update stats vs rebuilding indexes
-
I did have an almost 20 tb database a few years ago - 19 Tb anyways that I inherited at a previous job. It stored pictures and tons of metadata inside the db. The app designer followed every single bit of guidance missing index ever provided only one time, as it appeared. slightly less than half the space was the jpegs, most of it was index and tables.
I don't remember everything we did but we were running into a hard volume size limit in something - whether it be the san or virtualization or backups or something. The third party application was supposed to go through an archive process that had several steps and a purge process that had several steps after the records reached a specified set of ages that it did in a loop in the application processing several thousand records at a time from a table with over two billion records. If the application failed a step in the loop it continued on quietly but considered those records as having been handled by archive or delete forever. It had to first successfully archive a record for a period before it could delete the record and both the archive and delete processes would fail intermittently, while the app still considering the record archived or deleted. There was also a process in the app the mark records for indefinite retention and we'd have some idiot periodically mark an entire camera or entire week or entire month that would be found months later was an accident, then have a tens or hundreds of millions of deletes when it was fixed.
It took us quite a while to figure why it kept growing and a couple years to figure out all the ways the processes would fail for us to write the queries that addressed cleanup from all the failure modes, but it was never practical to run it automatically and too time consuming to run manually on a regular basis.
The first index rebuild we did after the first cleaning reclaimed terabytes of space. after that we did it maybe a couple times a year and usually was only several dozen or a couple hundred Gb but were nervous to leave it alone when we got within less than 100 Gb of 100% full on a 20 Tb volume
-
Sounds like a ton of fun. When you did an index rebuild, did you rebuild it to a different file group and then delete the old file group to prevent having a ton of empty space or did you have a ton of empty space?
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
just had a ton of empty space. We did shrink it to get whatever alert in solar winds to stop so we could avoid addressing it and what disabling autogrowth means in a bi-monthly department meeting for the umpteenth time that was preceded by dozens of requests to stop alerting on it. This was purely political.
We didn't have that much SSD or 10k sas in any other data store and the sata was already completely overwhelemed.
There were hardware purchased for the application, but the exchange admin took the storage and then the finance department took the blade because their idiot erp vendor kept telling them they needed to put more cores in their SQL server to address performance problems that I ended up being vindicated about, about a year later when they told them to increase the cpu count to 64 on a host with only 12 cores, successfully achieving cpu wait times approaching a minute.
I sort of forgot how screwed up that situation was, hopefully there aren't that many others of those out there...
-
Ugh! Shrinking. It does "index inversion", which is one form of fragmentation that really does hammer performance into the ground. That's why I use the "Swap'n'Drop" method on a lot of my big stuff that occasionally needs space recovery.
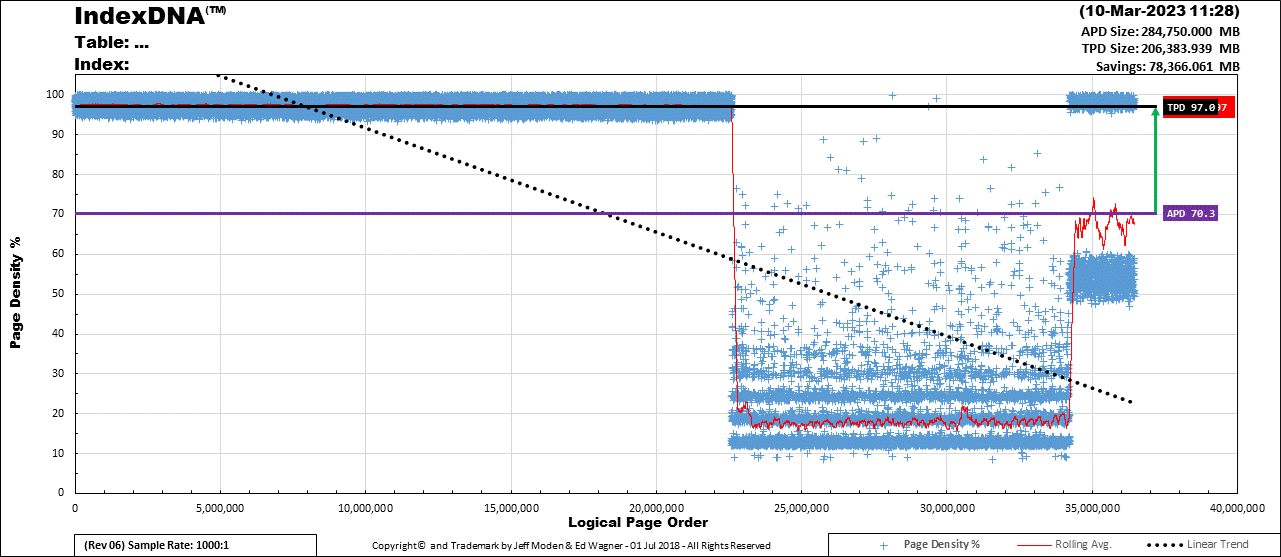
Here's an example of what the CI looks like just a month after a rebuild. It suffers from both "ExpAnsive Updates" in the hot-spot (Inserts followed by "ExpAnsive Updates" almost immediately after resulting in the 50% page density area on the right) and that's followed up by daily deletes on data that's 1 to 2 weeks old. You can see the "bucket" in page density that forms. If you look at the skinny Red line near the bottom of the bucket, it show that average page density down there is only about 18% full. That's a major part of why rebuilding this index will save more than 78GB.

One of the things I'm trying to determine is what the cutoff for the bucket is so that I can partition this table so that I only need to rebuild the part that suffers from the low page density.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally)
Viewing 4 posts - 16 through 19 (of 19 total)
You must be logged in to reply to this topic. Login to reply