SQL fuzzy logic in join
-
Hi,
I am trying to create a query for gap analysis when country value do not match based on following condition :
- Perfect match when both #FuzzyMatch1 and #FuzzyMatch2 have one value
- Fuzzy match ( atleast one value to be matched, more is fine also) between both tables
- Desired results based on sql code attached given below
--For single value country in both #FuzzyMatch1 and #FuzzyMatch2, the country should be a perfect match. If both country doesn't match 100% then
--I need to include in select statement to report as a gap
-- ID 1 , this record should not be flagged as a discrepancy as USA exists in #FuzzyMatch2 even though it's not a perfect match
-- ID 2 , this record should not be flagged as a discrepancy as Africa exists in #FuzzyMatch2 even though it's not a perfect match
-- ID 3 , this record should be flagged as a discrepancy as neither USA or India exists in #FuzzyMatch2
-- ID 4 , this record should be flagged as a discrepancy as Mexico doesnot exist in #FuzzyMatch2
-- ID 5 , this record should not be flagged as it's a perfect match
CREATE TABLE #FuzzyMatch1
(
ID INT,
Country NVARCHAR(100)
)
CREATE TABLE #FuzzyMatch2
(
ID INT,
Country NVARCHAR(100)
)
INSERT INTO #FuzzyMatch1 ( ID,Country)
SELECT 1,'USA;Canada;Australia' UNION ALL
SELECT 2,'USA;Canada;Africa' UNION ALL
SELECT 3,'USA;India' UNION ALL
SELECT 4,'Mexico' UNION ALL
SELECT 5,'New Zealand'
INSERT INTO #FuzzyMatch2 ( ID,Country)
SELECT 1,'USA;Nepal' UNION ALL
SELECT 2,'China;Africa' UNION ALL
SELECT 3,'Pakistan;Brazil' UNION ALL
SELECT 4,'Algeria' UNION ALL
SELECT 5,'New Zealand'
SELECT * FROM #FuzzyMatch1
SELECT * FROM #FuzzyMatch2
--desired result
SELECT 3 as ID,'USA;India'AS Country,'Pakistan;Brazil' As Country
SELECT 4 as ID,'Mexico'AS Country,'Algeria' As Country
DROP TABLE #FuzzyMatch1
DROP TABLE #FuzzyMatch2 -
So, you want to split the values in the first table, and return results WHERE Country NOT LIKE('%'+split.Value+'%') , right?
Edit: I would say, first suggestion is to normalize the data and not store multiple values in one column. If that's not an option, let us know and we'll help you work through the above.
-------------------------------------------------------------------------------------------------------------------------------------
Please follow Best Practices For Posting On Forums to receive quicker and higher quality responses -
These are two separate tables coming into SQL from SharePoint list . I need to provide a gap report where the countries do not match.
- Perfect match
- Fuzzy match as explained before
Thanks,
PSB
-
splitting the values into separate rows is not an option .
-
You're doing the wrong thing badly. You don't seem to know the table must have a primary key by definition; this is not an option! A row is not a record.; They are totally different concepts. There is no such thing as a generic "id" in RDBMS; it must be the identifier of something in particular, according to what is called the Law of Identity in logic. You also seem to have failed to do any basic research because you would know that there is an ISO standard code of three letters for country names. No, you need to do that for yourself.
You've also never read a book on RDBMS or SQL because you would know CSV or a violation of First Normal Form, (1NF) the very foundations of RDBMS. Finally, why are you using the old non-ANSI syntax for your insertion statements? Are you still using the original Sybase engine?
CREATE TABLE County_List_1
(country_code CHAR(3) NOT NULL PRIMARY KEY);
CREATE TABLE County_List_2
(country_code CHAR(3) NOT NULL PRIMARY KEY);
INSERT INTO County_List_1
VALUES (...);
INSERT INTO County_List_2
VALUES (...);
You can now use the set-based operators, INTERSECT and EXCEPT, to find the differences. Between the two tables.
Please post DDL and follow ANSI/ISO standards when asking for help.
-
EXCEPT gives one to one match in all cases. I want conditional matches depending on case by case basis.
-
Here's one way to do this... it's horrible because, without a Clustered Index on the ID column, it takes 4 scans of the table and doesn't do much better with the Clustered Index. Of course, that's the nature of these types of problems. Everything that touches the denormalized column is going to be a train wreck especially when you're looking for things that don't have a match.
WITH cteMatch AS
(--==== Find an an all matches. Return the IDs that have at least one match.
-- This acts like the mapping/bridge table that someone should create
-- and keep up to date but without the extra two columns for such a table.
SELECT fm1.ID
FROM #FuzzyMatch1 fm1
JOIN #FuzzyMatch2 fm2 ON fm1.ID = fm2.ID
CROSS APPLY STRING_SPLIT(fm1.Country,';') split1
CROSS APPLY STRING_SPLIT(fm2.Country,';') split2
WHERE split1.value = split2.value
GROUP BY fm1.ID
)--==== Return the rows from both tables that don''t have at least one match.
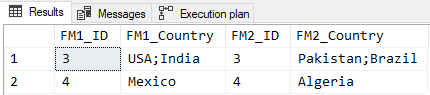
SELECT FM1_ID = fm1.ID
,FM1_Country = fm1.Country
,FM2_ID = fm2.ID
,FM2_Country = fm2.Country
FROM #FuzzyMatch1 fm1
JOIN #FuzzyMatch2 fm2 ON fm1.ID = fm2.ID
WHERE NOT EXISTS (SELECT * FROM cteMatch m WHERE m.ID = fm1.ID)
;The output is as expected...

--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - jcelko212 32090 wrote:
You're doing the wrong thing badly. You don't seem to know the table must have a primary key by definition; this is not an option! A row is not a record.; They are totally different concepts. There is no such thing as a generic "id" in RDBMS; it must be the identifier of something in particular, according to what is called the Law of Identity in logic. You also seem to have failed to do any basic research because you would know that there is an ISO standard code of three letters for country names. No, you need to do that for yourself.
You've also never read a book on RDBMS or SQL because you would know CSV or a violation of First Normal Form, (1NF) the very foundations of RDBMS. Finally, why are you using the old non-ANSI syntax for your insertion statements? Are you still using the original Sybase engine?
CREATE TABLE County_List_1
(country_code CHAR(3) NOT NULL PRIMARY KEY);
CREATE TABLE County_List_2
(country_code CHAR(3) NOT NULL PRIMARY KEY);
INSERT INTO County_List_1
VALUES (...);
INSERT INTO County_List_2
VALUES (...);
You can now use the set-based operators, INTERSECT and EXCEPT, to find the differences. Between the two tables.
Because you refuse to understand and acknowledge the actual "RECORDS" that are contained in the ROWS of the given problem, your code won't provide the answer to the problem. It only does what YOU want it to.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Worked . Thanks
- PSB wrote:
Worked . Thanks
Thank you for the feedback. Since you're the one that will need to support it, at least in the short term, do you understand how and why it works?
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally)
Viewing 10 posts - 1 through 10 (of 10 total)
You must be logged in to reply to this topic. Login to reply