Table scan shows too many records
-
Looking at the query plan for a rather complicated select, which draws from views, I see the very beginning of the plan shows a scan of one of the root tables, but it shows that it is returning well over six million records, from a table that contains only around 67,000. It even shows those stats under the table, 6228400 of 67680 (9202%). How does this make any sense? It then sorts the 6 million retrieved records, then does some sort of stream aggregate down to 3173540 of 44391 (7149%), then finally does some filtering before joining with some other tables (who also have such ridiculous counts) before finally returning the summary I need - 92 record, with totals.
Naturally, it's abysmally slow, but when I execute any one of the individual views that feed this mess, they return almost instantly. What gives? How can a scan of a table return 100 times the number of records that are actually in the table?
They are file tables, if that makes any difference. I have been trying to create indexed views on them, but running up against non-deterministic function limits, so it seems I'm stuck with table scans. That's not great, but it would be okay, if it returned the proper number.
-
those "mad" numbers show up frequently in certain plans - they should be ignored.
most of the times if you get a ACTUAL explain plan those numbers will be correct - and those are the ones you need to look at.
but even if the numbers are wrong, the joins and type of joins as well as the type of index access being made should be enough for you to look at ways to improve the queries - including, but not limited to, adding new indexes, splitting the query into sub sets with results into temp tables in order to improve its execution.
In order to help on this you would need to supply us with the plans - use https://www.brentozar.com/pastetheplan/ to supply it to us.
-
Still, be sure you do not have some type of accidental join / cross join that will generate extra rows.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
- frederico_fonseca wrote:
those "mad" numbers show up frequently in certain plans - they should be ignored.
most of the times if you get a ACTUAL explain plan those numbers will be correct - and those are the ones you need to look at.
That WAS from the actual plan.
but even if the numbers are wrong, the joins and type of joins as well as the type of index access being made should be enough for you to look at ways to improve the queries - including, but not limited to, adding new indexes, splitting the query into sub sets with results into temp tables in order to improve its execution.
I understand how to do that, but I'm confused why it is reading 100 times more records than actually exist on the initial scan of the tables.
In order to help on this you would need to supply us with the plans - use https://www.brentozar.com/pastetheplan/ to supply it to us.
Okay, here it is: https://www.brentozar.com/pastetheplan/?id=Syc9mCema
-
so.. the plan you supplied does not have the MAD percentages / row counts - but it does show, very clearly in my opinion, the issues you have.
So your understanding of how the engine works is slightly off.
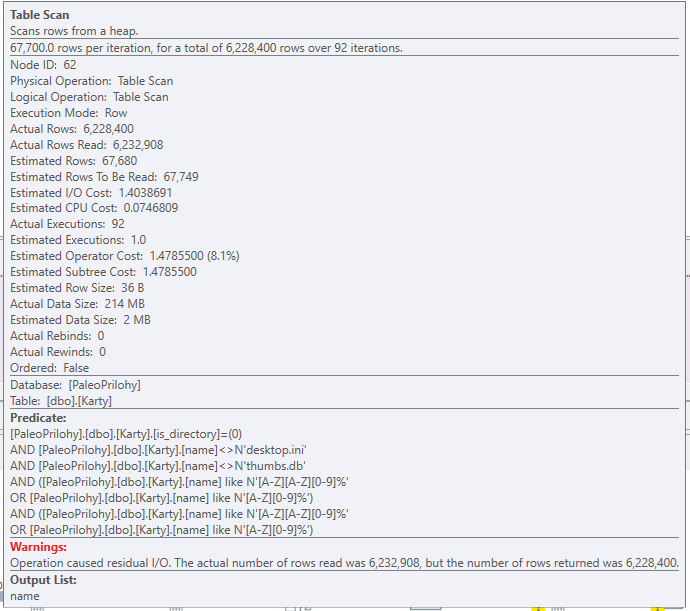
Lets look at one of the tables (Karty).
this tables has 67k rows being processed (lets assume Physical reads here) - this matches what you mention above.
but due to the way the query is built, and the fact that the filtering column is subjected to a whole bunch of manipulation, thus preventing it from being filtered at source, the access to the table is done in a loop (nested loop operator) 92 times - so the row count you see is 92 * 67000 = 6.228.400 rows being "processed" e.g. logical reads
the same issue applies to the access to tables Soukrome and Verejne.
the "bad" part of the query is as follows - same approach to the 3 tables mentioned above - which I believe are from "Select EvidenceLetter, EvidenceNumber, cnt CntPrilohy From [RO].[vwFTDruhaEvidenceCnt]"
PaleoData.dbo.Podrobnosti.EvidenceNumber = Expr1028
Expr1028 = CONVERT(int,[Expr1025],0)
Expr1025 = CONVERT(int,[substring([PaleoPrilohy].[dbo].[Karty].[name],patindex(N'%[0-9]%',[PaleoPrilohy].[dbo].[Karty].[name]),CASE WHEN patindex(N'%[^0-9]%',substring([PaleoPrilohy].[dbo].[Karty].[name],patindex(N'%[0-9]%',[PaleoPrilohy].[dbo].[Karty].[name]),len([PaleoPrilohy].[dbo].[Karty].[name])))>(0) THEN patindex(N'%[^0-9]%',substring([PaleoPrilohy].[dbo].[Karty].[name],patindex(N'%[0-9]%',[PaleoPrilohy].[dbo].[Karty].[name]),len([PaleoPrilohy].[dbo].[Karty].[name])))-(1) ELSE len([PaleoPrilohy].[dbo].[Karty].[name])-(1) END)],0)
assuming that what I mention above is correct, you do have some options - the fastest, even if not the best, may be to place the sub-select outside the main query and insert into a temp table - then use it on main query.
e.g.
drop table if exists #FTDruhaEvidenceCnt
Select EvidenceLetter
, EvidenceNumber
, cnt CntPrilohy
into #FTDruhaEvidenceCnt
From [RO].[vwFTDruhaEvidenceCnt]
create clustered index ci_FTDruhaEvidenceCnt on #FTDruhaEvidenceCnt
(EvidenceLetter
, EvidenceNumber
)
and the main query would then have
LEFT JOIN (Select EvidenceLetter, EvidenceNumber, cnt CntPrilohy From [RO].[vwFTDruhaEvidenceCnt]) PDE On P.EvidenceLetter = PDE.EvidenceLetter Collate Czech_CI_AS AND P.EvidenceNumber = PDE.EvidenceNumber
replaced with
LEFT JOIN #FTDruhaEvidenceCnt PDE On P.EvidenceLetter = PDE.EvidenceLetter Collate Czech_CI_AS AND P.EvidenceNumber = PDE.EvidenceNumber
the collate above MAY be placed on the insert into the temp table IF and only IF dbo.Podrobnosti.EvidenceLetter has a collation of Czech_CI_AS
If so this would be desirable and you would then remove it from the join - frederico_fonseca wrote:
so.. the plan you supplied does not have the MAD percentages / row counts - but it does show, very clearly in my opinion, the issues you have.
Really? It shows the counts for me:
In fact, the picture you sent back to me, the mad numbers are in red just above the flow lines. And they are mad - the 6,228,400 for the Karty table, for example. How did you get it to do that? I had to hover over the table to get a pop-up.
So your understanding of how the engine works is slightly off.
Only slightly? That's better than I thought. 🙂
Lets look at one of the tables (Karty).
this tables has 67k rows being processed (lets assume Physical reads here) - this matches what you mention above.
but due to the way the query is built, and the fact that the filtering column is subjected to a whole bunch of manipulation, thus preventing it from being filtered at source, the access to the table is done in a loop (nested loop operator) 92 times - so the row count you see is 92 * 67000 = 6.228.400 rows being "processed" e.g. logical reads
the same issue applies to the access to tables Soukrome and Verejne.
the "bad" part of the query is as follows - same approach to the 3 tables mentioned above - which I believe are from "Select EvidenceLetter, EvidenceNumber, cnt CntPrilohy From [RO].[vwFTDruhaEvidenceCnt]"
PaleoData.dbo.Podrobnosti.EvidenceNumber = Expr1028
Expr1028 = CONVERT(int,[Expr1025],0)
Expr1025 = CONVERT(int,[substring([PaleoPrilohy].[dbo].[Karty].[name],patindex(N'%[0-9]%',[PaleoPrilohy].[dbo].[Karty].[name]),CASE WHEN patindex(N'%[^0-9]%',substring([PaleoPrilohy].[dbo].[Karty].[name],patindex(N'%[0-9]%',[PaleoPrilohy].[dbo].[Karty].[name]),len([PaleoPrilohy].[dbo].[Karty].[name])))>(0) THEN patindex(N'%[^0-9]%',substring([PaleoPrilohy].[dbo].[Karty].[name],patindex(N'%[0-9]%',[PaleoPrilohy].[dbo].[Karty].[name]),len([PaleoPrilohy].[dbo].[Karty].[name])))-(1) ELSE len([PaleoPrilohy].[dbo].[Karty].[name])-(1) END)],0)assuming that what I mention above is correct, you do have some options - the fastest, even if not the best, may be to place the sub-select outside the main query and insert into a temp table - then use it on main query.
e.g.
drop table if exists #FTDruhaEvidenceCnt
Select EvidenceLetter
, EvidenceNumber
, cnt CntPrilohy
into #FTDruhaEvidenceCnt
From [RO].[vwFTDruhaEvidenceCnt]
create clustered index ci_FTDruhaEvidenceCnt on #FTDruhaEvidenceCnt
(EvidenceLetter
, EvidenceNumber
)
and the main query would then have
LEFT JOIN (Select EvidenceLetter, EvidenceNumber, cnt CntPrilohy From [RO].[vwFTDruhaEvidenceCnt]) PDE On P.EvidenceLetter = PDE.EvidenceLetter Collate Czech_CI_AS AND P.EvidenceNumber = PDE.EvidenceNumber
replaced with
LEFT JOIN #FTDruhaEvidenceCnt PDE On P.EvidenceLetter = PDE.EvidenceLetter Collate Czech_CI_AS AND P.EvidenceNumber = PDE.EvidenceNumber
the collate above MAY be placed on the insert into the temp table IF and only IF dbo.Podrobnosti.EvidenceLetter has a collation of Czech_CI_AS
If so this would be desirable and you would then remove it from the joinOkay, I see what you're talking about. I tried to set up the views to be indexed (persisted), but SS would not allow me to do that for these filetable views. I tried to put the initial filtering conditions in the source views, but it seems to ignore that when evaluating the entire Select. I suppose my best move is to set these up as stored procedures, instead of queries, so I can control them as you explained. Or maybe table-valued functions? Would they get evaluated ONCE, as I want, and the results passed on up the line? I'll have to try that and see what happens.
Almost 20 years of working with this, and I still get my @$$ handed to me by the query engine on a regular basis. Every time I get to thinking that I'm starting to understand how it works, it pops up something new and assures me that I do not.
-
not sure if a TVF would solve this - still worth a try. but try both ways.
regarding the images - I use Plan Explorer from SQLSentry - https://www.sentryone.com/about-us/news/sql-sentry-plan-explorer-free-for-all-users
it is a must have tool.


Viewing 7 posts - 1 through 7 (of 7 total)
You must be logged in to reply to this topic. Login to reply