easily be made an identity or some other value. Although I'll admit that I'm sometimes frustrated by the apparent "stupidity" of the SQL engine in how it does some INSERTs. Sometimes an ORDER BY added to the INSERT seems to help.
In all events, the idea that tables should "by default" be clustered identity is, by far and without question, the single most damaging myth to table design and to overall performance. Nothing else comes even close to the amount of damage that myth has done.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
- ScottPletcher - Wednesday, January 23, 2019 10:16 AM
I totally agree that any "generic/default" method that's used as a panacea is the wrong way to go whether the indexes be large or small. You'll get no argument from me there. But the use of IDENTITY columns isn't a plague to be avoided either. As with all else in SQL Server, "It Depends".
As for looking for "fragmentation, and other page-size issues", if you're using only the averages provided by sys.dm_db_index_physical stats, then the issues I'm talking about will be totally hidden from you and that's the same issue with most people. I was right there with everyone else in that misunderstanding. They've never seen what the indexes are actually doing because they're just looking at averages, which mask the true nature of the indexes. For example, how many well meaning folks actually understand that the most used area of an index may actually only have a page density of 5% and are, therefore, wasting 95% of the memory they're using associated with those spots of the index that may be most frequently used simply because they also contain the latest inserts or updates?
There's a whole lot more to indexes, both large and small, than I previously imagined because the tools we all have grown to use don't actually show their true condition.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden - Wednesday, January 23, 2019 10:39 AM
No need to be condescending. I've been a full-time DBA for 30 years. I know what to look for; I didn't go into deep details because I know you're not a DBA.
How about a complete table structure and index stats for your sample table? Or better yet, a backup of the table; you could copy that table to an new db, then just backup that db. I'm very curious to see the type of key pattern that would cause INSERTs to act like that. Perhaps adding a new key column, adding table constraints (to "tell" SQL that certain things are true), or even in some cases adding an ORDER BY on the INSERT could help.
I do reorganize indexes as needed. I do not, however, go by the highly simplistic 30% "rule". Once again a big simplification that gets taken by most people as holy writ. For extent fragmentation, a different overall approach must be found, or you must do a full rebuild of the table, often not practical.
And I can't imagine using a fill factor as low as 80% in any normal type of table. That would be an unusual situation.
I can also tell that my clus indexes changes are working because of the subsequent massive reduction of I/Os on the table, when nothing in the daily work-load changed.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
This is fairly typical of the results I see for a child table. The clus index is ( parent_identity, child_identity ) and the non-clus index is ( child_identity ).
index_id / index_level / avg_page_space_used_in_percent / avg_fragmentation_in_percent
1 / 0 / 98.6172720533729 / 1.35358204027732
1 / 1 / 55.9402767482086 / 97.2222222222222
1 / 2 / 7.90709167284408 / 0
2 / 0 / 96.9757104027675 / 18.4353214562355
2 / 1 / 69.0923400049419 / 0
2 / 2 / 0.457128737336299 / 0Looks good to me. For completeness I included the non-leaf-level pages. I admit I'm not concerned with the non-leaf-level index fragmentation (unless, perhaps, for a huge table, if the # of level 1 pages gets really high).
My guideline is roughly:
92+% = I don't worry about it yet
>= 88 and <92 = take a look at it, but no rush at all
>=80 and <88 = take a look at it fairly soon
<80 take a look at it very soonSQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
Thanks guys I actually can’t even see the fragmentation on the index when I run query to see it just keeps running ran for almost 8 to 9 hours had to them stop it
- Tomys - Wednesday, January 23, 2019 2:05 PM
It would be helpful if you could tell us how many of the rows are updated after insertion with any of the columns STATUS_ID, PROPERTY_ID, SOURCE_ID changing value, and which columns are updated to different values.
You don't really want to be updating indexed rows on a clustered index. -
Thanks for the reply. I basically want to just select and wouldn’t update any rows. Just wanted to know the data as a report to send.
- Tomys - Wednesday, January 23, 2019 2:28 PM
An index will speed up selects, but you don't want a clustered index on columns that are updated.
You need to know your data. -
Thank you sir
Viewing 15 posts - 31 through 45 (of 56 total)
You must be logged in to reply to this topic. Login to reply