Unwanted duplicates in random sampling
-
I'm trying to determine why I'm getting several (about 20%) duplicate values in my 'pt.pat_fullname' field. I would think the DISTINCT would work. Any ideas?
drop table if exists #allclaims;
select distinct cl.clm_hdr_id
, cl.clm_dos
, cl.pat_id
into #allclaims
from dbo.vw_claims cl
where cl.clm_dos
between '2022-08-01' and '2022-08-31'
group by cl.clm_hdr_id
, cl.clm_dos
, cl.pat_id
order by cl.pat_id;
select top 500
*
from
(
select distinct
pt.pat_fullname
, cl.clm_hdr_id
, cl.clm_dos as 'Service Date'
from #allclaims cl
inner join dbo.tb_patients pt
on cl.pat_id = pt.pat_id
) as a
order by newid(); -
What is your definition of duplicates in this scenario? Please provide an actual example of multiple rows that comprise a duplicate (obfuscated if necessary).
There should be only one row for any given set/combination of pat_fullname, clm_hdr_id, & "Service Date" from that query.
But it is perfectly valid for it to return the same pat_fullname for various combinations of clm_hdr_id & "Service Date". Such cases would not be duplicates.
-
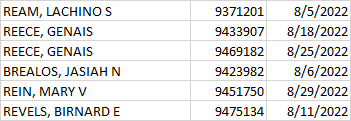
I need for the person's name to be unique. So one of the records for 'Reece, Genais' needs to be eliminated. It doesn't matter which one:

-
I see you have both distinct and group by in the same query - use one or the other, and since you are not using any aggregate functions then you would only need the distinct. You also don't need to include an ORDER BY - that is only valid when you have an IDENTITY column and you need the identity to be assigned based on that order.
Ideally, you would have another column in vw_claims that could be used to identify a single row. If so - then it would be better to use that column instead of using distinct. Given that you are looking for each distinct date of service for a claim - then you can and will get multiple rows per claim. It all depends on how that claim is billed out and the dates of service for each procedure performed.
With that said - there is no reason to insert into a temp table - and then select the top 500. It can all be done in a single query - and selecting from a derived table is just extra typing.
If the desired result is a distinct list of claims per patient - then you need to either remove the DOS or get the min/max date of service. If the desired result is all dates of service by claims per patient - then just use a group by.
select top (500)
pt.pat_fullname
, cl.clm_hdr_id
, max(cl.clm_dos) as 'Service Date'
from dbo.vw_claims cl
inner join dbo.tb_patients pt
on cl.pat_id = pt.pat_id
where cl.clm_dos
between '2022-08-01' and '2022-08-31'
group by cl.clm_hdr_id
, pt.pat_fullname
order by newid();
select top (500)
pt.pat_fullname
, cl.clm_hdr_id
, cl.clm_dos as 'Service Date'
from dbo.vw_claims cl
inner join dbo.tb_patients pt
on cl.pat_id = pt.pat_id
where cl.clm_dos
between '2022-08-01' and '2022-08-31'
group by cl.clm_hdr_id
, pt.pat_fullname
, cl.clm_dos
order by newid();Jeffrey Williams
“We are all faced with a series of great opportunities brilliantly disguised as impossible situations.”― Charles R. Swindoll
How to post questions to get better answers faster
Managing Transaction Logs -
It's funny how people rail against duplicates in a randomly selected set... it's a part of what "random" is.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - DaveBriCam wrote:
I need for the person's name to be unique. So one of the records for 'Reece, Genais' needs to be eliminated. It doesn't matter which one:
Saw this after I posted above - those are not DISTINCT rows. The patient has multiple claims in the selected period - and stating it doesn't matter which one you gets means neither the DOS or claim header ID are important.
select top (500)
pt.pat_fullname
, clm_hdr = max(cl.clm_hdr_id)
, service_date = max(cl.clm_dos)
from dbo.vw_claims cl
inner join dbo.tb_patients pt
on cl.pat_id = pt.pat_id
where cl.clm_dos
between '2022-08-01' and '2022-08-31'
group by pt.pat_fullname
order by newid();Of course, this won't work if you have 2 patients with the same name as one of them would be eliminated. If that is the case, change the group by to group by pt.pat_id.
Jeffrey Williams
“We are all faced with a series of great opportunities brilliantly disguised as impossible situations.”― Charles R. Swindoll
How to post questions to get better answers faster
Managing Transaction Logs - Jeff Moden wrote:
It's funny how people rail against duplicates in a randomly selected set... it's a part of what "random" is.
It's also funny what some people consider duplicates - even when all but one column is different.
Jeffrey Williams
“We are all faced with a series of great opportunities brilliantly disguised as impossible situations.”― Charles R. Swindoll
How to post questions to get better answers faster
Managing Transaction Logs
Viewing 7 posts - 1 through 7 (of 7 total)
You must be logged in to reply to this topic. Login to reply