Trying to Make combinations within a bracket in SSMS column
-
I have a column in SSMS where I am looking to make different combinations. For example I have a column for names such as A[123] where I need to make combinations such as A1, A2 & A3 where the output will be 3 rows instead of 1 (A[123])
can any one help me with this please?
-
Could you provide some DDL for this so we can consume the data and replicate it?
A quick guess here is that you are going to be looking at unpivot or UNION. UNION is likely easier to understand in my opinion so something like:
SELECT
'A1' AS [header]
, [A1] AS [Avalue]
FROM[dbo].
UNION
SELECT
'A2' AS [header]
, [A2] AS [Avalue]
FROM[dbo].
UNION
SELECT
'A3' AS [header]
, [A3] AS [Avalue]
FROM[dbo].;Will result in 3 index scans (or table scans), but should get you what you need. UNPIVOT would likely be more efficient, so something like:
DECLARE @tmp TABLE
(
[A1] INT
, [A2] INT
, [A3] INT
);
INSERT INTO @tmp
(
[A1]
, [A2]
, [A3]
)
VALUES
(
1-- A1 - int
, 2
, 3 -- A3 - int
);
SELECT
[unpvt].[Avalule]
, [unpvt].[header]
FROM
(
SELECT
[A1]
, [A2]
, [A3]
FROM@tmp
) AS [datas]
UNPIVOT
(
[Avalule]
FOR [header] IN (
[A1]
, [A2]
, [A3]
)
) AS [unpvt];UNPIVOT method should be nicer on resources as you don't need to do multiple scans on the table, UNION method might be easier to understand if you are newer to SQL.
The above is all just my opinion on what you should do.
As with all advice you find on a random internet forum - you shouldn't blindly follow it. Always test on a test server to see if there is negative side effects before making changes to live!
I recommend you NEVER run "random code" you found online on any system you care about UNLESS you understand and can verify the code OR you don't care if the code trashes your system. -
Hi Brian, thank you for your response above.
I guess the Header thing will not work here as my data goes something like this :
Column 1
A[kfg]
B[lr]
Cf
D[3r]
Out put required should have, the first letter along with anything in the bracket as combinations in separate rows. if there are no brackets, then it should return me the value as is, such as Ak, Af, Ag, Bl, Br, Cf, D3, Dr
Do you think the above solution will work here in this case?
-
Solution in this case, going back to the UNPIVOT example, basically the same thing, just put more values into the IN statement. In your case replace the FOR [header] IN ( ... ) section of the code with:
FOR [header] IN (
[Ak]
, [Af]
, [Ag]
, [Bl]
, [Br]
, [Cf]
, [D3]
, [Dr]
)Or do I misunderstand this request and it is that your DATA is things like A[kfg] and such NOT column names? If that is the case, my recommendation would be to tackle this at the application side, not the database side. Databases are not really designed for things like this, but applications can do this a lot easier. If that is not an option, you are going to need to do some looping with a cursor.
Before I jump into the cursor solution, I just want to confirm that your data looks like:
DECLARE @tmp TABLE
(
[Letters] VARCHAR(25)
);
INSERT INTO @tmp
(
[Letters]
)
VALUES
(
'A[kfg]'-- Letters - varchar(25)
)
, (
'B[lr]'
)
, (
'Cf'
)
, (
'D[3r]'
);The above is all just my opinion on what you should do.
As with all advice you find on a random internet forum - you shouldn't blindly follow it. Always test on a test server to see if there is negative side effects before making changes to live!
I recommend you NEVER run "random code" you found online on any system you care about UNLESS you understand and can verify the code OR you don't care if the code trashes your system. -

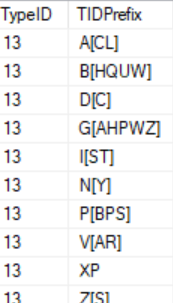
This what the column I am talking about looks like. There are thousands of such column and I need to break them down into multiple rows with combinations i mentioned above, so anything outside the bracket will need to be combined with every letter individually inside the bracket. if there is no bracket, then it goes as is. for example as you can see from the table above, the value XP will be as is in the row as there are no brackets to make any combination.
-
My recommendation is to do this application side still, but if database side is the solution you need, this query should do it:
DECLARE @tmp TABLE
(
[Letters] VARCHAR(25)
);
INSERT INTO @tmp
(
[Letters]
)
VALUES
(
'A[kfg]'-- Letters - varchar(25)
)
, (
'B[lr]'
)
, (
'Cf'
)
, (
'D[3r]'
);
DECLARE @letter VARCHAR(25);
DECLARE @startLetter CHAR(1);
DECLARE @result TABLE
(
[Letters] CHAR(2)
);
DECLARE [cursewords] CURSOR LOCAL FAST_FORWARD FOR
SELECT
[Letters]
FROM@tmp;
OPEN [cursewords];
FETCH NEXT FROM [cursewords]
INTO
@letter;
WHILE @@FETCH_STATUS = 0
BEGIN
SELECT
@startLetter = LEFT(@letter, 1);
IF (CHARINDEX( '['
, @letter
)
) = 0
BEGIN
INSERT INTO @result
VALUES
(
@letter
);
END;
ELSE
BEGIN
DECLARE @endValue INT;
DECLARE @counter INT = 2;
SELECT
@endValue = CHARINDEX( ']'
, @letter
) - 1;
WHILE @counter < @endValue
BEGIN
SELECT
@counter = @counter + 1;
INSERT INTO @result
(
[Letters]
)
SELECT
@startLetter + RIGHT(LEFT(@letter, @counter), 1);
END;
END;
FETCH NEXT FROM [cursewords]
INTO
@letter;
END;
SELECT
[Letters]
FROM@result;The reason I don't like this in the database side is it becomes a ROW based operation rather than a SET based operation. What I mean here is that it is going to be slow. SQL doesn't like working on ROW based operations which is why you should try to avoid loops (while and cursor) and that query needs 2. It is the "if all you own is a hammer, every problem looks like a nail" solution.
Now, doing this application side will put little strain on the SQL server as you just need to pull the data in to the application and then manipulate it as you need. Applications are better at working with loops and this puts no strain on any server; just on the client machine.
The above is all just my opinion on what you should do.
As with all advice you find on a random internet forum - you shouldn't blindly follow it. Always test on a test server to see if there is negative side effects before making changes to live!
I recommend you NEVER run "random code" you found online on any system you care about UNLESS you understand and can verify the code OR you don't care if the code trashes your system. -
What application would you suggest using for this, If i were to run row operations on the application side?
-
Here's a set-based solution.
DROP TABLE IF EXISTS #x;
CREATE TABLE #x
(
SomeText VARCHAR(100)
);
INSERT #x
(
SomeText
)
VALUES
('A[CL]')
,('B[HQUW]');
SELECT *
FROM #x x;
WITH Tally (N) AS
(
-- 8000 rows (max length of the VARCHAR string)
SELECT ROW_NUMBER() OVER (ORDER BY (SELECT NULL))
FROM (VALUES(0),(0),(0),(0),(0),(0),(0),(0),(0),(0)) a(n)
CROSS JOIN (VALUES(0),(0),(0),(0),(0),(0),(0),(0),(0),(0)) c(n)
CROSS JOIN (VALUES(0),(0),(0),(0),(0),(0),(0),(0),(0),(0)) d(n)
CROSS JOIN (VALUES(0),(0),(0),(0),(0),(0),(0),(0)) e(n)
)
SELECT x.SomeText
,Combo = CONCAT(LEFT(x.SomeText, calcs.StartPos - 1), SUBSTRING(x.SomeText, t.N + calcs.StartPos, 1))
FROM #x x
CROSS JOIN Tally t
CROSS APPLY
(
SELECT StartPos = CHARINDEX('[', x.SomeText)
,EndPos = CHARINDEX(']', x.SomeText)
) calcs
WHERE t.N <= calcs.EndPos - calcs.StartPos - 1
ORDER BY x.SomeText
,t.N; -
Yet another handy use of a tally table.
drop table if exists dbo.test_TID;
go
create table dbo.test_TID(
TIDPrefix varchar(20) not null);
insert dbo.test_TID(TIDPrefix) values
('A[123xyz]'),
('x[UY345]');
select
tt.TIDPrefix,
concat(left(tt.TIDPrefix,1), substring(tt.TIDPrefix, n+2, 1))
from
dbo.test_TID tt
cross apply
fnTally(1,len(tt.TIDPrefix)-3) t
where
tt.TIDPrefix like '%/[%/]' escape '/';Aus dem Paradies, das Cantor uns geschaffen, soll uns niemand vertreiben können
-
What application consumes this data? The application that is consuming this data is the application I would use to parse it.
If it is to be consumed in Excel, then I'd use Excel to handle it. If it is SSRS, then I'd use SSRS. If it is some home-grown .NET application, then that .NET application.
If the application that is consuming the data can't handle that format, then I would be looking at the application that creates that data and have that push it into the database in the same format it is to be consumed.
If that is not possible, PowerShell can handle this, bat files can handle this (not as nice as powershell mind you), bash scripts, .NET, Excel, etc. It really depends on what you are comfortable working with and how the consuming application takes its input.
I don't think you will find any magic application that you can just give it some input like what you have there and it will give you the output you expect without some form of customization and then it just comes down to what methods of customization are you comfortable working with and where are you comfortable having the workload reside. Maybe the table is small and doing 2 loops in SQL is the best option; maybe you are only running this once per year during slow server times so SQL is an acceptable option. If the table is small and will never ever be large, SQL may be an acceptable answer to your problem.
It also depends on what you are doing with the data once you get it. Does it get exported to a flat file? Is it a query that you are writing for a stored procedure to be called by an application? Is it a Database Developer thought task that will never be used in a production environment? etc.
If one of my application developers asked me for that, I would tell them "here is the data as provided by application XYZ. Parsing this data inside SQL to the format you require is not a good use of server resources. Please parse the data in your application layer." The other advantage of pushing back to the application team is they sometimes change the requirements without thinking of the database side. What if in the future they decide to add in A[a:g] and expect the database to understand that that should include Aa, Ab, Ac, Ad, Ae, Af, and Ag but don't tell you? Now your nice query needs to handle additional requirements (ranges) and you have just introduced a 3rd loop. And what if they introduce ranges AND exclusions like A[a:g^f] which would give the same range as above, but exclude f? Another loop. Eventually the application team will come back and tell you the SQL query is too slow, make it faster and the only way to make it faster is to remove requirements on those loops or reduce the number of rows you are doing the loops on (ie reduce the scope).
Doing those sorts of things inside C# is fairly trivial and with multithreading, can be quite quick to go through even very large lists.
The above is all just my opinion on what you should do.
As with all advice you find on a random internet forum - you shouldn't blindly follow it. Always test on a test server to see if there is negative side effects before making changes to live!
I recommend you NEVER run "random code" you found online on any system you care about UNLESS you understand and can verify the code OR you don't care if the code trashes your system. -
Can we do anything with String Split function?
-
Can we do anything with String Split function Phil?
-
String Split won't work here as you have no delimiter on your strings.
Something to add to the TALLY solutions proposed above is that they miss the cases where there is no [ and ] in it. So you'll need to add those values back in afterwards (UNION SELECT * FROM TABLE WHERE column NOT LIKE '%[%]' perhaps?).
Also, Phil, your query is dropping the last character. So if the input was A[bcd], your results are Ab and Ac but Ad is missed (at least on my SQL Server 2016 box).
The above is all just my opinion on what you should do.
As with all advice you find on a random internet forum - you shouldn't blindly follow it. Always test on a test server to see if there is negative side effects before making changes to live!
I recommend you NEVER run "random code" you found online on any system you care about UNLESS you understand and can verify the code OR you don't care if the code trashes your system. -
Also Brian, can we think about breaking this string down into various columns such as A[bcd] will be broken down to A,[,b,c,d,].... and then we cross apply A with all others ?
would that work?
- Mr. Brian Gale wrote:
String Split won't work here as you have no delimiter on your strings.
Something to add to the TALLY solutions proposed above is that they miss the cases where there is no [ and ] in it. So you'll need to add those values back in afterwards (UNION SELECT * FROM TABLE WHERE column NOT LIKE '%[%]' perhaps?).
Also, Phil, your query is dropping the last character. So if the input was A[bcd], your results are Ab and Ac but Ad is missed (at least on my SQL Server 2016 box).
select
tt.TIDPrefix,
iif(tt.TIDPrefix like '%/[%/]' escape '/', concat(left(tt.TIDPrefix,1), substring(tt.TIDPrefix, n+2, 1)), tt.TIDPrefix)
from
dbo.test_TID tt
cross apply
fnTally(1, iif(tt.TIDPrefix like '%/[%/]' escape '/', len(tt.TIDPrefix)-3, 1)) t;Aus dem Paradies, das Cantor uns geschaffen, soll uns niemand vertreiben können
Viewing 15 posts - 1 through 15 (of 72 total)
You must be logged in to reply to this topic. Login to reply