Sort already comma separated list
- jcelko212 32090 - Wednesday, February 6, 2019 9:11 AM
Fair enough. MS could still create their own version, and explicitly specify the rules for their particular custom data type. With the advent of STRING_SPLIT and STRING_AGG, a built-in "string_array" data type doesn't seem too far-fetched to me.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
- Jeff Moden - Tuesday, February 5, 2019 7:39 PM
thats a materially bad example however. When we reference database objects, we use the names, these are the "keys" as Joe describes them. For instance, if you took two separate servers and created objects in the databases using the same names, the names will match regardless of the order they are created, however, the internal "id's" used could vary in their ordinal values, there is no guarantee that the "company" table will be assigned any particular integer id value. Microsoft gets to do this, because they understand that they're not producing natural keys, but instead they have the development experience and testing expertise to assure that these numbers are internally consistant, and given the wide range of installations they support, they can't skimp on performance and for that matter they don't have to, because after all they aren't ditching the "natural" keys, ie., the object names that are subsequenly "linked" internally. Using natural keys is inherently more correct in most cases, but with all programming efficiencies they do come with a cost, they are typicall bigger than ints after all.
Gotta agree with Joe on this, its cool if nobody agrees with me, it would just reinforce how bad the database profession has become, heck if the "professionals" had the humility to produce a genuinely valid set of "best practices" based on consensus and analysis, we wouldn't be seeing these repetitive and tiresome arguments about this sort of stuff.
edit: I just thought of a great example, take a programming language with subroutines / functions. Internally, these subroutine names resolve into actual targets, and these targets will be arbitrary addresses based on what the linker has calculated. However, the "natural" key for a subroutine name is just that, the "name", in whatever namespace its a member of. The internal id's are just the addresses where the particular load happens to land the code.
So if you take the same paradigm, the internal object "ids" are just the internal representation that the actual "name" of the object "resolves" to. Think of the primary key example "product 0001", this natural looking key actually resolves into an internal row id in storage, but we would never think it wise to refer to any database row by its internal id unless we were bypassing the usual database mechanisms and going right to physical storage, like "dump page" or whatever its called.
- patrickmcginnis59 10839 - Thursday, February 7, 2019 4:12 PM
Understood. So let me ask you, what is an SSN? It's a "God" number like what Joe is talking about. We just didn't happen to be the ones that created it. Same thing with DUNs. It's a "God" number just like the ones Joe is talking about.
Joe keeps ranting about how bad things like Identity columns are but has never responded with anything that would meet the requirements of a PK. I just want him to tell us what he would consider to be a good and proper candidate for a PK column (or columns) for a Customer table without using SSNs or DUNs and that would meet the requirements of being a PK column.
The example of object_id relates to what I'm talking about and another related subject. As you know, the object_id must be unique in the table and it doesn't actually matter what the numeric value is until it's assigned, just like in a Customer table. Further, the name of the object must also be unique, just like it should be in a Customer table. And, we get a warning if we try to change that name key using the likes of sp_rename because it could break things, just like it will in a Customer table. The object_id meets the requirements for being a PK just as a Customer_ID would. The name of the object does not, just like it wouldn't in a Customer table. Of course, you already know that and so I'm only saying it for Joe and anyone else that may be reading this.
For all the same reasons you talked about for "internal numbers", a Customer_ID would fit the bill as an "internal number" and makes an excellent PK.
As you say, it's cool if no one agrees with me. I just want them to explain their position especially when they accompany their argument with unrelated reasoning such as it can't be a number because it will never be used for math (which is actually incorrect, as well).
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden - Thursday, February 7, 2019 7:34 PM
I've seen some of those concerns with purchase order number. Sometimes you have to accept what you get, and with the customer id, they form a key that requires uniqueness. The closest you can get is to allow enough characters for the wide varieties of values you're going to get.
This sort of requirement I bet is pretty common when interchanging data. This doesn't necessarily preclude an integer as the primary key of a clustered table, heck it can be arbitrary and increasing, and narrow the lookup column for the nonclustered indexes. Using it as a business key just isn't going to be a universal thing. If you can get away with it, thats fine. Heck, time and again I've even seen end users take over a column or screen field meant for one thing and used it for another. Obviously a set back when we subsequently want to use it for the original purpose, but thats what you get.
If you want to communicate however, you probably have to share these keys, and if it isn't purely numeric then you have to do whats required to store and communicate the information.
- patrickmcginnis59 10839 - Thursday, February 7, 2019 8:25 PM
Yep... totally agreed. That's why I said "internally". Sometimes it does go external but, for internal use, it's ok to use whether you're doing math on it or not.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - paul s-306273 - Tuesday, February 5, 2019 1:21 AM
Wouldn't waste my time without getting paid really well, to do something that would waste my time, pretty much always.
He's almost always very short on facts and very obstinate and haughty defending an awful lot of stuff that when it comes
to getting stuff done, is usually quite practical as well as appropriate, but heaven forbid it not fit his standards 100% and
he has to have a few cows and a half every time. Why anyone wastes the time responding to anything he says is above
my pay grade. I'll never understand it. He's just not going to change.Steve (aka sgmunson) 🙂 🙂 🙂
Rent Servers for Income (picks and shovels strategy) - Jeff Moden - Tuesday, February 5, 2019 6:04 PM
>> using individual tax ids is wrong at so many levels not to mention that they can be changed on request. <<
I guess that’s why the IRS, state taxing agencies, etc. have something else. What is it? Is a tax identifier required by law? I keep stressing validation and verification as properties that we want an identifier. Verification can be done by having a trusted source, such as the taxing agency. This is how you do it with your local DMV and VIN numbers.
As an aside, the GTIN used to be reusable within a manufacturer’s product line. They just change the rules this year. It says that a trade item will be associated permanently with its GTIN.
>> DUNS might be right but only if they have a DUNS and they actually know what it is. <<
You can get a DUNS for free, or you can pay a little bit to get it expedited. I know I had to have one to do consulting work at Dell Computers here in Austin.
>> have you actually ever created a real database that used duns? <<
Yes. It was a consulting job for a company that makes small aircraft parts. They had to be able to supply a complete providence of the parts, and all the suppliers were required by regulation to have such a number.
>> So, if you can't use a Tax ID and you can't use a DUNs, what do YOU use? <<
you’re trying to play the “yes, but..†game. This was an avoidance procedure. We learned in our Transaction Analysis (ever read “Games People Play�) classes.
>> And phone numbers are absolutely stupid to use as a customer identifier because they violate the first and most important rule for Primary Keys... they must be immutable and phone numbers are anything but immutable. <<
I never said immutable. I said verifiable. Getting into another desirable property of data in general; stability, with immutability being the extreme of this property. At the other extreme, I have a friend who used to work for Wall Street firm whose identifiers were never stable, from minute to minute. He had to plug a dongle into his computer to keep up with the constantly changing identifiers on their system. It was something no human being could do so they had to have software and hardware. This made a very secure system, which was the idea.
Actually, phone numbers have gotten much more stable than they used to be. I can move my phone number from one mobile company to another, something I couldn’t do we only had copper wires. We’ve also found out that email addresses are remarkably stable. My wife works for a company that provides online access to television shows. Their customers are identified by their email. Validation for an email address is very easy with a horrible looking regular expression. Verification is done by sending a message to the email itself. The email also shows up in the person since the company a message.>> The same holds true for addresses. They cannot be used as a PK because they are not immutable. They're also not necessarily unique. <<
the rule in the direct mail industry is that a mailing list of any size will have a minimum of 10% incorrect addresses. People move. Street names change. Etc. it also depends what your audience is like. Senior citizens tend not to move, while younger people do. However, if you want to get to the lot and not a person, then this works pretty good. We also have the CASS standards for validation.it was never intended as an identifier for a person
.
>> And I don't need to produce documentation on what those requirements are because, of all the people in the world, you should know already. <<humor me and quit playing the “yes, but†game. Or better yet, tell me what the right answer is. With the thing that will identify all customers of all types for all time. The Kabbalah number again!
Please post DDL and follow ANSI/ISO standards when asking for help.
-
>> But to create a primary key with an int or bigint all you need to do is define the table like this:
CREATE TABLE My_Table
(my_table_id INTEGER IDENTITY(1,1) NOT NULL PRIMARY KEY CLUSTERED,
col1 NVARCHAR(20) NOT NULL,
col2 NVARCHAR(20) NOT NULL );
Then you can forget about it, no need to invent some text column which needs a complicated algorithm to work out the value. <<Your solution of using an IDENTITY property (not a column!) has all kinds of problems. It is a table property that belongs to only one table, and only one implementation of one particular SQL product on only this machine. It has nothing whatsoever to do with the entities being modeled. It's a physical locator, that Sybase implemented because their first products were on UNIX based machines. The file system was based on a magnetic tape which was mapped over to a sequential file on the early disk drives.
Think about a VIN number. I can validate it with a regular expression. I can verify it by going to my local DMV, Carmax, the manufacturer, and any other number of trusted sources. That's why my auto insurance company uses it. This is why the same car can be referenced in so many different databases. If worse comes to worst, I can go over and physically take the VIN number off the dashboard manually.
What you're doing is using a physical locator and building pointer chains. Essentially, your IDENTITY is like the parking space number in a single garage building. Oh, since it is a table level property and cannot be a valid column and it is not an attribute of whatever the table is modeling. Therefore, by definition, it can never be part of a key.
>> You also don't usually need to display the primary key anywhere, you just use it for joins and uniqueness. <<
Actually, I found it to be quite the opposite. You're not displaying your locator because it has nothing to the data model. I'm constantly displaying the keys because keys are part of the data. A very important attribute of each entity. Can you really imagine not having a VIN an automobile database or failing to show it?
>> If you had a database with 400 tables in it each one having a text column for the primary key it would become a total nightmare to maintain. <<
First of all, after 35 years of doing databases, I have seldom had any schema with that many tables. It's usually a sign of a bad design (lots of attribute splitting, mimicking individual tape files with tables, etc.). And no, it isn't.
>> There also is some maths done on these columns: 1 is added to it to get the next value.<<
The next value of what? It's an identifier, which is on a nominal scale by definition. Please tell me you don't believe that the square root of your credit card number has some meaning. Oh,wait a minute! You're still thinking of pointers and sequential file allocations on magnetic tape, not RDBMS.
Please post DDL and follow ANSI/ISO standards when asking for help.
- jcelko212 32090 - Friday, February 8, 2019 12:42 PM
Heh... humor me for a minute. We're not actually talking about the accuracy of mail lists or whether or not you were able to personally get a DUNs. We're talking about what people can use as a PK in their tables and you what do you do? You come up with nonsense like it can't be a number because it will never be used in a calculation.
So I'll ask again, if you can't (and you should not in most businesses) use TaxIDs for customers and most of your customers don't have a DUNs number, what would YOU use for a PK that follows the rules of a PK?
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - jcelko212 32090 - Friday, February 8, 2019 2:04 PM
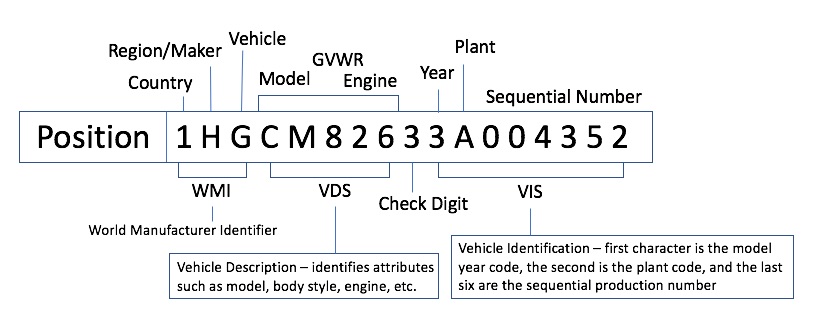
Heh... VIN numbers are actually a violation of first normal form.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - jcelko212 32090 - Friday, February 8, 2019 2:04 PM
I tend to prefer more natural keys than most people on this site, btw, but many keys are still best kept to simple numbers.
[Identity] is a physical locator
No, it's not. "1" is meaningless as any type of physical locator. You're the one that's fixated on how magnetic tape and old disks work. No one else thinks at all about that stuff any more. You can't seem to separate the mechanism tof generating the number with it's actual meaning or usage. Just because physical inserts are used as an easy mechanism to trigger a number increment doesn't mean that the number is necessarily a "physical locator". Why can't you accept that?In general, we just want a simple way to get a guaranteed unique, never-changing internal key value. Sure, the natural key, say an SSN, will still be stored, but I'll never make it the actual key. That would violate security concerns, and besides which a SSN can change, that fact alone rendering it an invalid key choice for me. SSN can be verified externally, as you insist for your keys, but that's not enough for me to prefer it as a key.
As to VINs, they're too long and complex to use internally to identity vehicles. Again, I'll absolutely store the VIN, and it's certainly a candidate key, but it's just impractical for most common business uses of it. That said, a car dealership, for example, might have some tables keyed on the actual VIN itself, but most companies won't need that.
Please tell me you don't believe that the square root of your credit card number has some meaning.
Of course not. Neither does the square of an item_price have any meaning, does it, but it clearly must be numeric. Again, the practical overhead of using char for long digit-only values, such as credit card numbers, are just too severe to be ignored. The overhead of the massive new numbers of CHECK constraints alone could significantly damage system performance. Customer numbers can also have check digits, but they're still most practically stored as a number, not a string.SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
- Jeff Moden - Friday, February 8, 2019 2:09 PM
Why so? If I were to use a VIN number as an identifier because it's unique, is it automatically a violation of 1NF? Or does it only become a violation of 1NF when I treat it as as a concatenated series of values?
I would not use a VIN for this, I'm asking out of curiosity. This is something I haven't thought about much.
"I cant stress enough the importance of switching from a sequential files mindset to set-based thinking. After you make the switch, you can spend your time tuning and optimizing your queries instead of maintaining lengthy, poor-performing code."-- Itzik Ben-Gan 2001
- Alan.B - Friday, February 8, 2019 2:49 PM
For most people, I don't think VINs are a 1NF violation. If the separate pieces are not relevant to you, then I don't see any problem with storing it as a single value. For Ford or GM motor company, it might be a violation of 1NF, since each part may be significant to them.
The same applies for SSN or phone number. Even the last 7-digit number is technically two separate values, but I don't split them, because that split is not meaningful to me. I do separate the area code -- i.e. I never store a single 10-digit phone number -- because the area code is relevant to any phone number.
For the record, I split email addresses in my design for typical 1NF reasons. The domain is completely independent of the first part. And I encode at least the domain, again for typical data normalization reasons. If a domain changes, I shouldn't have to change it in gazillion tables. I prefer to encode the first part too, but I'll let that go if the developer/business is adamant. Btw, I also don't store the "@", since it's a waste of space.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
- Alan.B - Friday, February 8, 2019 2:49 PM
First, and to be clear, there is no question that VINs make a great PK for all the reasons and rules that a PK must be and I wouldn't hesitate to use it. But, technically, they violate the rules of columns which must contain an attribute and should only contain one type of attribute. VINs actually contain many attributes, including what Joe Celko refers to as a "God" number (sequence). So, yes... it contains many concatenated attributes.

Picture source: https://www.google.com/imgres?imgurl=https://cfx-wp-images.s3.amazonaws.com/2017/11/VIN-Decode-1.jpg&imgrefurl=https://www.carfax.com/blog/vin-decoding&h=334&w=816&tbnid=a9PlZkci-y8zuM:&q=parts+of+a+vin+number&tbnh=87&tbnw=214&usg=AI4_-kTTE2zZyBld7XuFBai1FkvW62G0NA&vet=12ahUKEwizyL_Klq3gAhXtzVkKHfi1BdwQ9QEwAHoECAAQBg..i&docid=6QqOyLnYddKqyM&sa=X&ved=2ahUKEwizyL_Klq3gAhXtzVkKHfi1BdwQ9QEwAHoECAAQBg--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden - Friday, February 8, 2019 3:27 PM
But none of that is relevant to me. They're not "attributes" to mean since they have no business value to me. Besides, VINs actually have different formats depending on year (before some year -- I forget which one -- is a different format).
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
{kind=link}
Viewing 15 posts - 31 through 45 (of 70 total)
You must be logged in to reply to this topic. Login to reply