The infamous double quote and semicolon error for CSV-files. Not experiencing the issue in 2008R2, but in 2016.
-
Hey guys,
We're currently working on a customers project where we're upgrading from SQL Server 2008 R2 to SQL Server 2016.
The essentials of the project is to move everything from the old 2008R2-environment to the new environment set up on 2016. The reason we're "migrating" instead of directly upgrading is because we have brand new hardware, and the new servers are at a new location.Background info:
We've got the same files we use for both environments. No changes are made to them, and they're loaded as they're delivered. We also have no influence on how they're delivered, and the customer wants very little to no customization to the source files. Therefore, we're stuck with the following CSV-structure (two separate rows in the same column AgreementDescription):"Kraker "Walking floor" trailer 2005-model"; .."Inventory; 2x HP systems, printer, monitor, pen for inventory counting";..
What we don't understand, is how on earth is 2008R2 able to read these (as they should be read) as quote yourtexthere quote semicolon, but 2016 can't read it like this.
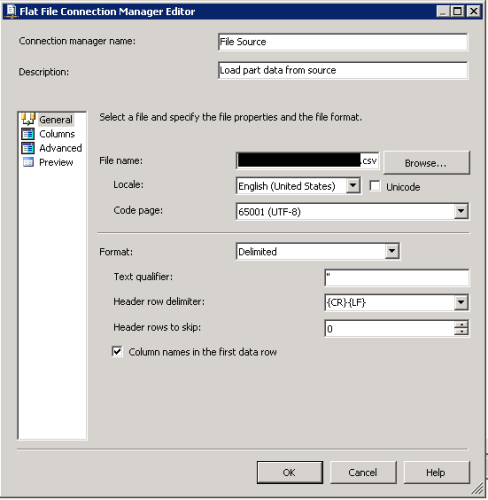
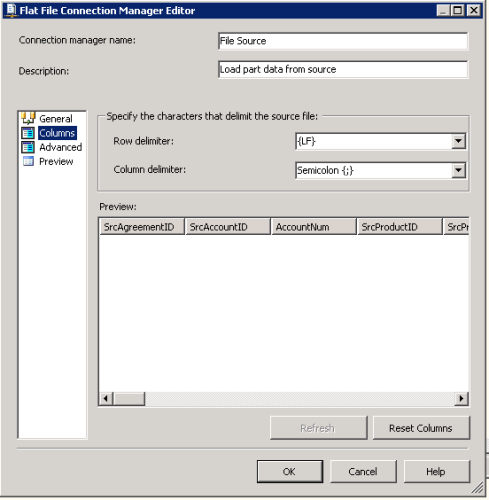
We tried different kinds of combination with and without text qualifiers and column delimiters, but nothing seems to be working.Flat File Connection Manager 2008R2:

Flat File Connection Manager 2016:
The weird thing is, as far as I can understand from others reporting on the same error; this should also be failing in the 2008 R2-environment. This is part of the reason we can't understand the error. The source files loads just fine, unedited, in the 2008 R2-environment, but fails in 2016.
Error message:
The column delimiter for column "AgreementDescription" was not found.Any help or suggestions are more than welcomed!
In advance, thank you!BR
-
try changing the header delimiter to LF - there is a discrepancy between the header and row delimiters.
And what I have found before is that where there is a mistmatch 2008 will happily "eat" the first row after the header line - and this can go unnoticed for a very long time depending on the data being processed.
also, although not common, check to see if any configuration file used is changing the header rows definition
And use a hex editor to look at the file and see if the row and header delimiter are indeed delimited by a LF - CR/LF or just one of them.
- frederico_fonseca - Tuesday, April 11, 2017 5:34 AM
Hi Frederico!
Thanks for the input!
I believe we've already messed around with a few a these values before, but we tried it again, but the LF-delimiter has no effect.
The header and row delimiters are indeed LF, and not CRLF.You mention configuration files. Are these standard ones you think about, or do you mean custom config files? I don't believe we're running any custom ones.
-
It's not totally clear to me how you want the data to be broken down.
Can you post a couple of rows of source data (including only a subset of columns, as necessary to highlight the problem) and show how that data should be parsed? - Phil Parkin - Tuesday, April 11, 2017 6:16 AM
Hi Phil,
I'll answer the best as I can and with the data I have. I scrambled the data, and the problem is with the AgreementDescription-column.
I've marked the part of the original file in bold and green/blue that I believe causes issues. The first two rows are rows that causes no problems.
Row 3: The semicolon after "Inventory" somehow tells SQL Server 2016 that whatever comes after this semicolon belongs to the next column value.
Row 4: The double quotes around "Walkingfloor" somehow also causes problems. It probably tells SQL Server 2016 that Walkingfloor" is part of the next column value.It's really weird. It's like it doesn't want to follow the rules or the fact that for a new column value, you first need a semicolon, then a double quote.
AgreementID;AccountID;AccountNumber;ProductID;ProductProviderOrganizationNumber;ProductType;ProductGroupName;ProductCode;ProductName;ProductDescription;ProductMarketingName;ResponsibleEmployeeID;ResponsibleOrganizationID;ResponsibleDepartmentID;ResponsibleOrganizationNumber;ResponsibleDepartmentNumber;CurrencyCode;AgreementStatusID;AgreementStatusName;AgreementStatusDescription;AgreementNumber;AgreementDescription;ValidFromDate;ValidToDate;CreatedDate;TerminationDate;InstalmentAmount;InstalmentsPerYear;TotalInstalments;Version;SourceReference;HasNoInterestRate;CreditLimit;Extract_DTM;LoyaltyProgram;BreachAmount;BreachDueDate;AgreementAmount;YearlyAgreementAmount;AgreementTypeID;AgreementTypeName;AgreementTypeDescription;InstalmentDueDate;ReevaluationDate;AllowedOverdrawAmount;NominalAmount
"32";"102";"16198875160";"12";"987254999";"";"Loan";"21";"Commercial Market";"";"Commercial Market";"4";"";"";"965725499";"";"USD";"11";"11";"Cashed";"802100";"Converted loan";"";"";"1997-06-30";"";"";"";"0";"";"FINANCE";"0";"4502399";"2017-03-03";"";"";"";"0";"";"";"MN";"MAIN BORROWER";"";"";"";""
"34";"244";"98601215484";"14";"987254999";"";"Loan";"18";"Retail lending";"";"Retail lending";"4";"";"";"965725499";"";"USD";"12";"10";"Redeemed before expiry";"685423";"Converted loan";"";"";"1991-04-15";"";"2150.85";"";"0";"";"FINANCE";"0";"984680";"2017-03-03";"";"";"";"0";"";"";"MN";"MAIN BORROWER";"";"";"";""
"51984";"55244";"973208504";"21";"987254999";"";"Lease";"25";"Equipment leasing";"";"Equipment leasing";"9054";"";"";"2260";"";"USD";"1";"16";"Ongoing";"124578";"Inventory; 2x HP systems, printer, monitor, pen for inventory counting";"";"";"2011-01-09";"";"1418.92";"";"43";"";"FINANCE";"0";"328402.45";"2017-03-03";"";"";"";"884727";"";"";"MN";"MAIN BORROWER";"";"";"";""
"51745";"24215";"602145684";"24";"987254999";"";"Loan";"21";"Commercial Market";"";"Commercial Market";"9055";"";"";"3879";"";"USD";"71";"12";"Redeemed before expiry";"986532";"Kraker "Walkingfloor" trailer 2005-model";"";"";"2011-03-15";"";"9569.3";"";"68";"";"FINANCE";"0";"984350";"2017-03-03";"";"";"";"0";"";"";"MN";"MAIN BORROWER";"";"";"";""These are by the way completely raw files read from .csv into a Staging-area with little, to no rules. The tables are configured with nvarchar(255) for the description fields, which in this case, AgreementDescription, is the column that causes all the trouble.
-
Seems to work OK for me in 2016.
-
A difference between the OP and Phil Parkin's post that I noticed is that the OP used the code page 65001, and Phil used 1252.
I am wondering a few things:
1 - could it be SQL 2008 wasn't using the code page value properly or is more lenient with it and 2016 is more strict?
2 - could it be that some row is missing a quote?Shatter, could you go through and test a subset of the CSV file to figure out which row specifically is causing the headache? I have a feeling that one of the rows has a mismatch of quotes and semicolons.
I would take the CSV file and start by cutting it in half (delete the bottom half of it). Then try the import. If it fails, you know the first half of the data is bad. Cut out half of the data again and retry. Repeat this until you have it down to 1 row. This will be time consuming for sure, but I believe it is the easiest way to know which row 2016 isn't happy with.The other option I can think of would be to use 2008 to dump it into a table and then select all of the rows where the last column is null as 2 quotes ("") should give you a blank, not a null. If there is any rows with the last column as null, you would know that 2008 is less fussy about mismatched quotes than 2016. If there are none with nulls, I would expect it to be something with the code page.
The above is all just my opinion on what you should do.
As with all advice you find on a random internet forum - you shouldn't blindly follow it. Always test on a test server to see if there is negative side effects before making changes to live!
I recommend you NEVER run "random code" you found online on any system you care about UNLESS you understand and can verify the code OR you don't care if the code trashes your system. - bmg002 - Thursday, April 13, 2017 10:34 AM
Hey bmg002,
I've already located the rows that cause problems. As I wrote in the post above, the first two rows are problemless ones, but row 3 and 4 (which originally are scattered rows throughout the dataset) are the ones that cause the problems. It's got something to do with the semicolon in row 3 and the double quotes in row 4 (both in the column AgreementDescription, which is a string (nvarchar)) that somehow confuse 2016, and not 2008.
We've always ran UTF-8 on all our File Connections, but I'll give that a try when I get back to work after easter, Phil.
Thanks for the input!
-
One other thought I have:
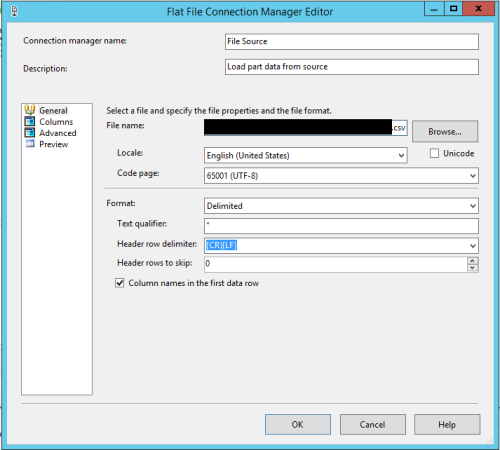
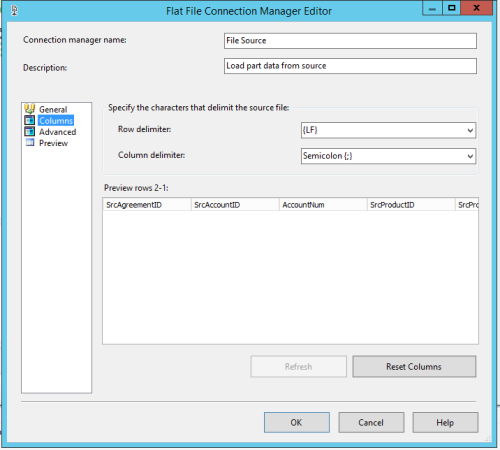
your Flat File Connection Manager screen looks different than Phil Parkin's. Which version of visual studio are you guys using?
I've seen oddities with SSRS and different versions of Visual studio, I wonder if SSIS has a few oddities in older versions of VS with SS2016?
The differences only look like the coloring of some of the dropdowns, but I wonder if you two have different VS versions perhaps?
The other difference I saw was that Phil's is a txt file while yours is csv, but if memory serves, a csv file is just a specific form of txt file.The above is all just my opinion on what you should do.
As with all advice you find on a random internet forum - you shouldn't blindly follow it. Always test on a test server to see if there is negative side effects before making changes to live!
I recommend you NEVER run "random code" you found online on any system you care about UNLESS you understand and can verify the code OR you don't care if the code trashes your system. - bmg002 - Monday, April 17, 2017 8:04 AM
We've confirmed that we're both using '2016', which tacitly implies SSDT 2015, but no harm in double-checking.
- Phil Parkin - Wednesday, April 12, 2017 11:05 AM
Hi Phil,
Did you actually try running the package? It seems you're looking at the "Preview"-window and only viewing the data. We can actually do the same thing and the data looks fine from the "Preview"-window, but once we run it, we get errors.
- Shatter - Wednesday, April 19, 2017 2:45 AM
No I didn't ... until today ... and now I see your problem.
Problem #1, which can be resolved, is a truncation issue. The length of AgreementDescription defaults to 50 & this length needs to be increased.
The leaves only the final row as a problem – specifically, this structure
;"some data "quoted stuff" more data";
known as the 'embedded column delimiter' issue.
As far as I know, the easiest resolution to this one is to get the creator of the file to use a pipe (or whatever) as the column delimiter.
SSIS cannot natively handle this split, though you could potentially write a Script Component source to do the work for you.
If you do some searching, you'll find that you can plagiarise code from others who have already cracked this problem and shared their code. -
Just to follow an alternative method here while you try to dabble with the GUI to solve this problem. How many records/files are you talking about here that have similar issues? Are you talking about billions of records or a couple million or a couple thousand? I mean, not to be that guy, but if you're not really talking about billions of records, why not look into leveraging another piece of technology to clean the data on disk before you try to import it?
For example, you can easily (or I could provide) a simple Python script that would go through every file and clean these records for you. Then you can start ingesting them in SSIS or whatever with whatever format you want. But, if you're talking about a lot of data, maybe it wouldn't be the easiest option.
Looks like you could target the "; characters as your first pass and your target replacement across the entire file and replace the delimiter with something entirely different where you can leave the starting double quotes and semicolons that are actually in the values because semicolon or doublequotes won't be the delimiter or escape characters anymore after the cleaning. You will just have a single delimiter that is correctly placed at the end of every field as long as you are certain that every field is correctly separated across the board with ";
Then on the second pass, remove all the semicolons and starter double quotes from the values (unless you want to keep them for the example of Inventory; ). After that, should have no issues importing it.
- xsevensinzx - Wednesday, April 19, 2017 6:28 AM
I'd be interested in seeing that script ... is it really that simple?
- Phil Parkin - Wednesday, April 19, 2017 6:37 AM
Yeah, it's pretty easy to create a python script that will traverse the directories on Windows and then read each file within a forloop where you basically clean each file one-by-one. In this case, you could likely load each file into Pandas, which will allow you to load the data into a dataframe (like a virtual table) where you can then apply SQL-like methods to cleaning the data. It's not super fast on larger datasets, but you can easily rearrange data or clean it. Then Pandas allows you to easily export the dataframe in CSV, JSON or whatever format you want.
Without Pandas, you could likely get away with using the string methods like MyRow.replace(";") or something to replace all the semicolons from the line as you read the file line-by-line etc.


Viewing 15 posts - 1 through 15 (of 23 total)
You must be logged in to reply to this topic. Login to reply