table design for user "matching"
-
I am finding users that have liked each other. I have a user table and matched table:
create table matched
(match_id int identity not null primary key
,user_id char(1)
,interested_in_user_id char(1)
,interested_by_user_id char(1)
,mutual_yn char(1)
);
insert into matched values('A','C',null,'N'),
('A','D',null,'N'),
('C','B',null,'N'),
('C','A',null,'N');
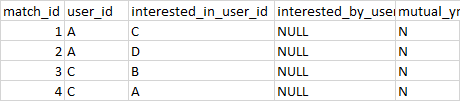
select * from matched;query results:

When a record is inserted (when a user is interested in another user), I check to see if that user is also interested in them. If so, I update the interested_by_user_id and the mutual_yn to Y.
In my example, once the 4th record is inserted, it detects an interest exists for A and C, so for the 4th record it would update interested_by_id with 'A' and mutual to 'Y' and in the first record it would update interested_by_id = 'C' and mutual to 'Y'. Then I query to determine everyone's likes.
But is this a good or best way? Performance-wise it should be OK, even with millions of records. With a thin and indexed table it should be fast.
-
Something like this? (Well, it's a starting point!)
Oh right... nearly forgot MATCHED is a T-SQL keyword, and so is USER_ID
use tempdb;
go
create table matched
(match_id int identity not null primary key
,user_id char(1)
,interested_in_user_id char(1)
,interested_by_user_id char(1)
,mutual_yn char(1)
);
insert into matched values('A','C',null,'N'),
('A','D',null,'N'),
('C','B',null,'N'),
('C','A',null,'N');
/* find all the mutual matches "A likes B, B likes A" */
SELECT m.[user_id] AS Usr,
m.interested_in_user_id
FROM [matched] m
INTERSECT
SELECT m2.interested_in_user_id,
m2.[user_id]
FROM [matched] m2 -
A trigger makes the most sense to me, so that the assignments are immediate. You would also need a DELETE trigger to remove interested / mutual for a deleted user_id (assuming you allow DELETEs). I don't have time to write that now, hopefully someone can provide it. I will check later too.
SET ANSI_NULLS ON;
SET QUOTED_IDENTIFIER ON;
GO
CREATE TRIGGER matched__trg_insert_update
ON dbo.matched
AFTER INSERT, UPDATE
AS
IF UPDATE(interested_in_user_id)
OR UPDATE(interested_by_user_id)
BEGIN
UPDATE m
SET mutual_yn = 'Y',
interested_by_user_id = m2.user_id
FROM dbo.matched m
INNER JOIN inserted i ON i.match_id = m.match_id
INNER JOIN dbo.matched m2 ON m2.user_id = m.interested_in_user_id AND m2.interested_in_user_id = m.user_id
WHERE m.mutual_yn = 'N' AND m2.mutual_yn = 'N'
UPDATE m2
SET mutual_yn = 'Y',
interested_by_user_id = m.user_id
FROM dbo.matched m
INNER JOIN inserted i ON i.match_id = m.match_id
INNER JOIN dbo.matched m2 ON m2.user_id = m.interested_in_user_id AND m2.interested_in_user_id = m.user_id
WHERE m.mutual_yn = 'Y' AND m2.mutual_yn = 'N'
END /*IF*/
/*end of trigger*/
GOSQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
Btw, neither "matched" nor "user_id" are SQL Server reserved keywords.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
Why store information which is derivable by query? It sometimes creates race conditions keeping updated. If you're looking for performance you could try splitting the clustered index away from the primary key and assign it to the (unique) combination of [user_id] and interested_in_user_id. Then an INNER JOIN on the clustered key columns could be used to find matched users
drop table if exists matched_users;
go
create table matched_users(
match_id int identity(1, 1) constraint pk_matched_users_id primary key nonclustered not null
,[user_id] char(1)
,interested_in_user_id char(1)
);
create unique clustered index ndx_unq_u_interested on matched_users([user_id], interested_in_user_id);
insert into matched_users values('A','C'),
('A','D'),
('C','B'),
('C','A');
select *
from matched_users mu
join matched_users mui on mu.[user_id]=mui.interested_in_user_id
and mu.interested_in_user_id=mui.[user_id];Aus dem Paradies, das Cantor uns geschaffen, soll uns niemand vertreiben können
-
It's a shame you're on SQL Server 2012 because the graph database functionality implemented in SQL Server 2017 is perfect for this.
Might be worth installing somewhere and testing/creating a demo for others
Viewing 6 posts - 1 through 6 (of 6 total)
You must be logged in to reply to this topic. Login to reply