There and back again: From a partition number to a filegroup and vice versa
-
I've been trying to navigate the DMVs concerning partitions and filegroups and find my way between them. I might have a partition number and want the filegroup name(s) (and ultimately the files in the group). Or, I might have a filegroup or filename and want the partition(s) that it holds.
Here's my test case:
USE master;
DROP DATABASE IF EXISTS TestParts;
CREATE DATABASE TestParts
ALTER DATABASE TestParts ADD FILEGROUP FG1
ALTER DATABASE TestParts ADD FILEGROUP FG2
ALTER DATABASE TestParts ADD FILEGROUP FG3
ALTER DATABASE TestParts ADD FILE (NAME=File1, FILENAME = 'C:\temp\File1.ndf', SIZE = 1MB) TO FILEGROUP FG1
ALTER DATABASE TestParts ADD FILE (NAME=File2, FILENAME = 'C:\temp\File2.ndf', SIZE = 1MB) TO FILEGROUP FG2
ALTER DATABASE TestParts ADD FILE (NAME=File3, FILENAME = 'C:\temp\File3.ndf', SIZE = 1MB) TO FILEGROUP FG3Now, create a partitioned table:
USE TestParts
CREATE PARTITION FUNCTION [My_PF](int) AS RANGE LEFT FOR VALUES (1000, 2000, 3000)
CREATE PARTITION SCHEME [My_PS] AS PARTITION [My_PF] TO (FG1, FG2, FG3, [PRIMARY])
CREATE TABLE dbo.test (a int NOT NULL) ON My_PS(a)
INSERT INTO dbo.test (a)
VALUES (1), (1001), (2001), (3001), (4001)Then you can query the DMVs for interesting things:
SELECT * FROM sys.partition_schemes ps WHERE ps.name = 'My_PS'
SELECT * FROM sys.partition_functions pf WHERE pf.name = 'My_PF'
SELECT * FROM sys.partition_range_values WHERE function_id = (
SELECT pf.function_id FROM sys.partition_functions pf WHERE pf.name = 'My_PF')
SELECT * FROM sys.filegroups fg
SELECT * FROM sys.database_files dbf
SELECT * FROM sys.data_spaces ds
SELECT * FROM sys.destination_data_spacesThere is a built-in "magic" function that you can use to get the partition number for some value supplied to the partition function:
SELECT $Partition.my_pf(1)
(Too bad Intellisense still doesn't understand this syntax)
Now, suppose you have the partition number from the magic function and want to find the corresponding filgroup and file.
I have a query that is partly obvious and partly not:
-- Obvious ?
SELECT ps.name PartitionScheme, pf.name PartitionFuntion, fg.name FileGroup, dbf.name SQL_FileName, dbf.physical_name FilePath
FROM sys.partition_schemes ps
JOIN sys.partition_functions pf
ON pf.function_id = ps.function_id
JOIN sys.partition_range_values prv
-- From https://docs.microsoft.com/en-us/sql/relational-databases/system-catalog-views/sys-partition-range-values-transact-sql
-- Column name Data type Description
-- function_id int ID of the partition function for this range boundary value.
-- boundary_id int ID (1-based ordinal) of the boundary value tuple, with left-most boundary starting at an ID of 1.
-- parameter_id int ID of the parameter of the function to which this value corresponds. The values in this column correspond with those in the
-- parameter_id column of the sys.partition_parameters catalog view for any particular function_id.
-- value sql_variant The actual boundary value.
ON prv.function_id = ps.function_id
JOIN sys.data_spaces ds
ON ds.data_space_id = ps.data_space_id
-- Not so obvious ?
JOIN sys.destination_data_spaces dds
-- From https://docs.microsoft.com/en-us/sql/relational-databases/system-catalog-views/sys-destination-data-spaces-transact-sql
-- Column name Data type Description
-- partition_scheme_id int ID of the partition-scheme that is partitioning to the data space.
-- destination_id int ID (1-based ordinal) of the destination-mapping, unique within the partition scheme.
-- data_space_id int ID of the data space to which data for this schemes destination is being mapped.
ON dds.destination_id = prv.boundary_id -- this is not obvious, at least to me. Is it correct?
AND dds.partition_scheme_id = ps.data_space_id -- also not obvious to me
-- Obvious again
JOIN sys.filegroups fg
ON fg.data_space_id = dds.data_space_id
JOIN sys.database_files dbf
ON dbf.data_space_id = fg.data_space_id
-- Obvious
WHERE ps.name = 'My_PS' AND pf.name = 'My_PF'
-- Not obvious
AND dds.destination_id = $Partition.my_pf(2001) -- not obvious to me. Is it correct?The only thing sys.partition_range_values seems to have in common with sys.destination_data_spaces is that they both refer to "1-based ordinal".
Doing a google search on
"1-based ordinal" site:https://docs.microsoft.com/en-us/sql
there are only 5 hits and only 2 are related to partitions and data spaces. That's what has led me to guess that these may be the right join columns, but I'm still not sure since the documentation doesn't seem to make that connection. FWIW the doc for $PARTITION seems to lean in this direction, though not as clear as I would like
$PARTITION Returns the partition number into which a set of partitioning column values would be mapped for any specified partition function in SQL Server. It returns the partition number for any valid value, regardless of whether the value currently exists in a partitioned table or index that uses the partition function.
Can someone verify or refute the inference I'm drawing? If I'm off track, how would you map a partition id to a filegroup name?
- This topic was modified 4 years, 11 months ago by .
- This topic was modified 4 years, 11 months ago by .
Gerald Britton, Pluralsight courses
-
-- http://www.davidemauri.it/DasBlog/CategoryView,category,Sql%20Server%202005.aspx
--create schema ALZDBA
/* Welke query(s) uitvoeren ? */
Declare @WelkeQuery int
/* 0 = alles , (1,2,3,4,5) is enkel die query */
set @WelkeQuery = 4
if @WelkeQuery in ( 1, 0 )
begin
print 'Q 1' ;
/* CREATE view [ALZDBA].[V_partitioned_objects]
as
*/
select distinct
p.[object_id]
, OBJECT_SCHEMA_NAME(p.[object_id]) AS TbSchemaName
, TbName = OBJECT_NAME(p.[object_id])
, index_name = i.[name]
, index_type_desc = i.type_desc
, partition_scheme = ps.[name]
, data_space_id = ps.data_space_id
, function_name = pf.[name]
, function_id = ps.function_id
from sys.partitions p
inner join sys.indexes i
on p.[object_id] = i.[object_id]
and p.index_id = i.index_id
inner join sys.data_spaces ds
on i.data_space_id = ds.data_space_id
inner join sys.partition_schemes ps
on ds.data_space_id = ps.data_space_id
inner JOIN sys.partition_functions pf
on ps.function_id = pf.function_id
order by TbName
, TbSchemaName
, index_type_desc
, index_name ;
-- That ALZDBA.V_partitioned_object views is very useful to see how a table has been partitioned:
end
/*
select *
from ALZDBA.V_partitioned_objects
--where [object_id] = object_id('table_name')
*/
if @WelkeQuery in ( 2, 0 )
begin
print 'Q 2' ;
-- with the above query will list table and related indexes partition information.
-- Once you know what partition scheme and function the table and related indeexes uses for partitioning you may also what to see how many partition actually exists, what range values are used and so on.
-- This view will help you:
/*
create view [ALZDBA].[V_partitioned_objects_range_values]
as
*/
select p.[object_id]
, OBJECT_SCHEMA_NAME(p.[object_id]) AS TbSchemaName
, OBJECT_NAME(p.[object_id]) AS TbName
, p.index_id
, p.partition_number
, p.rows
, index_name = i.[name]
, index_type_desc = i.type_desc
, i.data_space_id
, ds1.NAME AS [FILEGROUP_NAME]
, pf.function_id
, pf.[name] AS Pf_Name
, pf.type_desc
, pf.boundary_value_on_right
, destination_data_space_id = dds.destination_id
, prv.parameter_id
, prv.value
from sys.partitions p
inner join sys.indexes i
on p.[object_id] = i.[object_id]
and p.index_id = i.index_id
inner JOIN sys.data_spaces ds
on i.data_space_id = ds.data_space_id
inner JOIN sys.partition_schemes ps
on ds.data_space_id = ps.data_space_id
inner JOIN sys.partition_functions pf
on ps.function_id = pf.function_id
inner join sys.destination_data_spaces dds
on dds.partition_scheme_id = ds.data_space_id
and p.partition_number = dds.destination_id
INNER JOIN sys.data_spaces ds1
on ds1.data_space_id = dds.data_space_id
left outer JOIN sys.partition_range_values prv
on prv.function_id = ps.function_id
and p.partition_number = prv.boundary_id
-- where i.index_id = 1
order by TbName
, TbSchemaName
, index_type_desc
, index_name
, p.partition_number ;
end
-- To use it, just use as the one showed before:
/*
select *
from ALZDBA.V_partitioned_objects_range_values
-- where object_id = object_id('OrderDetails')
-- The query will produce a list with all partitions and all range values for the object 'table_name'
-- I've put my "system" views into a schema named ALZDBA, so be sure to create it or change that create view statement to create views in your own schema.
*/
if @WelkeQuery in ( 3, 0 )
begin
print 'Q 3' ;
-- Written by Kalen Delaney, 2008
-- with a few nice enhancements by Chad Crawford, 2009
--CREATE VIEW Partition_Info AS
SELECT OBJECT_SCHEMA_NAME(p.[object_id]) AS TbSchemaName
, OBJECT_NAME(i.object_id) as Object_Name
, i.name AS Index_Name
, p.partition_number
, fg.name AS Filegroup_Name
, rows
, au.total_pages
, au.total_pages * 8 / 1024 total_MB
, CASE boundary_value_on_right
WHEN 1 THEN 'less than'
ELSE 'less than or equal to'
END as 'comparison'
, rv.value
, CASE WHEN ISNULL(rv.value, rv2.value) IS NULL THEN 'N/A'
ELSE CASE WHEN boundary_value_on_right = 0
AND rv2.value IS NULL THEN 'Greater than or equal to'
WHEN boundary_value_on_right = 0 THEN 'Greater than'
ELSE 'Greater than or equal to'
END + ' ' + ISNULL(CONVERT(varchar(15), rv2.value), 'Min Value') + ' ' + CASE boundary_value_on_right
WHEN 1 THEN 'and less than'
ELSE 'and less than or equal to'
END + ' ' + +ISNULL(CONVERT(varchar(15), rv.value), 'Max Value')
END as 'TextComparison'
FROM sys.partitions p
INNER JOIN sys.indexes i
ON p.object_id = i.object_id
and p.index_id = i.index_id
LEFT JOIN sys.partition_schemes ps
ON ps.data_space_id = i.data_space_id
LEFT JOIN sys.partition_functions f
ON f.function_id = ps.function_id
LEFT JOIN sys.partition_range_values rv
ON f.function_id = rv.function_id
AND p.partition_number = rv.boundary_id
LEFT JOIN sys.partition_range_values rv2
ON f.function_id = rv2.function_id
AND p.partition_number - 1 = rv2.boundary_id
LEFT JOIN sys.destination_data_spaces dds
ON dds.partition_scheme_id = ps.data_space_id
AND dds.destination_id = p.partition_number
LEFT JOIN sys.filegroups fg
ON dds.data_space_id = fg.data_space_id
INNER JOIN sys.allocation_units au
ON au.container_id = p.partition_id
WHERE i.index_id < 2
AND au.type = 1
-- and OBJECT_NAME(i.[object_id]) like 'T%'
-- Example of use:
--SELECT * FROM Partition_Info
--WHERE Object_Name = 'charge'
ORDER BY Object_Name
, OBJECT_SCHEMA_NAME(p.[object_id])
, partition_number ;
end
if @WelkeQuery in ( 4, 0 )
begin
print 'Q 4' ;
/* Show range values per partition on the clustering index */
;
with ctePartRangesFULL
as (
select distinct
p.[object_id]
, OBJECT_SCHEMA_NAME(p.[object_id]) as TbSchema
, OBJECT_NAME(p.[object_id]) as TbName
, p.index_id
, i.name as IxName
, p.partition_number
, p.rows
, au.total_pages
, prv.value as Boundary_Value
, ds1.NAME AS [FILEGROUP_NAME]
, pf.boundary_value_on_right
, au.type
, au.type_desc
from sys.partitions p
inner join sys.indexes i
on p.[object_id] = i.[object_id]
and p.index_id = i.index_id
inner JOIN sys.data_spaces ds
on i.data_space_id = ds.data_space_id
inner JOIN sys.partition_schemes ps
on ds.data_space_id = ps.data_space_id
inner JOIN sys.partition_functions pf
on ps.function_id = pf.function_id
inner join sys.destination_data_spaces dds
on dds.partition_scheme_id = ds.data_space_id
and p.partition_number = dds.destination_id
INNER JOIN sys.data_spaces ds1
on ds1.data_space_id = dds.data_space_id
INNER JOIN sys.allocation_units au
ON au.container_id = p.partition_id
left outer JOIN sys.partition_range_values prv
on prv.function_id = ps.function_id
and p.partition_number = prv.boundary_id
WHERE p.index_id = 1
)
, ctePartRangesTot as (
Select [object_id]
, index_id
, partition_number
, sum( total_pages ) as TotalPages
from ctePartRangesFULL
group by [object_id]
, index_id
, partition_number
)
Select R1.[object_id]
, R1.TbSchema
, R1.TbName
, R1.index_id
, R1.IxName
, R1.partition_number
, R1.rows
, T.TotalPages
, T.TotalPages * 8 / 1024 total_MB
, R2.Boundary_Value as LEFT_Boundary_Value
, R1.Boundary_Value
, R1.[FILEGROUP_NAME]
, R1.boundary_value_on_right
, CASE R1.boundary_value_on_right
WHEN 1 THEN '<'
ELSE '<='
END as 'Boundary_Comparison'
, CASE WHEN ISNULL(R1.Boundary_Value, R2.Boundary_Value) IS NULL THEN 'N/A'
ELSE CASE WHEN R1.boundary_value_on_right = 0
AND R2.Boundary_Value IS NULL THEN '>='
WHEN R1.boundary_value_on_right = 0 THEN '>'
ELSE '>='
END + ' [' + ISNULL(CONVERT(varchar(128), R2.Boundary_Value), 'Min. Value') + '] ' + CASE R1.boundary_value_on_right
WHEN 1 THEN 'and <'
ELSE 'and <='
END + ' [' + ISNULL(CONVERT(varchar(128), R1.Boundary_Value), 'Max. Value') + ']'
END as 'Boundary_Expression'
from ctePartRangesFULL R1
left join ctePartRangesFULL R2
on R2.object_id = R1.object_id
and R2.index_id = R1.index_id
and R2.type = R1.type
and R2.partition_number = R1.partition_number - 1
inner join ctePartRangesTot T
on T.object_id = R1.object_id
and T.index_id = R1.index_id
and T.partition_number = R1.partition_number
where R1.type = 1
order by TbSchema
, TbName
, index_id
, partition_number ;
end
if @WelkeQuery in ( 5, 0 )
begin
print 'Q 5' ;
/* Show range values per partition on the clustering index */
;
with ctePartRanges
as (
select distinct
p.[object_id]
, OBJECT_SCHEMA_NAME(p.[object_id]) as TbSchema
, OBJECT_NAME(p.[object_id]) as TbName
, p.index_id
, i.name as IxName
, p.partition_number
, p.rows
, au.total_pages
, prv.value as Boundary_Value
, ds1.NAME AS [FILEGROUP_NAME]
, pf.boundary_value_on_right
, au.type
, au.type_desc
from sys.partitions p
inner join sys.indexes i
on p.[object_id] = i.[object_id]
and p.index_id = i.index_id
inner JOIN sys.data_spaces ds
on i.data_space_id = ds.data_space_id
inner JOIN sys.partition_schemes ps
on ds.data_space_id = ps.data_space_id
inner JOIN sys.partition_functions pf
on ps.function_id = pf.function_id
inner join sys.destination_data_spaces dds
on dds.partition_scheme_id = ds.data_space_id
and p.partition_number = dds.destination_id
INNER JOIN sys.data_spaces ds1
on ds1.data_space_id = dds.data_space_id
INNER JOIN sys.allocation_units au
ON au.container_id = p.partition_id
left outer JOIN sys.partition_range_values prv
on prv.function_id = ps.function_id
and p.partition_number = prv.boundary_id
WHERE p.index_id = 1
)
Select R1.[object_id]
, R1.TbSchema
, R1.TbName
, R1.index_id
, R1.IxName
, R1.partition_number
, R1.rows
, R1.total_pages
, R1.total_pages * 8 / 1024 total_MB
, R1.type
, R1.type_desc
, R2.Boundary_Value as LEFT_Boundary_Value
, R1.Boundary_Value
, R1.[FILEGROUP_NAME]
, R1.boundary_value_on_right
, CASE R1.boundary_value_on_right
WHEN 1 THEN '<'
ELSE '<='
END as 'Boundary_Comparison'
, CASE WHEN ISNULL(R1.Boundary_Value, R2.Boundary_Value) IS NULL THEN 'N/A'
ELSE CASE WHEN R1.boundary_value_on_right = 0
AND R2.Boundary_Value IS NULL THEN '>='
WHEN R1.boundary_value_on_right = 0 THEN '>'
ELSE '>='
END + ' [' + ISNULL(CONVERT(varchar(128), R2.Boundary_Value), 'Min. Value') + '] ' + CASE R1.boundary_value_on_right
WHEN 1 THEN 'and <'
ELSE 'and <='
END + ' [' + ISNULL(CONVERT(varchar(128), R1.Boundary_Value), 'Max. Value') + ']'
END as 'Boundary_Expression'
from ctePartRanges R1
left join ctePartRanges R2
on R2.object_id = R1.object_id
and R2.index_id = R1.index_id
and R2.type = R1.type
and R2.partition_number = R1.partition_number - 1
-- where R1.type = 1
order by TbSchema
, TbName
, index_id
, partition_number
, type ;
end
if @WelkeQuery = 0
begin
print 'Q 6' ;
Select PS.*,PF.name as PartitionFunctionName
from sys.partition_functions PF
inner join sys.partition_schemes PS
on PS.function_id = PF.function_id
order by PF.name, PS.name ;
Select *
from sys.partition_functions PF
order by PF.name ;
Select PF.name, PRV.*
from sys.partition_functions PF
inner join sys.partition_range_values PRV
on PRV.function_id = PF.function_id
Order by PF.name , PRV.boundary_id ;
SELECT PF.name AS PartitionedFunctionName
, PP.*
, baset.name AS [DataType]
FROM sys.partition_functions AS PF
INNER JOIN sys.partition_parameters AS PP
ON PP.function_id = PF.function_id
INNER JOIN sys.types AS st
ON st.system_type_id = st.user_type_id
and PP.system_type_id = st.system_type_id
LEFT OUTER JOIN sys.types AS baset
ON ( baset.user_type_id = PP.system_type_id
and baset.user_type_id = baset.system_type_id
)
or ( ( baset.system_type_id = PP.system_type_id )
and ( baset.user_type_id = PP.user_type_id )
and ( baset.is_user_defined = 0 )
and ( baset.is_assembly_type = 1 )
)
ORDER BY PF.name , PP.parameter_id;
endJohan
Learn to play, play to learn !Dont drive faster than your guardian angel can fly ...
but keeping both feet on the ground wont get you anywhere :w00t:- How to post Performance Problems
- How to post data and code to get the best help- How to prevent a sore throat after hours of presenting ppt
press F1 for solution, press shift+F1 for urgent solution 😀
Who am I ? Sometimes this is me but most of the time this is me
-
Bedankt Johan! (Ik neem aan dat je het nederlands verstaat). Your code is certainly helpful! I'm still stuck with the basic question, though. e.g. in your code you have a section like this:
and p.partition_number = dds.destination_id
INNER JOIN sys.data_spaces ds1
on ds1.data_space_id = dds.data_space_id
left outer JOIN sys.partition_range_values prv
on prv.function_id = ps.function_id
and p.partition_number = prv.boundary_idThis gets to the heart of the matter. I'm looking for definitive documentation that can confirm or refute this equality:
sys.partitions.partition_number = sys.destination_data_spaces.destination_id = sys.partition_range_values.boundary_id = $PARTITION.<partition_function>(<partition_value>)
for any given partition scheme and partition value. It certainly seems like that is true, but the documentation on the DMVs and the $PARTITION function are not clear on this, at least not to me.
Gerald Britton, Pluralsight courses
-
Even opletten :
prv.value is a boundary value, left or right according to your partitioning definition.
It is the tipping point to put data in the next partition. ( in case of right boundary )
So, in case of boundary_value_on_right, you should present the boundary value " -1 " to get the partition that old values to the left of that boundary value ( smaller than )
In my example it is a datetime value, so I subtract 3ms to figure out the partition that has that value tipping point to its next.
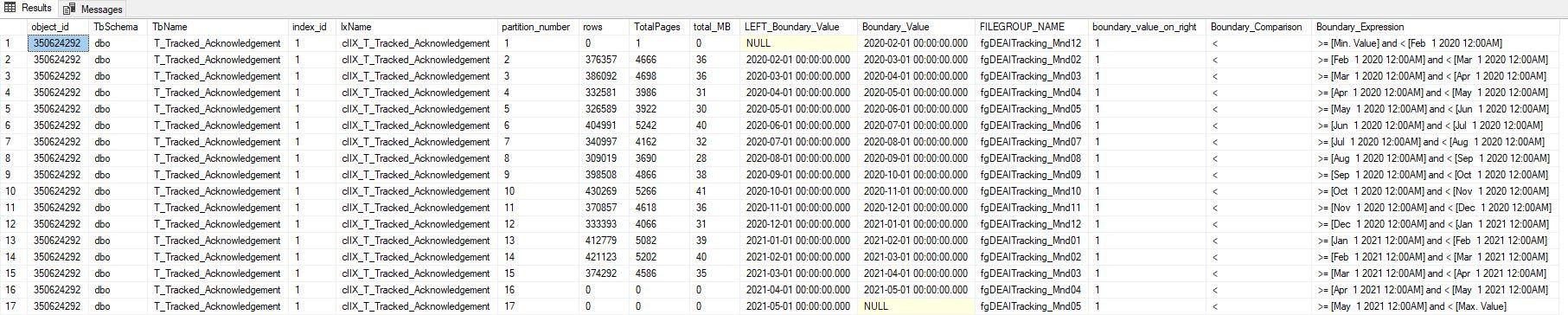
select distinct $PARTITION.pfYearMonth( dateadd(ms,-3,convert(datetime,prv.value,121))) RightBoundaryValue,
p.[object_id]
, OBJECT_SCHEMA_NAME(p.[object_id]) as TbSchema
, OBJECT_NAME(p.[object_id]) as TbName
, p.index_id
, i.name as IxName
, p.partition_number
, p.rows
, au.total_pages
, prv.value as Boundary_Value
, ds1.NAME AS [FILEGROUP_NAME]
, pf.boundary_value_on_right
, au.type
, au.type_desc
from sys.partitions p
inner join sys.indexes i
on p.[object_id] = i.[object_id]
and p.index_id = i.index_id
inner JOIN sys.data_spaces ds
on i.data_space_id = ds.data_space_id
inner JOIN sys.partition_schemes ps
on ds.data_space_id = ps.data_space_id
inner JOIN sys.partition_functions pf
on ps.function_id = pf.function_id
inner join sys.destination_data_spaces dds
on dds.partition_scheme_id = ds.data_space_id
and p.partition_number = dds.destination_id
INNER JOIN sys.data_spaces ds1
on ds1.data_space_id = dds.data_space_id
INNER JOIN sys.allocation_units au
ON au.container_id = p.partition_id
left outer JOIN sys.partition_range_values prv
on prv.function_id = ps.function_id
and p.partition_number = prv.boundary_id
WHERE p.index_id = 1
-- just for my table
and p.[object_id] = 350624292
/*
This gets to the heart of the matter. I'm looking for definitive documentation that can confirm or refute this equality:
*/
and p.partition_number = dds.destination_id
and dds.destination_id = prv.boundary_id
and prv.boundary_id = $PARTITION.pfYearMonth( dateadd(ms,-3,convert(datetime,prv.value,121)))
/*
for any given partition scheme and partition value.
It certainly seems like that is true, but the documentation on the DMVs and the $PARTITION function are not clear on this, at least not to me.
*/
Ref ms doc: "Create partition function"
Ref ms doc "Create Partitioned Tables and Indexes" topic "To determine the boundary values for a partitioned table"
Johan
Learn to play, play to learn !Dont drive faster than your guardian angel can fly ...
but keeping both feet on the ground wont get you anywhere :w00t:- How to post Performance Problems
- How to post data and code to get the best help- How to prevent a sore throat after hours of presenting ppt
press F1 for solution, press shift+F1 for urgent solution 😀
Who am I ? Sometimes this is me but most of the time this is me
-
Zeker weten! I understand what the boundary value is and does. For the purpose of the post here, I'm looking for something else:
I'm looking for definitive documentation that can confirm or refute this equality:
sys.partitions.partition_number
= sys.destination_data_spaces.destination_id
= sys.partition_range_values.boundary_id
= $PARTITION.<partition_function>(<partition_value>)for any given partition scheme, function and partition value. It certainly seems like that is true, but the documentation on the DMVs and the $PARTITION function are not clear on this, at least not to me.
This is key to navigate from a partitioning value or partition number to the filegroup that holds that partition's data.
Gerald Britton, Pluralsight courses
-
- they tie together, right
/* https://docs.microsoft.com/en-us/sql/relational-databases/partitions/create-partitioned-tables-and-indexes */
-- Creates a partition function called myRangePF1 that will partition a table into four partitions
CREATE PARTITION FUNCTION myRangePF1 (int)
AS RANGE LEFT FOR VALUES (1, 100, 1000) ;
GO
-- Creates a partition scheme called myRangePS1 that applies myRangePF1 to the four filegroups created above
CREATE PARTITION SCHEME myRangePS1
AS PARTITION myRangePF1
TO (test1fg, test2fg, test3fg, test4fg) ;
GO
-- Creates a partitioned table called PartitionTable that uses myRangePS1 to partition col1
CREATE TABLE PartitionTable (col1 int PRIMARY KEY, col2 char(10))
ON myRangePS1 (col1) ;
GO
It would not work if the function determined otherwise !
Keep in mind a datetime data type has a tollerance of 3ms !
Johan
Learn to play, play to learn !Dont drive faster than your guardian angel can fly ...
but keeping both feet on the ground wont get you anywhere :w00t:- How to post Performance Problems
- How to post data and code to get the best help- How to prevent a sore throat after hours of presenting ppt
press F1 for solution, press shift+F1 for urgent solution 😀
Who am I ? Sometimes this is me but most of the time this is me
-
Thanks for the confirmation! Now only if the documentation was clearer? e.g.
SYS.DESTINATION_DATA_SPACES (TRANSACT-SQL)
Column name Data typeDescription
partition_scheme_idint ID of the partition-scheme that is partitioning to the data space.
destination_idintID (1-based ordinal) of the destination-mapping, unique within the partition scheme.
data_space_idintID of the data space to which data for this scheme's destination is being mapped.and
SYS.PARTITION_RANGE_VALUES (TRANSACT-SQL)
Column nameData typeDescription
function_idint ID of the partition function for this range boundary value.
boundary_idint ID (1-based ordinal) of the boundary value tuple, with left-most boundary starting at an ID of 1.
parameter_idint ID of the parameter of the function to which this value corresponds. The values in this column correspond with those in the parameter_id column of the sys.partition_parameters catalog view for any particular function_id.
value sql_variantThe actual boundary value.Now, since destination_id and boundary_id are both 1-based ordinals, albeit with different descriptions, and since the partition scheme ties the two together, it seems they must indeed be the same and the equality must hold. I have a feeling we've all been counting on this equality even though it is not explicitly stated. (And without the equality, there is IIUC no other known way to start with a partition key and find the corresponding filegroup.) I'm going to try to submit a PR for the documentation of each DMV to make the connection explicit and see if it is accepted.
PS. the keys I work with are all integers, never datetime. Sometimes we derive the integer from a datetime, like key =year*100+month or similar.
PPS. PR submitted https://github.com/MicrosoftDocs/sql-docs/pull/6232
Gerald Britton, Pluralsight courses
-
Let us know how that PR works out, George. I've got a bunch of places where I found errors, need better examples, or is missing information. I've frequently been seriously disappointed in the going-on with the old "Connect" / new "Feedback" sites for SQL Server and have been "trained" to know it's frequently a waste of time there and, unfortunately, that may have formed a bad "opinion" about the documentation feedback that isn't deserved.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
@jeff-moden LOL. I did get an email ack:
@gbritton1 : Thanks for your contribution! The author(s) have been notified to review your proposed change.
(It's Gerald btw)
Gerald Britton, Pluralsight courses
-
Microsoft *did* look at the PR and we had some back and forth on it. Ultimately it was rejected since my sample query and others like it have a join predicate like this:
sys.destination_data_spaces.destination_id = partitionnumber
However, the Microsoft reviewer replied:
I don't see that your sample query works all of the time. In my lab environment, I found it only worked for all but the last range of values. It appears to equate destination_id to partition_id, which shouldn't work because there are more partitions than destinations. In a function RANGE RIGHT FOR VALUES (-1,0,1), you will get 4 partition numbers and 3 destinations
Indeed, that is easy to set up. Something like this will do it:
CREATE DATABASE test
ALTER DATABASE test ADD FILEGROUP pfg
ALTER DATABASE test ADD FILE (NAME=pfg, FILENAME = 'C:\Users\<userid>\pfg.ndf') TO FILEGROUP pfg
CREATE PARTITION SCHEME ps AS PARTITION pf TO (pfg,pfg,pfg,pfg)
CREATE TABLE testp (a int) ON ps(a)
INSERT INTO testp (a) VALUES (-2),(-1), (0), (1), (2)Now, show the partition numbers:
SELECT $partition.pf(-2) p_m2,$partition.pf(-1) p_m1, $partition.pf(0) p_0, $partition.pf(1) p_1,$partition.pf(2) p_2
I get partition numbers 1,2,3,4,4
Then try to find the destination data space for partition 4:
SELECT $partition.pf(CAST(prv.value AS INT)) AS p#, prv.boundary_id, dds.destination_id,fg.name AS fg
FROM sys.partition_schemes ps
FULL JOIN sys.partition_range_values prv
ON prv.function_id = ps.function_id
FULL JOIN sys.destination_data_spaces dds
ON dds.destination_id = prv.boundary_id
AND dds.partition_scheme_id = ps.data_space_id
FULL JOIN sys.data_spaces ds
ON dds.data_space_id = ds.data_space_id
FULL JOIN sys.filegroups fg
ON fg.data_space_id = dds.data_space_id
WHERE ps.name = 'ps'
AND dds.destination_id = 4I get no rows, even though these are all FULL joins. So how does the engine determine where to put partition 4? I want to be able to resolve this to the filegroup but have hit a roadblock.
Gerald Britton, Pluralsight courses
- g.britton wrote:
@jeff-moden LOL. I did get an email ack:
@gbritton1 : Thanks for your contribution! The author(s) have been notified to review your proposed change.
(It's Gerald btw)
Oh my. My apologies, Gerald. I don't know why I thought it was George especially since I "know" you from the "other" forum. Gosh, having said that, I hope I'm not mixing you up with someone else.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
@jeff-moden No worries!
Gerald Britton, Pluralsight courses
Viewing 12 posts - 1 through 12 (of 12 total)
You must be logged in to reply to this topic. Login to reply