Tab Delimited OPENROWSET layout issue
-
Hello folks!
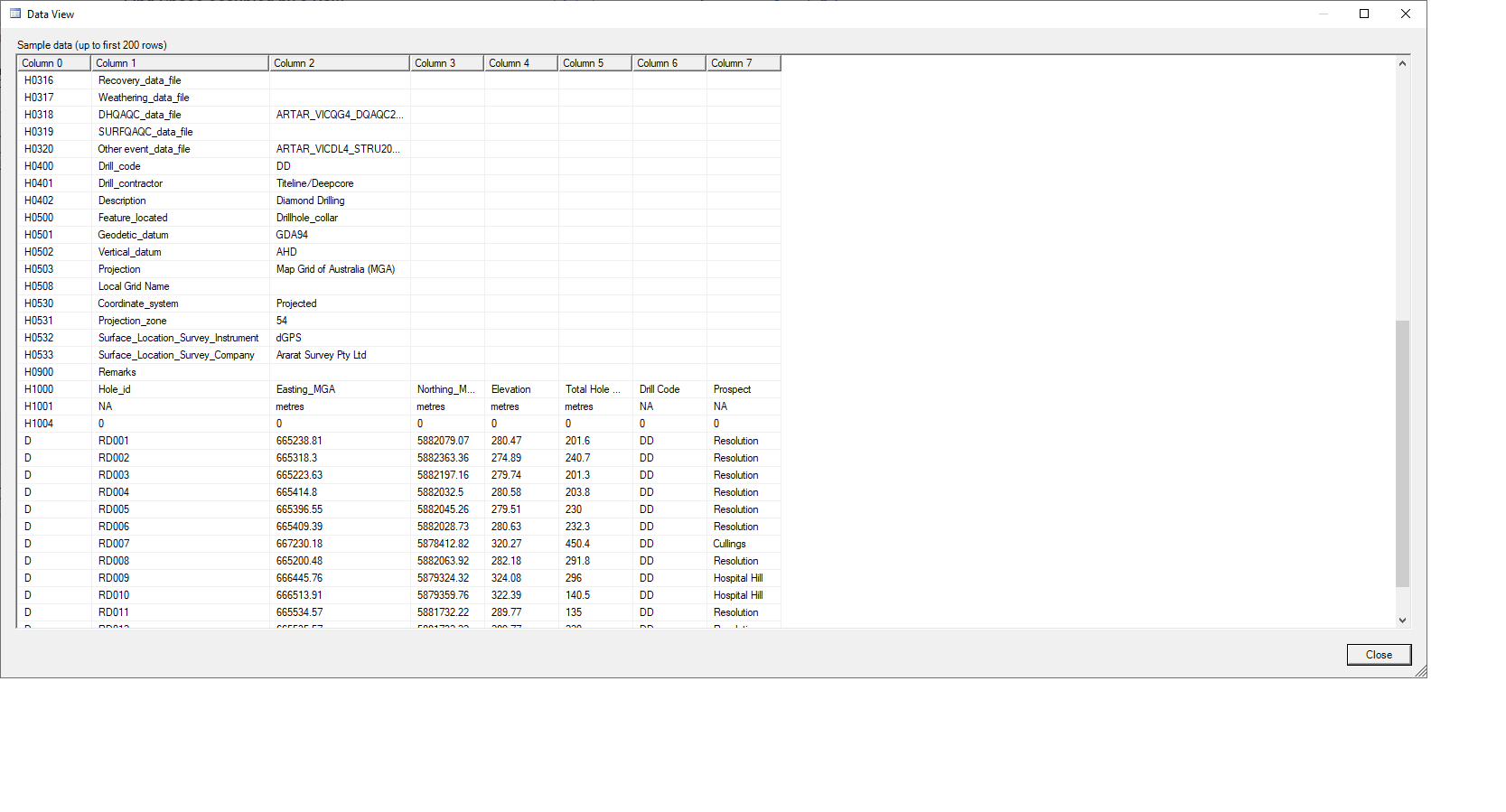
I have a client trying to impor a tab delimited file which I need to perform some ETL prior to inserting into corresponding tables. When I use the import wizard the lay out is correct as shown below:

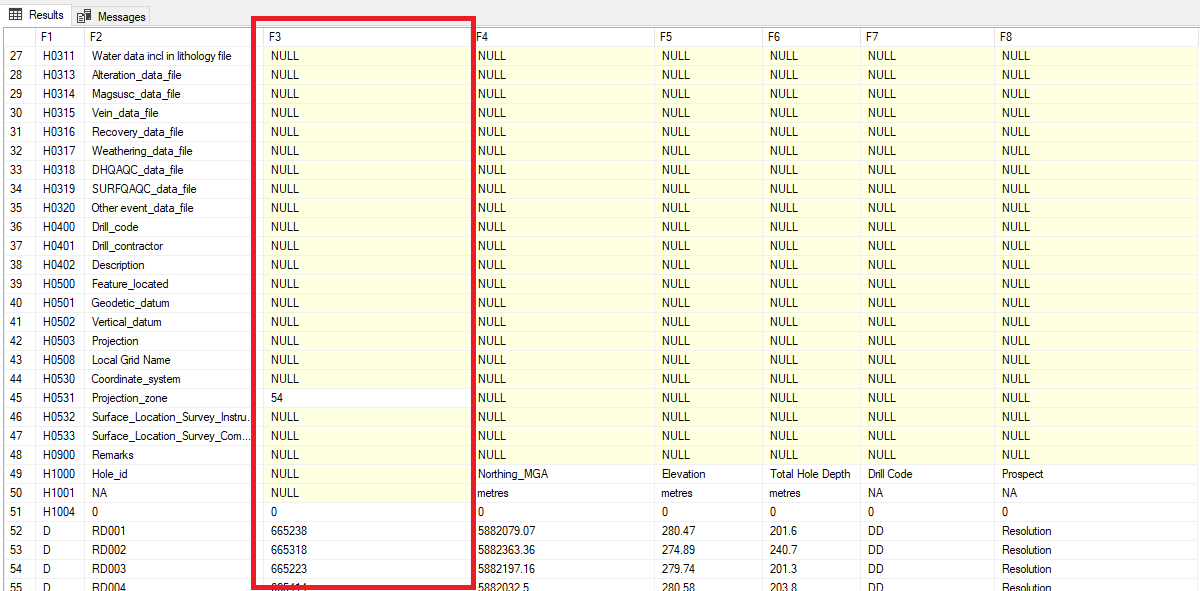
So when I attempted to create this into a script using OPENROWSET along with a Schema.ini file I end up with an anomaly in the 3rd column where data is missing and the decimal values are chopped off.
This is my OPENROW Script:
SELECT *
FROM OPENROWSET('Microsoft.ACE.OLEDB.12.0',
'Text;Database=D:\Vic Survey\MRT',
'SELECT * FROM ARTAR_VICSL4_COLL2018C.txt')
This is the content of my Schema.ini
[ARTAR_VICSL4_COLL2018C.txt]
ColNameHeader=False
Format=TabDelimited
MaxScanRows=0
I cannot seem to see what is the issue. I was speculating the file being an issue, but it the wizard reads it fine as well as a basic importer places the data in the correct place.
Unfortunately I cannot set this as a static process as the number of columns flagged by the h1000 parameter is the columns and they can vary from load to load. So I need to normalise them and flag any missing attributes as a validation error for the user to map as part of the workflow load.
Any ideas, suggestions or a better way to tacle this problem would be very much appreciated.
Thanks!
-
try the following.
adjust number of columns as required - and if they vary hugely you can change that part of the code to be dynamic and based on the max number of "tab" in any row
the splitter function below is from one of our master guru's https://www.sqlservercentral.com/articles/tally-oh-an-improved-sql-8k-%E2%80%9Ccsv-splitter%E2%80%9D-function
if object_id('tempdb..##workfile') is not null
drop table ##workfile
create table ##workfile
(record varchar(8000) -- make it as big as required
)
bulk insert ##workfile from "C:\downloads\ARTAR_VICSL4_COLL2018C.txt" with (firstrow = 1, rowterminator = '\n', tablock)
alter table ##workfile add id int identity (1, 1)
select id
, max(case when spl.itemnumber = 1 then spl.item else null end) as col1
, max(case when spl.itemnumber = 2 then spl.item else null end) as col2
, max(case when spl.itemnumber = 3 then spl.item else null end) as col3
, max(case when spl.itemnumber = 4 then spl.item else null end) as col4
, max(case when spl.itemnumber = 5 then spl.item else null end) as col5
, max(case when spl.itemnumber = 6 then spl.item else null end) as col6
, max(case when spl.itemnumber = 7 then spl.item else null end) as col7
, max(case when spl.itemnumber = 8 then spl.item else null end) as col8
, max(case when spl.itemnumber = 9 then spl.item else null end) as col9
, max(case when spl.itemnumber = 10 then spl.item else null end) as col10
, max(case when spl.itemnumber = 11 then spl.item else null end) as col11
, max(case when spl.itemnumber = 12 then spl.item else null end) as col12
, max(case when spl.itemnumber = 13 then spl.item else null end) as col13
, max(case when spl.itemnumber = 14 then spl.item else null end) as col14
, max(case when spl.itemnumber = 15 then spl.item else null end) as col15
, max(case when spl.itemnumber = 16 then spl.item else null end) as col16
, max(case when spl.itemnumber = 17 then spl.item else null end) as col17
, max(case when spl.itemnumber = 18 then spl.item else null end) as col18
, max(case when spl.itemnumber = 19 then spl.item else null end) as col19
, max(case when spl.itemnumber = 20 then spl.item else null end) as col20
from ##workfile
outer apply dbo.DelimitedSplit8K(record, char(9)) spl
group by id
order by id -
That worked like a charm! You have saved me hours of going down the rabbit hole. I would have never thought of tackling this problem this way but it is a very simple and elegant solution.
Thank you so much Federico!
-
your'e welcome.
Viewing 4 posts - 1 through 4 (of 4 total)
You must be logged in to reply to this topic. Login to reply