SQL Memory & Tempdb usage
-
Hi
Can someone confirm this please - my thoughts are that SQL has 3 main components in RAM - Proc cache ( about 2 GB ), Buffer Cache Pool ( the main memory - shared with Tempdb ) , and Log Cache ( about 60 kb per database ).
With tempdb usage - is it correct to say that Tempdb operations are performed fully in memory as long as there is sufficient RAM available, and then activity is only paged to the actual disk-based Tempdb database when the RAM requirement for tempdb operations exceeds available RAM?
Thoughts welcome 🙂
Cheers
Steve
- sqlguy7777 - Tuesday, January 1, 2019 6:04 PM
tempdb is just another database. The only difference is that it is recreated from scratch every time SQL Server is restarted. Its memory usage, to my knowledge, is no different from any other user database.
- Jonathan AC Roberts - Tuesday, January 1, 2019 6:16 PM
Things that use TempDB will try to use memory first. If things get too large, then it spills to disk. That also includes Temp Tables and Table Variables. Neither is all memory and neither is all disk.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Hi, thanks everyone for your replies.
Ok, so if my understanding correct then, all required database objects are loaded into RAM when RAM permits, including tempdb, but if there is insufficient RAM, we would see any database in RAM spilling out to the database on disk. I would expect this to show up as Buffer Cache Hit ratio dropping below 100% - would that be a fair comment?
Also, is Tempdb treated any differently to any other database - is it given higher priority etc?
Can we prioritize any database over others, to make sure it stays in RAM and less likely to be paged out?Cheers
SG
- I'll have to defer to someone like Gail Shaw or another MCM for the correct answers there, especially when it comes to the priority of operations that require TempDB.
I do know that if something in memory isn't currently being used, the "older" currently unused stuff in memory can be simply dropped from memory to make room for something that needs to be loaded from disk and put into memory to be used.
I don't believe you can give a database priority over other databases in the same instance. You CAN throttle how many resources can be used by "workload group" using a thing called "Resource Governor" but I've never used it. I'm of the ilk that if something is using too many resources, it needs to be fixed and I look for such things every day. IMHO, intentionally making anything run slower seems seriously contrary to what people need to do in databases.
https://docs.microsoft.com/en-us/sql/relational-databases/resource-governor/resource-governor?view=sql-server-2017--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - sqlguy7777 - Thursday, January 3, 2019 11:59 PM
100% is almost a theoretical number. I have rarely seen that be 100% on any system that is actually working.
Page Life Expectancy is also a measurement that needs to be examined.
This is a good article. https://www.sqlskills.com/blogs/paul/page-life-expectancy-isnt-what-you-think/What problems are you trying to solve?
Michael L John
If you assassinate a DBA, would you pull a trigger?
To properly post on a forum:
http://www.sqlservercentral.com/articles/61537/ -
Worth reading this as you are using SQL Server 2016: https://docs.microsoft.com/en-us/sql/relational-databases/databases/tempdb-database?view=sql-server-2017
Performance improvements in tempdb for SQL Server
Starting with SQL Server 2016 (13.x), tempdb performance is further optimized in the following ways:
- Temporary tables and table variables are cached. Caching allows operations that drop and create the temporary objects to execute very quickly and reduces page allocation contention.
- Allocation page latching protocol is improved to reduce the number of UP (update) latches that are used.
- Logging overhead for tempdb is reduced to reduce disk I/O bandwidth consumption on the tempdb log file.
- Setup adds multiple tempdb data files during a new instance installation. This task can be accomplished with the new UI input control on the Database Engine Configurationsection and a command-line parameter /SQLTEMPDBFILECOUNT. By default, setup adds as many tempdb data files as the logical processor count or eight, whichever is lower.
- When there are multiple tempdb data files, all files autogrow at same time and by the same amount depending on growth settings. Trace flag 1117 is no longer required.
- All allocations in tempdb use uniform extents. Trace flag 1118 is no longer required.
- For the primary filegroup, the AUTOGROW_ALL_FILES property is turned on and the property cannot be modified.
For more information on performance improvements in tempdb, see the following blog article:
- Jonathan AC Roberts - Friday, January 4, 2019 8:55 AM
Yeah... that enforced balanced autogrow stuff (along with an undocumented fault when using SET IDENTITY INSERT ON) killed me during a recent particular bit of code that needed the exception. I wish MS would stop removing abilities and making it difficult to temporarily override a "feature". Yes, it's usually a good idea to grow TempDB files all at the same time... emphasis on "usually". That doesn't mean "always".
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Michael L John - Friday, January 4, 2019 8:39 AM
That's the question of the year, so far.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Hey thanks everyone for your great responses so far.....
"What problems are you trying to solve?"
In a nutshell, we were having a debate in the office as to SQL Servers behavior under significant Tempdb load.
The question that came up was - how do you stop a certain nasty cursor-based app we have from "spilling" from RAM tempdb operation onto disk Tempdb operation.
My thoughts were as it uses row versioning ( and the app code is appallingly bad COTS rubbish ) we cant do a lot, however we might be able to strike a balance.
We have tempdb set as per best practice yada yada.
One thought was that once the available RAM for Tempdb in was exhausted ( due to other databases in RAM running fairly constant memory usage ), do we then in effect have a limited size RAM-to-Disk "pipe" - through which activity in tempdb on disk is "pumped" to and from RAM?
What is the best way to try and get as much activity for Tempdb to happen in RAM?
In some ways I guess I'm looking at how best to push SQLs internal architecture to the limit to compensate for crap vendor code.....Thoughts welcome.... 🙂
- sqlguy7777 - Friday, January 4, 2019 10:57 PM
As a matter of fact, I have some thoughts on that... they're not really "thoughts"... they're steps that I've taken in the past.
Step 1 is to stop debating and capture the execution plans and performance metrics of the cursor based performance challenged code.
Step 2 is that if it's 3rd party software, provide all that data to them and tell them to fix it. I DO hope that whatever you bought came with support. If they don't take care of you rightly and quickly, tell them that you're going to report them to the Better Business Bureau and when they give you the "so what shrug", DO IT!.
Step 3, plan on replacing that software if they don't move on it. Make sure that the software is "guaranteed for performance".
Step 4, if it was written in house, develop a plan to keep this type of thing from happening again while you're fixing the code.--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Hi
I agree with you completely, but we’re kind of stuck with it. The top brass have pumped big money into this thing and so won’t trash it, despite us asking them to.....
We have been analysing execution plans and have offered tuning suggestions but people are not prepared to change anything really at a code level. Pretty average situation.......the best we can come up with is trying to put all tempdb in RAM. Welcome to public sector IT.
- sqlguy7777 - Saturday, January 5, 2019 2:36 AM
Oh my... I completely understand that. I'm going through a similar problem myself. Fortunately, management has realized we can actually replace a part of the application that was "bolted on" after the fact and, because the vendor is either unwilling or unable even with all the feedback we've provided, we're actually doing so. Preliminary testing shows that the replacement for the "document classification" part (the worst part) of the application runs so fast that we can't even measure how long it takes because it's coming in at sub-microsecond times. It used to take about 22 seconds per run per document. The next bit of code we need to write is the batch process that uses that code and that's where we'll be able to actually measure the duration.
Getting back to your problem, I'm not sure what algorithm SQL Server uses to decide what and when something needs to spill to disk so having a ton of RAM may or may not be the answer. If you can't solve the problem of preventing disk spills to TempDB, there are some hardware things you might be able to do (and you probably already know this but just confirming). If you're stuck with spinning disks for TempDB, make sure they're setup for RAID 10. If you have SSDs (which are slower than RAM just because they're non-volatile storage), consider putting TempDB on the SSDs with the understanding that SSDs do have a lifetime expectancy that is shorted by lots of writes.
Possibly even better would be to have a ton of RAM and try putting TempDB on a RAM DISK with the warning that suggestion has proved to be a futile effort for the types of things that I've tried it for but sounds like it may help in this situation. I also don't know all of the ramifications of having TempDB living in volatile storage nor how much overhead (if any) the operating system induces when doing such a thing.
There may also be some indexing opportunities not only in the form of new/different indexes but in the structure of the indexes and how they are maintained (I've been studying and testing both of those aspects deeply for more than the last year).
For example, there may be a serious advantage to forcing all LOBs and large non-LOB variable width non-indexed columns out of row. In one demonstrable but small (100,000 row) test, such an action dropped the total pages read from 49284 pages (385MB in logical reads) to 549 pages (4MB). If you have LOBs or large variable width columns in your Clustered Indexes or Heaps, moving them out of row can seriously reduce the amount of memory used for queries and that could greatly reduce the chances of TempDB spills depending on what the code is actually doing in your case.
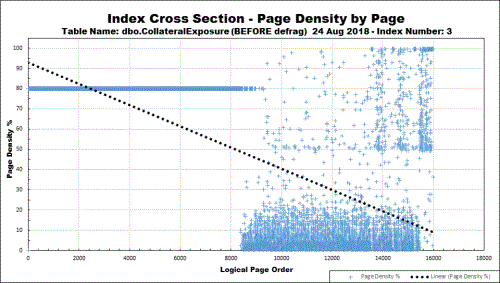
There's also the subject of index maintenance... I know that sounds strange but both moving LOBs out of row and doing the right kind of index maintenance can make a huge difference. I also find that (myself included until I "saw the light"), most people are actually doing index maintenance incorrectly and wasting a ton of memory in the process. For example, here's what the cross section of a just one index that I have at work looks like...

The Blue crosses represent pages (1 out of 100 sample rate on this 12.5GB non-clustered index) and their vertical position indicates how full they actually are. There are several things to note...
1. Since the index fragments very quickly, people changed the FILL FACTOR to 80%. You can see that does nothing to prevent fragmentation for this particular index. The index has an "ever increasing key", which prevents fragmentation during the original INSERTs but does nothing to prevent the massive bad page splits during the "ExpAnsive" updates that occur on variable width columns after the insert. Those variable width columns simply need a default that will prevent the expansion from NULL to some value to prevent the page splits.
2. Looking at the left side of the chart where all the pages line up as 80% full due to a REBUILD of the index in the past, you can see the 80% fill factor is just wasting 20% because it will never be filled (older rows become static).
3. Looking at the right side of the chart, most of the pages are only about 20% full. Unfortunately, this is also the most-read area of the index because the data is new and most people work with the newer data. That translates to about an 80% waste of memory because the pages in memory are structured the same as they are on disk.Without making any changes to the underlying table, the only way to keep such insane memory waste in check is to rebuild (NOT REORGANIZE) this index at 98% (instead of 100% so that we know it's a problem-child) and do it on a nightly basis. Of course, the page splits will continue to beat the tar out of the system both in system transactions (can be a significant source of BLOCKING), CPU, and massive writes to the Log File because each bad page split like the ones happening on this index write more than 40 times the number of log file entries that a good page split would.
Of course, fixing the "ExpAnsive" variable width column updates would eliminate all bad page splits and this index could go literally for years at a 100% FILL FACTOR with zero bad page splits and zero fragmentation issues. For that to happen, though, either the underlying datatype in the variable width columns needs to be changed to fixed width OR a reasonably sized meaningless default of multiple spaces needs to be assigned in the table definition (or the code that does the INSERTs), which could break code that's looking for non-NULL rows OR (for larger variable width columns) need to be forced out of row OR some combination of those actions.
Any and all of that could help with the problem of spills to TempDB because they all reduce the amount of reads per given query and you have to remember that a logical read is 8KB of RAM. Even on the little 100,000 row example I cited, changing 385MB of logical reads to just 4MB is one hell of a memory savings that can have a significant impact on the reduction of spills to TempDB.
Of course, if you can't change anything having to do with tables or indexes, all of this is a moot point but thought it was worth mentioning just in case you can make such adjustments. Heh... it answers the implied questions of "Thoughts welcome" on this nasty problem you have.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Hi Jeff,
Thanks for your thoughts. Yep its been fun watching the Execs going off like a frog in a sock once they realized they had a dog on their hands, and we've been in the pressure cooker....
One aspect was too they are looking at doing archiving, which should also take pressure off...we will see.
I'll digest your thoughts some more before I comment. I like your analysis of the indexing.....Cheers
SG
Viewing 14 posts - 1 through 14 (of 14 total)
You must be logged in to reply to this topic. Login to reply