Sort already comma separated list
- ScottPletcher - Friday, February 8, 2019 3:47 PM
I didn't say that it would be relevant to anyone. I didn't say that weren't useful and proper as a PK. I said that they don't actually follow the rules despite the fact that I'd use them without hesitation.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - paul s-306273 - Tuesday, February 5, 2019 1:21 AM
I admit to searching out Joe's posts. I'm sure I do stuff he wouldn't approve of, heck I do stuff I don't approve of, all in the interest of getting paid.
Still, its important for me anyways to at least consider what he says, theres been occasions that I've been able to learn important, foundational lessons from him that goes to the very heart of what I want to do in this business. This sort of information is pretty important to me. Maybe I'm being selfish but whatever.
- paul s-306273 - Tuesday, February 5, 2019 1:21 AM
I do agree with Patrick that he does come up with a gem every once in a while and he does have some incredible history lessons but I don't follow Joe nor do I search his posts out.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - ScottPletcher - Friday, February 8, 2019 3:47 PM
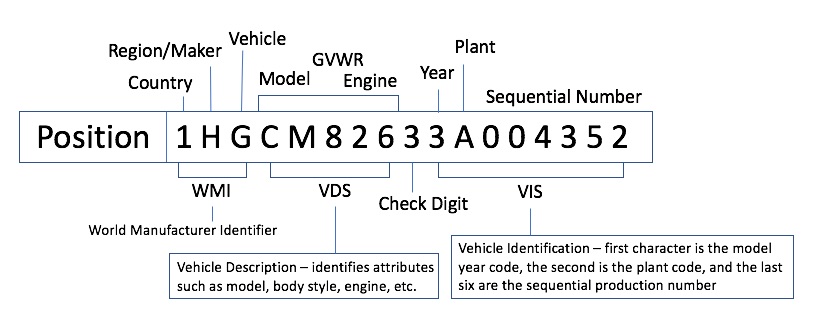
The VIN had to be expanded because when they were first designed nobody predicted just how many cars it would be on earth. I usually stress that a key should have
Validation = a dependable method of determining if the encoding is correct. This could be a regular expression, check digits, a range rule, etc.
Verification = okay the codes correct, but does it actually identify a real entity in the model?
For example, there are five digit potential ZIP Codes that were really never issued. It's valid but it's not real.
Some people like to add another attribute; stability. At one extreme, the identifier can be incredibly stable because it's immutable. For example (longitude, latitude) might have something different from time to time at that location, but that location doesn't ever change. At the other extreme, I had a friend who worked for a New York brokerage firm that required him to use a dongle on his computer. This piece of hardware and software constantly changed his passwords and identifiers every few minutes for security. Most of us work with things somewhere in between.
You had worked retail, you would've gone from the 10 digit UPC codes to13 digits to the current GTIN standards. If you're in healthcare, you have the ICD code upgrades. Etc.
The real trick for good design is that when an encoding changes, you have a migration path. It's really nice if that migration path can be done with an algorithm (in the book trade migration from ISBN–10 to ISBN-13).
Please post DDL and follow ANSI/ISO standards when asking for help.
- jcelko212 32090 - Saturday, February 9, 2019 4:40 AM
Heh... yes... I get all that. But, we've gotten way off the subject and you've still not identified something reasonable to use as a PK
for a Customer table other than the verboten Tax ID and the not 100% common DUNs.--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
A VIN could be repeated after 30 years. That's because the Year character repeats on a 30-year cycle, using 0-9 and 20 alphabetic characters (excluding those that look like numbers, I, O, etc.)
While it is unlikely that the first 8 characters representing values would exactly match 30 years apart when the last 8 characters repeat, it is a possibility. One that neither the government nor the auto companies worry about.
- gvoshol 73146 - Monday, February 11, 2019 6:01 AM
And even if it didn't have a 30 year cycle, it still wouldn't do squat for a customer table. 😉
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden - Friday, February 8, 2019 3:27 PM
Thanks Jeff! This made more sense when I read the comments going back to the OP. Now I know what "God Numbers" are too - I was always curious about what that was.
"I cant stress enough the importance of switching from a sequential files mindset to set-based thinking. After you make the switch, you can spend your time tuning and optimizing your queries instead of maintaining lengthy, poor-performing code."-- Itzik Ben-Gan 2001
- Alan.B - Friday, February 8, 2019 2:49 PM
It is a scalar value because it cannot be decomposed in a meaningful manner. It identifies one and only one entity
Please post DDL and follow ANSI/ISO standards when asking for help.
- jcelko212 32090 - Tuesday, February 12, 2019 1:55 PM
Sorry but the VIN is an intelligent value that provides specific information regarding a vehicle. For North America there is even an algorithm that you can use to validate the VIN.
- ScottPletcher - Friday, February 8, 2019 2:44 PM
[IDENTITY] is a physical locator
>> No, it's not. "1" is meaningless as any type of physical locator. <<
you also feel that the ticket the valet in the parking garage gave you is totally unrelated to where your car is? I disagree.
>> Just because physical inserts are used as an easy mechanism to trigger a number increment doesn't mean that the number is necessarily a "physical locator". Why can't you accept that? <<
Have you ever had a course in basic data modeling? We try to separate the logical data model from the physical implementation(s). Let’s take a look at automobiles since were working on VINs. We know that is an identifier for vehicles. We know we can physically determine what it is by going out and looking on our automobile, motorcycle or whatever. We do know that the VIN will be the same everywhere we use it – our auto insurance, title and registration, dealer warranty, etc.
Now let’s consider the IDENTITY property for table. I have no way of finding it before I put the entity into my schema. that’s because it’s not a property or attribute of any entity. It belongs to the physical storage, on only one machine. It is created at insertion! It is based on the disk, and a file system with sequential records. I would have the same objections if you were using a hashing algorithm and exposed it.
>> In general, we just want a simple way to get a guaranteed unique, never-changing internal key value. Sure, the natural key, say an SSN, will still be stored, but I'll never make it the actual key. That would violate security concerns, and besides which a SSN can change, that fact alone rendering it an invalid key choice for me. SSN can be verified externally, as you insist for your keys, but that's not enough for me to prefer it as a key. <<
When you talk about internals, you’re talking about physical storage and using things to get physical locations inside that storage. You’re not talking about a valid data model. Also, I believe that keys can change.in fact, I’ve actually watched it happen! I was in the book business. Many decades ago and I watched the ISBN – 10 be replaced by the current ISBN – 13. The same things happening with GTIN in retail (also this year, the GTIN can no longer be reused, so give you your never changing value).
>> As to VINs, they're too long and complex to use internally to IDENTITY vehicles. Again, I'll absolutely store the VIN, and it's certainly a candidate key, but it's just impractical for most common business uses of it. I canThat said, a car dealership, for example, might have some tables keyed on the actual VIN itself, but most companies won't need that. <<
Actually, any company that deals with automobiles or other vehicles not only has to have it, but finds no problem using it. You are basically trying to go back to pointer chains! Now what routine do you have been make sure that I’d your IDENTITY value always matches to the particular car. Oh, how do you guarantee that the other databases in which your car appears also have exactly the same IDENTITY value? If it really was a key and identified your particular automobile, then it would be the same everywhere in the universe.
Isn’t that the definition of a key
>> Neither does the square of an item_price have any meaning, does it, but it clearly must be numeric. <<So you feel that the expression (item_price * inventory_quantity) is meaningless? Numerics are for computations, and the valid computations depend on what kind of scale they represent. Also, I guess you’ve never had a system where you had to do reorder points, depreciation, and other fancy computations; they do use squares and square roots.
>> Again, the practical overhead of using char for long digit-only values, such as credit card numbers, are just too severe to be ignored. The overhead of the massive new numbers of CHECK constraints alone could significantly damage system performance. <<
Credit card numbers are a bad example for you. Most of them are 16 digits, broken into four groups of four. When you store it all is one god-awful number, you then have to break it apart to validate each of the four sets of four digits. Oh and of course you ever want to display it, you have to translated from internal binary into a string anyway. I hate to tell you, but in the 21st century, storage is not the consideration it was when you are writing for punch card systems. However, accurate data is
.
>> Customer numbers can also have check digits, but they're still most practically stored as a number, not a string. <<How many check digit routines have you written? The check digit is part of the identifier, usually in the last position (the rightmost). This is because the string was originally scanned from left to right in old machinery. The algorithms depend not on the value of the digits, but on the weight assigned to their position within the string and the string has to be of a known length. The check digit is stored as a character, not as a number! I don’t know if you can get a copy of it, but there was a good book on check digit algorithms from the Mathematics Centre in the Netherlands.
Please post DDL and follow ANSI/ISO standards when asking for help.
- jcelko212 32090 - Friday, February 15, 2019 2:56 PM
No, my db structure has nothing whatsoever to do with a parking garage. Neither does an identity value.
I've done lots of data modeling, and on system that did billions of dollars worth of transactions. A logical data model gets converted into a physical data model. At the logical level, there would never be an identity, and I've argued that very point with many others here. In fact, as I've noted on this site many, many times, that over-reliance on clustering by identity is the single biggest myth in db design. But, there are times that when converting a logical model to a physical model, an identifier can be acceptable to use as a controlled, guaranteed-to-never-change key value.
As you yourself just noted, VIN does not give me that. So, for physical lookups, and when appropriate clustering, I could use identity so that it will never change. Otherwise, when VIN changed, I'd have to go thru many tables changing it everywhere it appeared. That, too, is part of the reason for logical data modeling, to avoid having to change values in multiple tables! So, yes, if you've modeled the data poorly, your keys may be constantly changing and you may lose data or misinterpret data as a result.
If it really was a key and identified your particular automobile, then it would be the same everywhere in the universe.
Isn’t that the definition of a keyBizarre q. Not, not at all. I would never expect one our clients to be identified exactly the same way by us as by, say, Amazon.com. *You* might expect that, using a DUNS, but that's not only not required, it's a huge waste of our resources. We don't need to care how Amazon or anyone else identifies their clients. We need to make sure that we consistently and accurately identify our clients.
Some of our clients are only overseas. They don't necessarily use or ever need a DUNS. But we allow our clients to be in Europe or Asia. What "universal" number am I supposed to get that links our companies that do business in Europe, Asia, South America, Africa, Canada and Mexico but not the USA? And that works with our Canada-only clients, and all other single-country/continent clients.
Now what routine do you have been make sure that I’d your IDENTITY value always matches to the particular car.
The "master" table for car would have the VIN in it. As with other such "master" tables -- customer, order, etc. -- you can consistently look up the corresponding id value from that table, using whatever data you are given.Btw, the US fed govt already announced, some time back, that it intends to move away from DUNS numbers to a more open system. Best of luck to all DUNS-modeled folks who have to go change this key in every table in which it appears!
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
I'd just like to thank Joe for fighting the good fight. I'm seeing HORRIFIC assertions being posted by admittedly experienced folks.
Heck anybody trying to tell me they can't use computers to validate a credit card number (I mean EVERY VALIDATION THAT IS AVAILABLE ACCORDING TO THE SPEC), well I'd have to show them the door. Sorry, but it needs to be said. There is no excuse for this. I just hope I'm mistaken in how I'm reading such posts.
- patrickmcginnis59 10839 - Monday, February 18, 2019 7:16 AM
No one's ever said that. Like Joe, you're fighting a straw man. Of course you do any/all verifications needed for any cc (or other) value going into the db. But that doesn't affect the physical method I use internally to store that value. I'm surprised to see so many claims that it somehow should. Indeed, as with a date and a lot of other data types, the type itself helps verify the value.
If I store a cc as numeric, I don't have to valid that every char entered is numeric. I can CAST that numeric value to char or binary or any other format needed for validation. Why on earth should the validation process prevent me from saving bytes and processing overhead by storing the value as numeric rather than char??
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
- ScottPletcher - Monday, February 18, 2019 8:18 AM
Think back to what we do with cc's as an example.
We validate the number, then we authorize the account, then we authorize the transaction.
Why would we validate that the credit card number is all numeric without running the checksums? At the very time we're validating each digit, we could also be calculating the checksums. Why would we spread the validation across multiple systems. Its certainly possible that we could make this work, but we're talking about the very subjective matter about how we put together systems. I get it, this is not database administrator concerns, but its certainly on our todo list as computer professionals.
Its fine if you want to subsequently "compress" the data you are storing, but the data model isn't supposed to be concerned with that.
I get it, I could program everything with fortran and it will work fine, probably beat the snot out of SQL Server once I programmed the zillion lines needed to produce my own transactional storage that will use today's multiple cpu architectures. But that possibility is not what the relational model is about or even sensible application design for that matter.
{kind=link}
Viewing 15 posts - 46 through 60 (of 70 total)
You must be logged in to reply to this topic. Login to reply