SQL Query execution plan sort operation
-
Hi All,
Could you please let me know what could be the cause of having 58% sort operation in Insert statement.
One Cluster index is there in the table, it is datawarehouse database , this table would be truncated before loading so no records were there before insertion of records.
There is a cross join and left outer join for the select statement which is used to insert. Some times this operation takes 1hr to finish 12 million record, some times it takes 1.5hrs for same 12 million records , but the the execution plan remains the same, there were no blockings also found.
Any suggestions to overcome the issue.

Thanks!
-
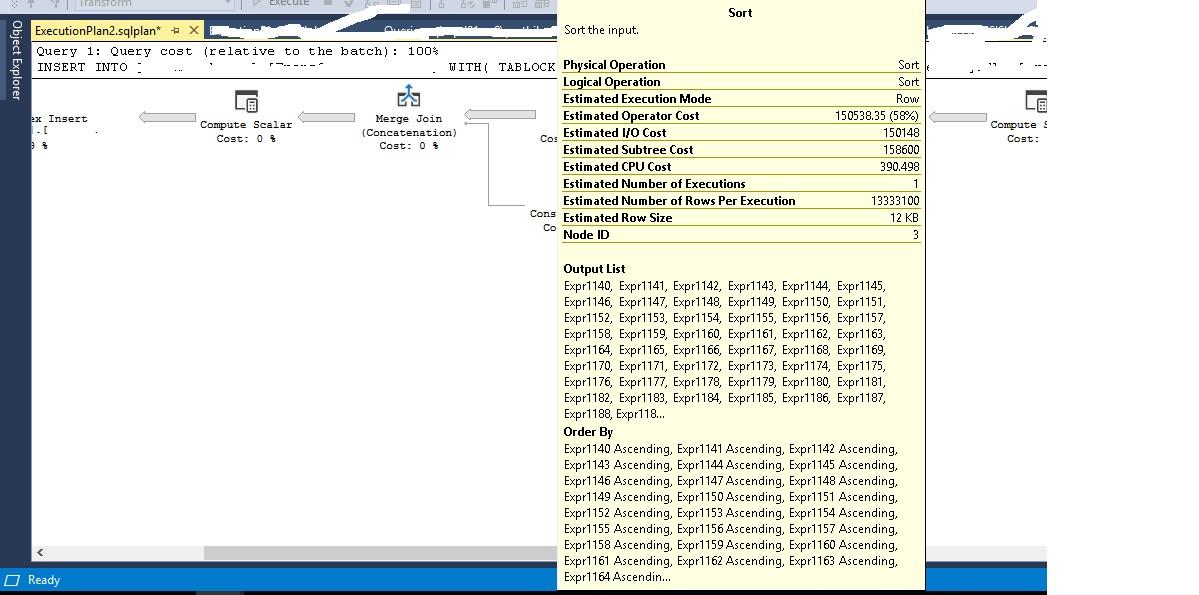
The cause of having 58% sort operation is a 2 part question. The sort is probably due to something on your clustered index so the data needs to be ordered before inserted or your query has an ORDER BY in it. The 58% is just SQL's "cost" calculation which SOMETIMES is a good indicator of a problem and SOMETIMES leads you down the wrong path. Plus, if your statistics are out of date, an estimated plan can be VERY inaccurate. Actual plans are a much better for reviewing performance issues.
To reduce this, I would recommend dropping any ORDER BY clause you have (if any) and if that doesn't help, try removing your clustered index prior to the insert and rebuilding the index after the insert. At my workplace we shaved off about 20% of our ETL time by dropping all clustered indexes and disabling all nonclustered indexes prior to doing our ETL and rebuilding them after the ETL.
Another option would be to check the performance of just GETTING the data; ignoring the INSERT part. How long does that SELECT with the 2 joins take to get the 12 million records? It MAY be that your INSERT is only part of the problem. If it takes 45 minutes to get the data and 15-45 to insert, you may be tackling the wrong beast.
Lastly, how large is that data? 12 million records (12,000,000) at 8 KB/row (max row size, probably not your case, but not ruling it out) is coming in at 96,000,000 KB or (roughly) 96 GB! The slowness could be trying to push across a LOT of data across the network. Now, I expect that your rows are MUCH smaller than 8 KB, but even 0.5 KB per row is 6 GB of data you are pushing across.
The above is all just my opinion on what you should do.
As with all advice you find on a random internet forum - you shouldn't blindly follow it. Always test on a test server to see if there is negative side effects before making changes to live!
I recommend you NEVER run "random code" you found online on any system you care about UNLESS you understand and can verify the code OR you don't care if the code trashes your system. -
A MERGE join requires input data sets that are sorted in the same order. SQL decided it was better to sort one (or more) of the input sets so that a MERGE join could be done. SQL is usually right about such things, but not always. When it's appropriate, a MERGE join is often the fastest join possible.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
Every value that is being sorted (and there are a LOT of them) are shown as 'Expr1140', 'Expr1141', etc. Those aren't the names of the columns in your tables (I hope). Those are the results of calculating values in a previous step. If you're working with calculated values (the results of performing functions on a column or columns), then there are no indexes, unless you have pre-calculated those values and persisted them on the table in a column.
If you want real answers and not the wild guesses everyone's giving you, you'll need to post a scripts for the tables involved, the query you're running, and a script to put some sample data in those tables.
Eddie Wuerch
MCM: SQL -
Yes You are correct the values are from functions , but those are just hardcoded / default values due to business constraint i am unable to post entire code here as it has 2K lines in it, sample column looks like as below
Select (Select COALESCE(m.[Colour],m.[Colour],template.[Colour])
From #Temptable) CORSS JOIN m_table LEFT JOIN function_name template
#Temptable is populated from 20 different tables from fact and dimension tables which has index in temptable.
Viewing 5 posts - 1 through 5 (of 5 total)
You must be logged in to reply to this topic. Login to reply