Stuff xml path query
-
Hello guys, i have table like yellow area, i want result like green area:
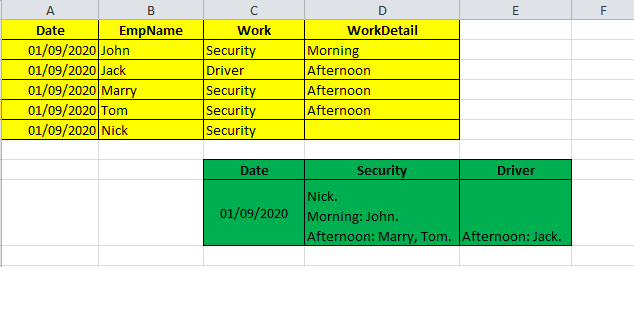
I used:
SELECT *
FROM
(SELECT DISTINCT job2.date, job2.work
, EmployeeList = STUFF((SELECT ', ' + job1.name
FROM dbo.job AS job1
WHERE job1.date = job2.date AND job1.work = job2.work
FOR XML PATH('')),1,1,'')
FROM dbo.job AS job2) AS tblSource
PIVOT (MIN(EmployeeList) FOR work IN ([Security] , [Driver])) AS job3But result not like what i want, please help me.
Here is code create temp data:
USE tempdb;
GO
-- create tables
CREATE TABLE #Emp (
TheDate DATE,
Employee VARCHAR(10),
Work VARCHAR(15),
WorkDetail varchar(20));
GO
-- insert data
INSERT INTO #Emp (TheDate, Employee, Work, WorkDetail)
VALUES ('01/01/2019','John','Security','Morning'),
('01/01/2019','Jack','Driver','Afternoon'),
('01/01/2019','Marry','Security','Afternoon'),
('01/01/2019','Tom','Security','Afternoon'),
('01/01/2019','Nick','Security','');Sorry for my bad english.
-
Your problem is a little complicated since your text columns lists on two levels. Since this is more of a presentation issue, maybe it should be done in the presentation layer, but I'm not sure that report writers have support for this. So let's try this in SQL.
Since you post in the SQL 2008 forum, I guess you are on that version. Nevertheless, in order to make you drool a little and consider an upgrade, here is first a lean solution that requires SQL 2017:
; WITH CTE AS (
SELECT TheDate, Work, WorkDetail, String_agg(Employee, ', ') AS emplist
FROM #Emp
GROUP BY TheDate, Work, WorkDetail
)
SELECT TheDate,
string_agg(CASE Work WHEN 'Security' THEN concat_ws(':', WorkDetail, emplist) END, char(13) + char(10)) security,
string_agg(CASE Work WHEN 'Driver' THEN concat_ws(':', WorkDetail, emplist) END, char(13) + char(10)) Driver
FROM CTE
GROUP BY TheDateAnd here is the solution you will have to live with in the meanwhile:
; WITH CTE AS (
SELECT e.TheDate, e.Work, e.WorkDetail, substring(el.emplist, 1, len(el.emplist) - 1) AS emplist
FROM (SELECT DISTINCT TheDate, Work, WorkDetail FROM #Emp) AS e
CROSS APPLY (SELECT Employee + ','
FROM #Emp e2
WHERE e2.TheDate = e.TheDate
AND e2.Work = e.Work
AND e2.WorkDetail = e.WorkDetail
FOR XML PATH('')) AS el(emplist)
)
SELECT d.TheDate,
MIN(CASE Work WHEN 'Security' THEN x.xml.value('.', 'nvarchar(MAX)') END) AS Security,
MIN(CASE Work WHEN 'Driver' THEN x.xml.value('.', 'nvarchar(MAX)') END) AS Driver
FROM (SELECT DISTINCT TheDate, Work FROM #Emp) AS d
CROSS APPLY (SELECT isnull(CTE.WorkDetail + ':', '') + CTE.emplist + char(13) + char(10)
FROM CTE
WHERE CTE.TheDate = d.TheDate
AND CTE.Work = d.Work
FOR XML PATH(''), TYPE) AS x(xml)
GROUP BY d.TheDate[font="Times New Roman"]Erland Sommarskog, SQL Server MVP, www.sommarskog.se[/font]
-
Possibly not the most efficient approach, but I think this should work:
SELECT
[job3].[TheDate]
, REPLACE( [job3].[Security]
, 'REMOVE:'
, ''
) AS [Security]
, REPLACE( [job3].[Driver]
, 'REMOVE:'
, ''
) AS [Driver]
FROM
(
SELECTDISTINCT
[job2].[TheDate]
, [job2].[Work]
, STUFF((
SELECT
CASE
WHEN [job1].[appendDetail] = 1
THEN CHAR(10)
ELSE ''
END + CASE
WHEN RTRIM([job1].[WorkDetail]) = ''
THEN 'REMOVE:'
ELSE CASE
WHEN [job1].[appendDetail] = 1
THEN [job1].[WorkDetail] + ':'
ELSE ','
END
END + [job1].[Employee]
FROM
(
SELECT
[TheDate]
, [Employee]
, [Work]
, [WorkDetail]
, ROW_NUMBER() OVER (PARTITION BY
[Work]
, [WorkDetail]
ORDER BY [TheDate]
) AS [appendDetail]
FROM[#Emp]
) AS [job1]
WHERE[job1].[TheDate] = [job2].[TheDate]
AND [job1].[Work] = [job2].[Work]
ORDER BY[job1].[WorkDetail]
FOR XML PATH('')
)
, 1
, 1
, ''
) AS [EmployeeList]
FROM[#Emp] AS [job2]
) AS [tblSource]
PIVOT
(
MIN([EmployeeList])
FOR [Work] IN (
[Security]
, [Driver]
)
) AS [job3];Works with the sample data anyways. CHAR(10) is the newline character. One thing not included in my version is the period after the last name in the list. Is that a requirement or is the above "close enough" to what you were looking for?
I used your query as the "base" for my solution and just changed a bit in the innermost part so it would check if it was the first case of the "workdetail" value for that particular "work" value. If it is the first time it came up, we want to include it. If it is the second or further time, then we want to ignore it and put a comma in. We also only put the new line in IF it is the first time that work detail has come up.
If you want to put a period in at the end, I would add another column in on that inner one with the ROW_NUMBER() part that is COUNT(1) with the same partitions. Then if the ROW_NUMBER() = COUNT(1) then add a '.' on the end, else '' and you should be good to go, no?
Depending on the tool you are using to view the data, it may or may not handle the new lines properly or you may need to do CHAR(13) + CHAR(10) to get the newline to work, or it may not work at all (SSMS doesn't show new lines in the grid view for example and in the text view it does some funky things with them).
The above is all just my opinion on what you should do.
As with all advice you find on a random internet forum - you shouldn't blindly follow it. Always test on a test server to see if there is negative side effects before making changes to live!
I recommend you NEVER run "random code" you found online on any system you care about UNLESS you understand and can verify the code OR you don't care if the code trashes your system. -
thanks Erland and Mr.Brian, i run yours code with display estimated execution plan, Erland code with 98%, Mr.Brian with 2%. Why it so different performace.
Anyway, both code is give me result what i want.
-
Because Brian is smarter than me! 🙂
Seriously, we don't see your actual table, nor do we know your indexes, so it is difficult to answer. However, keep in mind that the percentages you see are only estimates. You need to actually run them to compare. I will have to admit that I only focused on solving the problem, and I did not consider performance.
[font="Times New Roman"]Erland Sommarskog, SQL Server MVP, www.sommarskog.se[/font]
-
Heh, I wouldn't say I am "smarter", I would say "I got lucky". I took mrsiro's approach and just expanded on it. A bad (or possibly good?) habit of mine is to take any code the original poster put up and see if I can use that to make what they are asking for. Especially when what they have is CLOSE to the solution they want.
I also expect that Erland's 2017 solution will outperform mine by a long shot. No XML in it!
I, like Erland, did not focus on performance with my approach. I took your original query which was close and tweaked it to get the answer I think you wanted. It is my approach to solving most questions on this forum - look at what was tried and expand on it.
But like Erland said, we don't know your data or indexes or anything with your system, so coming up with an "optimal" solution is not possible for us. We did a best guess with the data provided. Plus I've seen estimated execution plans be horribly wrong before and I would not be surprised if that was the case here too. I'd grab an actual execution plan for both methods and see which performs better AND which is easier to support. My opinion - Erland's is easier to see what is going on and support than mine. My approach is using a lot of nested selects which can be difficult to support. CTE's are MUCH easier to support (my opinion) than nested selects.
The above is all just my opinion on what you should do.
As with all advice you find on a random internet forum - you shouldn't blindly follow it. Always test on a test server to see if there is negative side effects before making changes to live!
I recommend you NEVER run "random code" you found online on any system you care about UNLESS you understand and can verify the code OR you don't care if the code trashes your system. -
hello guys,
With Mr.Brian code, run on temp data is so good. But i run code on real database table which have 100k record, it's bad horribly performace, too slow. Please help.
-
And how do you expect us to be able to help you when you don't share any information at all? Permit me to point out that this is a forum technical assistance, not a training camp for ladies with a crystal ball.
The only advice I can give from the information that I have is that you should upgrade to SQL 2017 or later, so that you can use the query with string_agg that I posted. As string_agg is a more direct approach than the FOR XML kludge, it's potential to perform well is a lot better.
If you want help with the current situation, please post:
- CREATE TABLE + CREATE INDEX statements for your table.
- The actual query that you are using.
- The actual query plan in XML format.
[font="Times New Roman"]Erland Sommarskog, SQL Server MVP, www.sommarskog.se[/font]
-
Hello guys, can i custom number of column in pivot that is not need to be add permission "select" for user.
I have code:
DECLARE @column NVARCHAR(MAX)
SELECT @column = COALESCE(@column + ', ', '') + QUOTENAME(id_work) FROM dbo.listofwork
DECLARE @sql NVARCHAR(MAX)
SET @sql = N'SELECT *
FROM (SELECT DISTINCT job2.date, job2.work
, EmployeeList = STUFF((SELECT '', '' + job1.name
FROM dbo.job AS job1
WHERE job1.date = job2.date AND job1.work = job2.work
FOR XML PATH('''')),1,1,'''')
FROM dbo.job AS job2) AS tblSource
PIVOT (MIN(EmployeeList) FOR work IN (' + @column + ')) AS job3'
EXECUTE(@sql)i put code in store procedure, user run code need to "select" permisson, that user have "execute" permisson in past.So, somebody help me custom column in pivot that is without need to add "select" permisson to user.
-
You create a certificate and sign the procedure with the certificate. Then you create a user from the certificate and grant that user SELECT permission on the table in question. This user is not a normal user, but only a very special one that connects the certificate with the permission.
I describe this technique in a lot more detail in an article on my web site: http://www.sommarskog.se/grantperm.html.
Note that this construct:
SELECT @column = COALESCE(@column + ', ', '') + QUOTENAME(id_work) FROM dbo.listofwork
does not have any defined correct result. You may get what you expect. You may get something else. Use the more cumbersome method with FOR XML.
...or think a second time if you really are doing things in the right place. A dynamic pivot is a presentational device, and is often best done in the presentation layer. Where do you intend to use this result set?
[font="Times New Roman"]Erland Sommarskog, SQL Server MVP, www.sommarskog.se[/font]
-
hello, if you have better way or query please tell me. And I worry about sql injection with EXECUTE(@sql).
-
Best is probably to do the pivoting client-side. In that case there will be no risk for SQL injection!!
As it happens, I also have some text about how to write dynamic pivot on my web site: http://www.sommarskog.se/dynamic_sql.html#pivot. That is part of a longer article on dynamic SQL, and you may have benefit to read it all. I discuss SQL injection in that article.
But if you decide to do it client-side, the whole thing is moot.
[font="Times New Roman"]Erland Sommarskog, SQL Server MVP, www.sommarskog.se[/font]
-
hello, if you dont mind, can you recommend some way to do it client side, i used c#.net.
-
I only write C# left-handedly, so I may not be the best person to ask. Then again, how difficult can it be? You have a data table - transform it to a dictionary does not really sound like rocket science to me.
Anyway, I did some quick googling on "pivot data c#" and I found https://www.codeproject.com/Articles/22008/C-Pivot-Table. I did not look into it at all, but I leave that to you. I would expect there are more components out there for the task.
[font="Times New Roman"]Erland Sommarskog, SQL Server MVP, www.sommarskog.se[/font]
-
thank erland, many loop in code, it's not good for performance, and i need write some code use dictonary and split to get finally result.
I think i dont need to query replace workdetail because i do that client side with dictonary and split. So query give me table like:
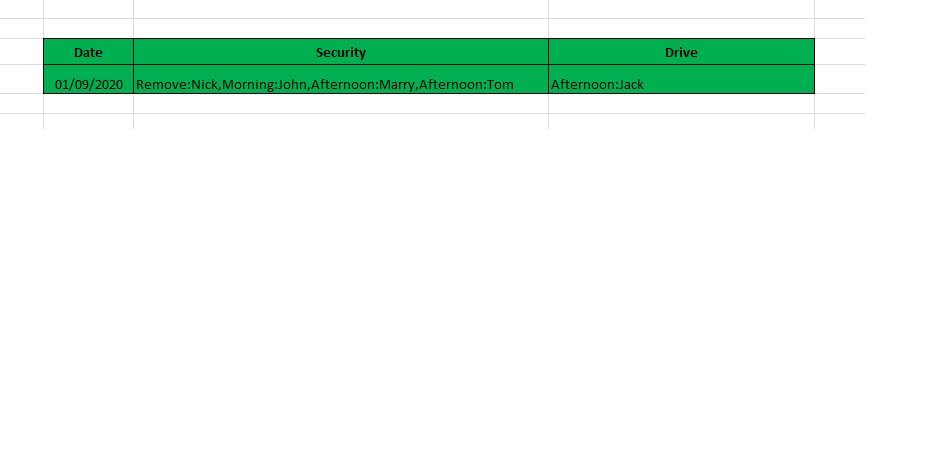
After get this table, i use split and dictonary in c# to replace workdetail. It seem good performance than use Mr.Brian query which give me final result but not good for performance.
So, problem is how to write better query to get table like image above.
Or another way, simple query get table like yellow, at client side, concat row and replace workdetail with dictonary and split (it's seem to be more loop - problem with performacee again).
So, How do you think?
Viewing 15 posts - 1 through 15 (of 27 total)
You must be logged in to reply to this topic. Login to reply