The Technology Journey to Disaster
- Sergiy - Sunday, May 6, 2018 7:09 AM
I'd have to say he'd make a lousy manager in any of those areas if he truly thought mistakes were ok. And, no... he didn't think it was actually OK to make mistakes. I think it was his way of saying that he was going to push the hell out of people to see what he could get out of them and when they start making mistakes, he knew they reached their limit and he'd back off the pressure.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Sergiy - Sunday, May 6, 2018 6:57 PM
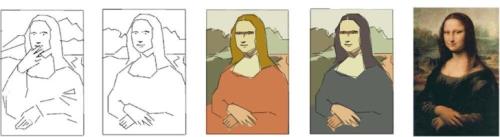
This is the best illustration I have seen on this topic. To my knowledge it was first presented by Jeff Patton. Let me know if it makes sense.
Incremental development starts with the end in mind much the way waterfall development demands:

Incremental and Iterative would start with a sketch and improve it over time. The number of iterations presented within your response is one, the entirety of the painting or sculpture, which is very much waterfall thinking but painters work incrementally and iteratively as shown below. Software developers working incrementally and iteratively as shown below will typically outperform and out-please their customers when compared to developers working only in the incremental way as shown above. Working in an incremental and iterative way we always offer something that is working or usable, get feedback and adapt it as we move forward. Note the change in hand position, background and colors as the versions move from the first sketch to the final painting. Another advantage of working this way, and this has been proven over and over, is if the customer decides the painting available after iteration 3 is good enough for their purposes they can hang it on the wall and start paying us to paint another painting. ~45% of software features are rarely or never used. If we can offer our customers working software all along the way then when they reach the 55%, or whatever their number happens to be, they can stop and have us move to something else more valuable. In the waterfall approach there is nothing usable until 100% of the software is delivered which means paid for goods that cannot be used and not as much room to adapt to changing conditions.
There are no special teachers of virtue, because virtue is taught by the whole community.
--Plato - Orlando Colamatteo - Sunday, May 6, 2018 10:08 PM
Note - the change in hand position means redrawing the whole sketch, starting from the clear space.
Same for every following iteration - it's a new picture painted from the beginning.
And please note - none of the "iterations", except the final version, was exposed to the public by the artist._____________
Code for TallyGenerator -
I worked on a legacy system of a well known travel company for 14 years. The need for attending to redevelopment was apparent, and many improvements were made over time. The office saw the owner's youngest son come in and take over. Somewhat of a coup. During his five year reign, we went through three redevelopment teams of which the legacy team was at times a part of, but most often not. After five years and the three redev teams, the project(s) cost 124,000,000.00 USD with little to show for.Our department was taken over by a man with a MS in Child Psychology and a resume that included being a circus performer. He fell into the position when the dot com bubble burst. The politics, lack of organization, and lack of knowledge about how the business operated let alone the requirements for the ERP system they envisioned was vague at best. The database schema was so overly normalized that it was impossible to make sense of.
The son committed suicide because of his (and other) failures. I was laid off during the fourth attempt. Last I knew they were still utilizing the core part of the legacy system to make the enterprise system run. The whole thing was certainly not a disaster as is this banking scenario but I saw first hand what happens when there is no organization, expertise, direction, or respect for employee/developer knowledge. Software is not magic, and the best laid plans (as well as the not so best) can go awry without all the right elements in place.
-
So the reported issues ranged from: Outages, zero balances, performance issues, customers seeing other customer's account data, cryptic error messages like "..Singleton bean creation not allowed while the singletons of this factory are in destruction.." getting pushed down to users.
How did this slip past QA, and why didn't they have a fail over plan?
"Do not seek to follow in the footsteps of the wise. Instead, seek what they sought." - Matsuo Basho
- Sergiy - Sunday, May 6, 2018 7:09 AM
But mistakes *are* made in those industries, sometimes with fatal consequences.
How many auto recalls for various issues have there been, just in the last 5 years? Off the top of my head I can think of three, two with fatal consequences, one without (Takata airbags, GM ignition problems, VW diesel emissions.)
As for architecture mistakes, having originally been studying to be an architect, most structures are designed with a fairly hefty safety margin built-in, but accidents still happen. Look up the Hyatt Regency walkway collapse. I suspect most architectural mistakes like this occur because the architect isn't thinking about the difficulties in building with real materials their impressive designs.I think some of the mindset when it comes to software development can be boiled down to, it's not life-or-death. Or, at least it hasn't been up until relatively recently. *Most* software, if there's a bug that breaks the program, it's an inconvenience for the end-user, some money out of the developers pocket, and the world goes on. But more recently, software is being developed for applications where that mindset is not only wrong, but potentially fatal (autonomous vehicles anyone?) Industries where the software is and has been life-or-death (medical, airlines, military) have had (and still have) a slow-and-steady, incrementally change with extensive testing mindset.
My suspicion with the TSB incident, is either insufficient testing, or a "do it in production and fix it later" mindset.
-
Sometimes "Fake it, 'till you make it" ends up being "Fake it, 'till you break it".
"Do not seek to follow in the footsteps of the wise. Instead, seek what they sought." - Matsuo Basho
- gwcobb1 - Monday, May 7, 2018 5:38 AM
Thanks for sharing, I have unfortunately seen too many of these:angry:
😎
Trying to prevent these kind of things can be challenging at the best. -
Note - the change in hand position means redrawing the whole sketch, starting from the clear space.
Same for every following iteration - it's a new picture painted from the beginning.
And please note - none of the "iterations", except the final version, was exposed to the public by the artist.I think the takeaway is that through the entire process of creating the painting there is always a recognizable female figure on the canvas. Moving the hand from iteration 1 to 2 would not require redrawing the whole sketch. Only a small area of the overall picture was required to change.Noting that only the result of the final iteration was revealed to the public is an important point and would be analog to us releasing software to the public. Throughout the process, however, feedback could be received and the person looking would have a rather whole idea of where the artist was going with the picture overall.
An interesting sidebar, and I am not sure if Jeff Patton planned his subject matter this carefully but if he did then bravo, but the history of the painting is quite interesting and further supports the message I think he is trying to deliver. Accounts of the life of the painting vary per recordkeeping being what it was in the 16th century but one account is that after one of the early iterations Leonardo stopped working on the painting for the person who commissioned it and started another more lucrative commission therefore he never completed the painting for the original commissioner and went unpaid for it. He did however carry what he had completed to that point in 1506 around with him for another 13 years before completing it around 1516, of his own accord and for no pay.
There are no special teachers of virtue, because virtue is taught by the whole community.
--Plato -
> My suspicion with the TSB incident, is either insufficient testing
I don't think such a thing as "sufficient testing" exists in IT anymore.
When was the last time you saw a commercial product which did not require weekly or at least fortnightly updates with hot fixes?
Proper testing requires more time and resources than development itself.
I've never saw a project where more resources were allocated to testing than to development.
_____________
Code for TallyGenerator -
As Tommy Lee Jones said in No Country For Old Men, it's a mess - if it ain't it'll do until the mess gets here.
It strikes me they are going to be trying to unscramble eggs here.
-
My guess (and I know no more than you) is that they created a fragile system that would break under heavy demand.
I emphasize that I have no inside knowledge. I'm just trying to think of an explanation that fits the facts.
There was a bug with the linked customers. This involves customers that have access to a shared account such as a private customer getting access to a company account. These were linking through to the wrong customers (surely not all the time, or always, because even poor testing would have flushed that out). When management heard that this was happening, they ordered IT to roll-forward as soon as possible because of the risk of random customers being able to transfer funds out of company accounts. (Why didn't they roll-back? -because of targets, I guess). By this time, word was spreading via twitter that things weren't going well. They did a fix that cured problem with the linked accounts, The down-side was that it caused other problems. This increased the noise on twitter to the point that people tried to access their accounts and the loading on the system blew up higher than any predicted peak. This caused all sorts of serious problems. From then on, the whole system was in a 'tank-slapper' or feedback oscillation where every surge in unsuccessful usage by the customers pushed the system to breaking-point. There seem to be a number of breakage points, and they seem to be related to high-volume usage. The bank has stated that the system has been tested as fit for purpose and has been used in the past without incident. What we seem to have is a system that does not 'degrade gracefully'. When I worked in IT in retail banking, testing took up to six months, and quite a proportion of this testing was 'limit' testing to check for precisely this problem. A fragile system works fine in conventional testing but breaks in production because degradation under load is 'catastrophic'. You need scalability and 'limit' testing.Best wishes,
Phil Factor - Phil Factor - Tuesday, May 8, 2018 7:56 AM
Ok this sounds like the modern day equivalent to "run on the banks." Its bad enough the bank may not have enough liquidity to satisfy too many withdrawals (relatively common state of affairs from what I've read), and combine that with the evaporation of trust caused by the bad rollout and some data getting "mixed up" (to put it charitably) things are looking a bit tough for them. These are not the sort of mistakes you want as a learning experience.
-
Damage control, or knowing how to fail gracefully, is important in so many aspects of life. In retrospect, it would probably have worked out better for them (meaning IT) had they decided early on during the crisis to simply reject user logins with a "system unavailable" message until the issues were sorted out, rather than allowing continued user access in a degredated state. It's one thing to take responsibility for the system being offline for a day or even more, but it's quite another to take responsibility for allowing customers to witness the system crashing or having customers see other customer's account data.
"Do not seek to follow in the footsteps of the wise. Instead, seek what they sought." - Matsuo Basho
- Eric M Russell - Tuesday, May 8, 2018 11:22 AM
This is a great point, also debugging and fixing a system in motion is a nightmare. Maybe the scale of the problem wasn't apparent immediately?

Viewing 15 posts - 16 through 30 (of 33 total)
You must be logged in to reply to this topic. Login to reply