Update
-
I have a Use case like.
We migrated around 1000 millions of rows into around 5-6 tables.
client requirement frequently change to update some columns. Is there any best way to Update those tables other then Batch/looping updates.
We tried disabling all the index but still it's taking too much time. Even we have 5-8 hours maintain-ace window. We don't have partitioned on tables. Any best option
-
Just to confirm this, you have 1 billion rows in around 5 or 6 tables that are changing frequently where the column needs to be updated?
There are always tricks you can do to optimize this such as removing the loops. Looping is very rarely the "fastest" way to attack a SQL Server problem.
How are you currently updating that column? How are you populating the column and the table? Is this coming from a flat file and you are populating it OR do you have the data sitting in the table and the client is asking you to do a calculation on the column(s) or change the column(s)?
When they update, are they updating the entire column or a subset of the data? If it is a subset, there may be better indexes that you can filter on. If you are doing an update on the entire table with some calculation on a column, doing that in a single statement (ie no loops, no cursors, just an update statement), will likely give the best bang for your buck. If it is an SSIS package that updates the data and you are truncating and populating the tables with each change requested from the client, then reducing the data set you are changing may be a good step. What I mean here is to break the data up into more tables. Tables that have infrequently changing data and tables that have frequently changing data. For example, customer names may not change often, but sales to a customer may change quite frequently. Since customer names change infrequently, have an SSIS package to pull that across that runs once per month and on demand, and the sales pulling across once per day or on demand.
In your scenario, I would suggest having the columns that your clients change infrequently go into table A (a sort of "Finalized" table) and the columns that have frequent changes going into a second table. My thought process here is that your bottleneck MAY not be on the changing data, but on the data quantity. Moving across 1 billion rows of data to 5 or 6 tables may just be a lot of data and your bottleneck MAY be on the network I/O (presuming SSIS).
If it is a literal "UPDATE" statement that is being slow, I would check for blocking and what waits are coming out of it as well as the server resources and the estimated vs actual execution plans.
99% of tuning a query starts by looking at the execution plans. Bad estimates, tempdb spill, insufficient memory grants, etc can lead to a poorly performing query.
The above is all just my opinion on what you should do.
As with all advice you find on a random internet forum - you shouldn't blindly follow it. Always test on a test server to see if there is negative side effects before making changes to live!
I recommend you NEVER run "random code" you found online on any system you care about UNLESS you understand and can verify the code OR you don't care if the code trashes your system. - 6pravin9@gmail.com wrote:
I have a Use case like.
We migrated around 1000 millions of rows into around 5-6 tables.
client requirement frequently change to update some columns. Is there any best way to Update those tables other then Batch/looping updates.
We tried disabling all the index but still it's taking too much time. Even we have 5-8 hours maintain-ace window. We don't have partitioned on tables. Any best option
If you were to tell us what's in those columns and what data source is being used to update them, maybe there's a way to not have to update any of them.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -

- 6pravin9@gmail.com wrote:
I have a Use case like.
We tried disabling all the index but still it's taking too much time. Even we have 5-8 hours maintain-ace window. We don't have partitioned on tables. Any best option
Indexes on the columns being looked up would help these updates. Have you got indexes on these columns?
You really need to provide some more details about the DDL if you want an answer.
-
That's really not helpful at all.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Table : FinalTAble Which has around 1 billlion rows with 50 columns.
I have to update 600 millions of rows in columnC ('xyz' to 'ABC')
Here Is my Update Statements
Copied 600 millions rows id,ColomnC to another table
SELECT ID,columnC INTO FinalTAble_bedeleted
FROM FinalTAble (NOLOCK)
WHERE columnC='xyz'
SELECT TOP 0 * INTO #temp1 FROM FinalTAble_bedeleted
UNION
SELECT TOP 0 * FROM FinalTAble_bedeleted
DECLARE @rowcount BIGINT = 1
SET ROWCOUNT 0
WHILE @rowcount > 0
BEGIN
DELETE TOP (1000000) FinalTAble_bedeleted
OUTPUT DELETED.* INTO #temp1
UPDATE A
SET A.columnC='ABC'
FROM FinalTAble A
JOIN #temp1 t
ON A.id=t.id
SELECT @rowcount =@@ROWCOUNT
TRUNCATE TABLE #temp1
--RETURN
END
-
You haven't provided information on what indexes are on the tables.
Ideally FinalTAble will have a clustered index on Id and no other indexes.
I would then try creating clustered indexes on temporary tables:
SELECT ID,columnC
INTO FinalTAble_bedeleted
FROM FinalTAble (NOLOCK)
WHERE columnC='xyz'
CREATE CLUSTERED INDEX IX_FinalTAble_bedeleted_1 ON FinalTAble_bedeleted(Id)
SELECT TOP 0 * INTO #temp1 FROM FinalTAble_bedeleted
UNION
SELECT TOP 0 * FROM FinalTAble_bedeleted
CREATE CLUSTERED INDEX IX_#temp1_1 ON #temp1(Id)
DECLARE @rowcount BIGINT = 1
SET ROWCOUNT 0
WHILE @rowcount > 0 BEGIN
DELETE TOP (1000000) FinalTAble_bedeleted
OUTPUT DELETED.* INTO #temp1
UPDATE A
SET A.columnC='ABC'
FROM FinalTAble A
INNER JOIN #temp1 t
ON A.id=t.id
SELECT @rowcount =@@ROWCOUNT
TRUNCATE TABLE #temp1
--RETURN
END -
Another thought - do you NEED columnC in your FinalTable_bedeleted? Probably speed things up a little bit by only pulling the ID's out of FinalTable, no?
Just thinking that 600 million rows with a VARCHAR(3) column (guessing here... probably wrong on that, just guessing based on the sample query given) is going to be a lot of data to read and write to disk (temp tables and table variables exist on disk in tempdb if I am not mistaken) only to be completely ignored.
Another thought, what does your execution plan look like if you remove the loop? I say with removing the loop as you said it runs for hours. I would be curious to know what the execution plan is looking like on each of those steps. Mostly to determine which step is the "slow" step. I expect it to be in the UPDATE section, but if tempdb needs to do a lot of little grows to fit FinalTable_bedeleted and #temp1 into it, you may have a performance hit from that; especially if tempdb is set to grow at a small rate compared to the amount of data being tossed at it.
Also, not sure if it'd help or not (Jonathan AC Roberts suggested no indexes except the clustered index on id and no other indexes), but shouldn't an index on columnC of FinalTable improve the performance of the first SELECT as you don't need to do a table scan then and can do an index seek to get all the rows where columnC = 'xyz'? Just thinking that index to me looks helpful at the start of the query but you would want to disable it as soon as you finished populating FinalTable_bedeleted or the update statement will take a hit.
TL;DR - my recommendation is to reduce your initial data pull into the table FinalTable_bedeleted to just grab the ID's as that is all you need, possibly add a short-term index on columnC of FinalTable that gets disabled/dropped after populationg FinalTable_bedeleted, test the run without the loop to get timing for 1 million row updates and get an actual execution plan at the same time.
The above is all just my opinion on what you should do.
As with all advice you find on a random internet forum - you shouldn't blindly follow it. Always test on a test server to see if there is negative side effects before making changes to live!
I recommend you NEVER run "random code" you found online on any system you care about UNLESS you understand and can verify the code OR you don't care if the code trashes your system. - Mr. Brian Gale wrote:
Another thought - do you NEED columnC in your FinalTable_bedeleted? Probably speed things up a little bit by only pulling the ID's out of FinalTable, no?
I hadn't actually looked at the logic behind the script but it does seem an odd way to do it.
The OP does only need the column Id in the table FinalTAble_bedeleted and does not need columnC.
Mr. Brian Gale wrote:Also, not sure if it'd help or not (Jonathan AC Roberts suggested no indexes except the clustered index on id and no other indexes), but shouldn't an index on columnC of FinalTable improve the performance of the first SELECT as you don't need to do a table scan then and can do an index seek to get all the rows where columnC = 'xyz'? Just thinking that index to me looks helpful at the start of the query but you would want to disable it as soon as you finished populating FinalTable_bedeleted or the update statement will take a hit.
If there are lots of rows with value 'xyz' then an index on FinalTAble (columnC) would also have to also include Id for it to be any use, otherwise a slow key lookup would be required for each row.
An index with columnC on would kill performance of the update so probably not worth adding it just to avoid a single full table scan.
Mr. Brian Gale wrote:Another thought, what does your execution plan look like if you remove the loop? I say with removing the loop as you said it runs for hours. I would be curious to know what the execution plan is looking like on each of those steps. Mostly to determine which step is the "slow" step. I expect it to be in the UPDATE section, but if tempdb needs to do a lot of little grows to fit FinalTable_bedeleted and #temp1 into it, you may have a performance hit from that; especially if tempdb is set to grow at a small rate compared to the amount of data being tossed at it.
Yes, would be good to know how much time each step takes. If there is no clustered index on FinalTAble(Id) then I suspect it's the updates inside the loop that take the time, as each iteration of the loop would require a full table scan of the huge table FinalTAble.
It would be good if the OP could provide details of what indexes are on the table.
-
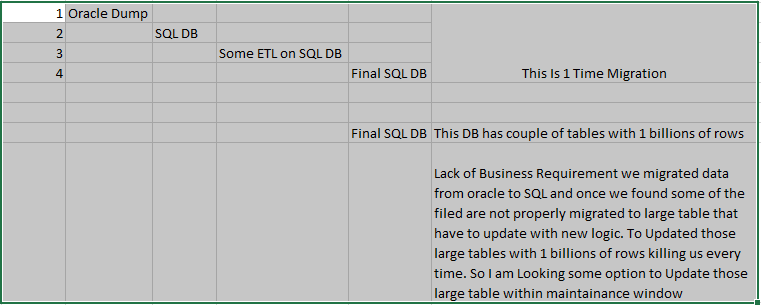
Hi I Did not mentioned earlier, This is my Live OLTP Database/Tables. So On top of the adhoc Queries there are some another maintenance jobs as well as some scheduled jobs are also running.
This is just sample Scenario. Some times I have to update entire table with more then 1 column. SO I can not create Index on all the columns. Yes, I don't Need ColumnC. I can create Index on Temp Table. Still not much improved
- 6pravin9@gmail.com wrote:
Hi I Did not mentioned earlier, This is my Live OLTP Database/Tables. So On top of the adhoc Queries there are some another maintenance jobs as well as some scheduled jobs are also running.
This is just sample Scenario. Some times I have to update entire table with more then 1 column. SO I can not create Index on all the columns. Yes, I don't Need ColumnC. I can create Index on Temp Table. Still not much improved
You need a clustered index on FinalTAble(Id) if you want it to perform well.
-
This is probably a couple of stupid questions that shows my ignorance, but if you never ask how will you learn... 🙂
- Why are you doing your updates in batches? Transaction log size constraints, or?
- Why is this two-table construction necessary? I realize that this i a very big table, and that if there isn't an index on columnC then the table has to be scanned from the start for every batch, but is that why you use this method?
Wouldn't this suffice?
DECLARE @rowcount BIGINT = 1
SET ROWCOUNT 0
WHILE @rowcount > 0 BEGIN
UPDATE TOP (1000000) A
SET A.columnC='ABC'
FROM FinalTAble A
WHERE columnC='xyz'
SELECT @rowcount = @@ROWCOUNT
ENDYou do say that other things and updates are running in parallel with this update in your maintenance window, but do these also touch this table? If not then a table lock specified on the update statement would probably be beneficial.
- kaj wrote:
This is probably a couple of stupid questions that shows my ignorance, but if you never ask how will you learn... 🙂
- <li style="list-style-type: none;">
- Why are you doing your updates in batches? Transaction log size constraints, or?
- <li style="list-style-type: none;">
- Why is this two-table construction necessary? I realize that this i a very big table, and that if there isn't an index on columnC then the table has to be scanned from the start for every batch, but is that why you use this method?
Wouldn't this suffice?
DECLARE @rowcount BIGINT = 1
SET ROWCOUNT 0
WHILE @rowcount > 0 BEGIN
UPDATE TOP (1000000) A
SET A.columnC='ABC'
FROM FinalTAble A
WHERE columnC='xyz'
SELECT @rowcount = @@ROWCOUNT
ENDYou do say that other things and updates are running in parallel with this update in your maintenance window, but do these also touch this table? If not then a table lock specified on the update statement would probably be beneficial.
6pravin9@gmail.com wrote:Hi I Did not mentioned earlier, This is my Live OLTP Database/Tables. So On top of the adhoc Queries there are some another maintenance jobs as well as some scheduled jobs are also running.
This is just sample Scenario. Some times I have to update entire table with more then 1 column. SO I can not create Index on all the columns. Yes, I don't Need ColumnC. I can create Index on Temp Table. Still not much improved
- Small batch updates are usually used to allow other queries to access the table between small updates, instead of locking the table for a long time.
- If the table to be updated has a clustered index on Id then using their method it would only involve one full table scan of the large table to be updated then fast seeks on the clustered key, they might even be able to get it to do an inner merge join on the two tables.
-
Looking at the execution plan images (as we have no actual execution plan to review) your biggest hitters are the DELETE and the INSERT, so I too am wondering if Kaj's approach offers a benefit.
Mind you, a high percentage in an execution plan doesn't mean that it is your biggest performance problem, but without having a plan XML to skim through (and parse in other tools like plan explorer), it is my best guess.
another thought if you are looking for improvements on performance, you will likely get a bit of a performance boost by switching to simple recovery while doing those massive updates. Downside is you will lose the ability to do tlog backups and thus no tlog restores either... You will be working with full backups, so no point in time recovery. A lot more risky, but if the data is possible to recreate (ie you have the source data and don't mind potentially losing all data between full backups) then doing minimal logging of your tlogs me be worth the tradeoff? Just make sure to do a full backup after switching and after any data changes that result in you potentially wanting a point in time restore to that point.
If you need point in time recovery or have a specific RPO already in place for this database, i would NOT switch it to simple recovery, but simple recovery can help with bulk operations like what you are doing there.
The above is all just my opinion on what you should do.
As with all advice you find on a random internet forum - you shouldn't blindly follow it. Always test on a test server to see if there is negative side effects before making changes to live!
I recommend you NEVER run "random code" you found online on any system you care about UNLESS you understand and can verify the code OR you don't care if the code trashes your system.
Viewing 15 posts - 1 through 15 (of 17 total)
You must be logged in to reply to this topic. Login to reply