Running Concatenation (like running totals)
-
Hi
I have table with the following contentColA ColB RowNumber
100 X 1
100 Y 2
200 K 1
200 L 2
200 M 3From this table, I need only 1 row per each distinct values of ColA, with concatenated values of ColB.
For example....
100 X,Y
200 K,L,MWithout CURSOR, is there a way to achieve this, making use of LAG or similar Window built in functions? My version of MPP DB doesn't support Cursor.
thank you
- etl2016 - Monday, October 22, 2018 1:04 PM
;WITH myTable AS (SELECT * FROM (VALUES (100,'X',1),(100,'Y',2),(200,'K',1),(200,'L',2),(200,'M',3)) T(ColA,ColB,RowNumber)),
CTE AS (SELECT DISTINCT A.ColA FROM myTable A)
SELECT A.ColA, csv.ColBs
FROM CTE A
CROSS APPLY(VALUES(STUFF((SELECT ',' + B.ColB
FROM myTable B
WHERE B.ColA = A.ColA
ORDER BY B.RowNumber
FOR XML PATH('')), 1, 1, '' ))) csv(ColBs) -
You can do this on SQL Server 2005+ like so:
-- Your Data
DECLARE @table TABLE(ColA INT, ColB CHAR(1), RowNumber INT);
INSERT @table(ColA,ColB,RowNumber)
SELECT ColA,ColB,RowNumber
FROM (VALUES
(100,'X',1),
(100,'Y',2),
(200,'K',1),
(200,'L',2),
(200,'M',3)) AS f(ColA,ColB,RowNumber);-- FOR XML PATH Solution
SELECT ColA,
colB = STUFF((
SELECT ','+t2.ColB -- Add Distinct here to remove Duplicates
FROM @table AS t2
WHERE t2.ColA = t.ColA
ORDER BY t2.RowNumber
FOR XML PATH('')
),1,1,'')
FROM @table AS t
GROUP BY t.ColA;Note the use of DISTINCT to remove duplicates. With SQL 2017 (just including for those who are curious) you can do this:
-- STRING_AGG Solution (SQL 2017+)
SELECT ColA, ColB = STRING_AGG(t.ColB,',') WITHIN GROUP (ORDER BY t.RowNumber)
FROM @table AS t
GROUP BY t.ColA;"I cant stress enough the importance of switching from a sequential files mindset to set-based thinking. After you make the switch, you can spend your time tuning and optimizing your queries instead of maintaining lengthy, poor-performing code."-- Itzik Ben-Gan 2001
-
many thanks for the replies.
The limitations I have is the DB I am working on (the Parallel Data Warehouse), which does not support XML PATH or Cursor. However, it does support Window functions such as LAG. Is there an alternate way to the XML PATH approach?
thank you
- etl2016 - Tuesday, October 23, 2018 1:52 PM
DROP TABLE myTable
GO
DROP TABLE myResults
GO
CREATE TABLE myTable(ColA int,ColB char(1),RowNumber int);INSERT INTO myTable
SELECT * FROM (VALUES (100,'X',1),(100,'Y',2),(200,'K',1),(200,'L',2),(200,'M',3)) T(ColA,ColB,RowNumber)CREATE TABLE myResults(ColA int,ColBs varchar(100))
DECLARE myCursor cursor FOR SELECT DISTINCT ColA FROM myTable
DECLARE @ColA int
DECLARE @ColBs varchar(100)
OPEN myCursor
FETCH NEXT FROM myCursor INTO @ColA
WHILE @@FETCH_STATUS = 0 BEGIN
SET @ColBs=''
SELECT @ColBs = @ColBs + ColB + ',' FROM myTable WHERE ColA = @ColA ORDER BY RowNumber
SELECT @ColBs=LEFT(@ColBs,LEN(@ColBs)-1)
INSERT INTO myResults(ColA, ColBs) VALUES (@ColA, @ColBs)
FETCH NEXT FROM myCursor INTO @ColA
END
CLOSE myCursor
DEALLOCATE myCursorSELECT * FROM myTable
SELECT * FROM myResults - etl2016 - Tuesday, October 23, 2018 1:52 PM
Lookup LAG in the documentation for PDW. Running totals is a classic use of such a thing and I'd be surprised (maybe not) if they didn't have an example in the documentation.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - etl2016 - Tuesday, October 23, 2018 1:52 PM
You can do Recursive CTEs in PDW. I don't have time to performance test this but guarantee you that it will be slower than using STRING_AGG or XML PATH. Based on the sample data you provided I would recommend a clustered (or covering) Index on ColA, RowNumber (with ColB as an include column if using a covering index).
Sample DDL & DataIF OBJECT_ID('dbo.tbl','IF') IS NOT NULL DROP TABLE dbo.tbl;CREATE TABLE dbo.tbl
(
ColA INT NOT NULL,
ColB CHAR(1) NOT NULL,
RowNumber INT NOT NULL,
CONSTRAINT pk_tbl PRIMARY KEY CLUSTERED(ColA,RowNumber) -- POC Index
);
INSERT dbo.tbl(ColA,ColB,RowNumber)
SELECT ColA, ColB, RowNumber
FROM (VALUES (100,'X',1), (100,'Y',2),
(200,'K',1), (200,'L',2), (200,'M',3)) AS f(ColA,ColB,RowNumber);String Aggregator rCTE - iTVF:
CREATE FUNCTION dbo.STRING_AGG_rCTE (@colA INT)
RETURNS TABLE WITH SCHEMABINDING AS RETURN
WITH X AS
(
SELECT ColB = CAST(t.ColB AS VARCHAR(8000)), t.RowNumber
FROM dbo.tbl AS t
WHERE t.ColA = @colA
AND t.RowNumber = 1
UNION ALL
SELECT x.ColB+','+CAST(t.ColB AS VARCHAR(8000)), t.RowNumber
FROM X
JOIN dbo.tbl AS t ON x.RowNumber+1 = t.RowNumber
WHERE t.ColA = @colA
)
SELECT newString = MAX(colB)
FROM X;Solution:
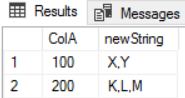
SELECT u.ColA, f.newString
FROM
(
SELECT t.ColA
FROM dbo.tbl AS t
GROUP BY t.ColA
) AS u
CROSS APPLY dbo.STRING_AGG_rCTE(u.ColA) AS f;Results:
 "I cant stress enough the importance of switching from a sequential files mindset to set-based thinking. After you make the switch, you can spend your time tuning and optimizing your queries instead of maintaining lengthy, poor-performing code."
"I cant stress enough the importance of switching from a sequential files mindset to set-based thinking. After you make the switch, you can spend your time tuning and optimizing your queries instead of maintaining lengthy, poor-performing code."-- Itzik Ben-Gan 2001
- Jonathan AC Roberts - Tuesday, October 23, 2018 5:14 PM
And the OP said they couldn't use a cursor.
Viewing 8 posts - 1 through 8 (of 8 total)
You must be logged in to reply to this topic. Login to reply