Reset SUM during Grouped selection using CTE
-
Hi all,
I've been trying for days to solve a seemingly simple problem.
DECLARE @table TABLE (id INT,type_id INT,node_id INT, value INT)INSERT INTO @table (id,type_id,node_id,value) VALUES (1,NULL,1,150)
INSERT INTO @table (id,type_id,node_id,value) VALUES (2,NULL,1,250)
INSERT INTO @table (id,type_id,node_id,value) VALUES (3,1,1,100)
INSERT INTO @table (id,type_id,node_id,value) VALUES (4,1,1,200)
INSERT INTO @table (id,type_id,node_id,value) VALUES (5,NULL,1,NULL)
INSERT INTO @table (id,type_id,node_id,value) VALUES (6,NULL,2,300)
INSERT INTO @table (id,type_id,node_id,value) VALUES (7,NULL,2,100)
INSERT INTO @table (id,type_id,node_id,value) VALUES (8,1,2,500)
INSERT INTO @table (id,type_id,node_id,value) VALUES (9,1,2,200)
INSERT INTO @table (id,type_id,node_id,value) VALUES (10,1,2,200)
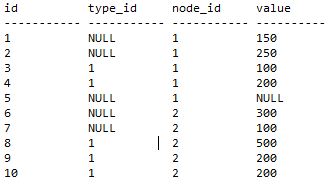
Having a table like this:
I would like to have the cumulative value based on node_id AND type_id.
As long as type_id = 1 AND the node_id is the same, add the values
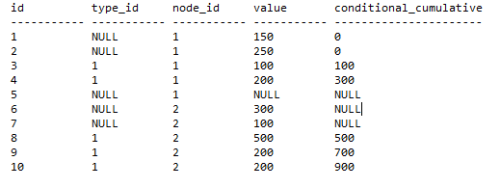
So the result would end up like this :
Is there any way of accomplishing this without using a Cursor?
I've tried cross apply, cte, self joins, partition by ; etc.Any help would be greatly appreciated.
Dennes
-
Quick question, which version of SQL Server are you on?
😎 -
Hi,
Currently 2008. No plans for 2012. In that case a 'partition by' using preceding rows would be a solution, right?Kind regards.
Dennes - Dennes Spek - Friday, June 2, 2017 5:08 AM
That is correct, this is easy on 2012 and later.
😎
Suggest you have a look at this article by Jeff ModenSolving the Running Total and Ordinal Rank Problems
-
I'm curious about the desired results.
Particularly, why is the conditional_cumulative for ID=1 given as 0, but for ID=6 it is NULL?
I don't see any differences between the rows that would explain that difference in desired result. Was that perhaps a typo, or have I just not had enough coffee? 🙂
Cheers!
- Jacob Wilkins - Friday, June 2, 2017 8:35 AM
Hi Jacob,
In the real setup the conditional_cumulative comes from function which allways gives a number, no NULLs. No NULLs anywhere by the way.
I tried to creatively emphasize it's all about the cumulatives 🙂The real setup is way more complex without designflaws, as I would say :). Except for using a cursor for this problem now, which annoys me.
Regards,
Dennes -
If the number of rows you are summing up is quite small then a triangular join is a very simple way to perform this type of calculation.
Here's why I asked the question - you end up reading each row multiple times, making it an expensive operation. The more rows there are in each group, the higher the number of reads for each row. Here's the code:SELECT *
FROM @table t
OUTER APPLY (
SELECT sumv = SUM([value])
FROM @table ti
WHERE ti.id <= t.id
AND ti.[type_id] = t.[type_id]
AND ti.node_id = t.node_id
) x“Write the query the simplest way. If through testing it becomes clear that the performance is inadequate, consider alternative query forms.” - Gail ShawFor fast, accurate and documented assistance in answering your questions, please read this article.
Understanding and using APPLY, (I) and (II) Paul White
Hidden RBAR: Triangular Joins / The "Numbers" or "Tally" Table: What it is and how it replaces a loop Jeff Moden - ChrisM@Work - Friday, June 2, 2017 9:15 AM
This actually works! Totally forgot about OUTER APPLY
Thank you very much!
In the real setup the calculations are done using like 10.000 records. So I don't think performance will be an issue.
Once again: Thank you!
Kind regards,
Dennes -
@chrism-2: Thanks for the solution!
I had a look at the Execution Plan and it does seem like a costly operation.
@Dennes: You mentioned that you were a bit concerned about using a cursor?
Would it be possible to post the results of using a cursor vs. the OUTER APPLY method? - Stefan LG - Monday, June 5, 2017 12:30 AM
Generally speaking, the OP benefits from these performance tests, which are performed by posters offering help. Nobody has offered a cursor solution Stefan, and it's unlikely to happen. Perhaps you'd like to take up the baton?
Names are important. I wouldn't want to squeeze a car onto my paella, instead of a lemon. There is no OUTER APPLY method, it's called the "Triangular Join" method, and people avoid it for the same reason that they avoid cursors - because unless you know what you are doing, performance will suck and your server might melt.
“Write the query the simplest way. If through testing it becomes clear that the performance is inadequate, consider alternative query forms.” - Gail ShawFor fast, accurate and documented assistance in answering your questions, please read this article.
Understanding and using APPLY, (I) and (II) Paul White
Hidden RBAR: Triangular Joins / The "Numbers" or "Tally" Table: What it is and how it replaces a loop Jeff Moden - ChrisM@Work - Monday, June 5, 2017 2:00 AM
I could sure try a cursor solution, although I tried to get the answer without one!
Dennes mentioned that he wanted a solution that does not use a cursor, so I am assuming he already have done a cursor-based one before?
Would just be interesting to see if your answer will give him the performance he is looking for. - Stefan LG - Monday, June 5, 2017 2:15 AM
Ok, I tried my hand on a cursor.
Overall the Execution Plan is much more complex and there are many logical reads.
However, I am not 100% sure with solution is faster/better?
Maybe the test must be done with a bigger data set.
/* @table declaration ommitted */DECLARE @tbl_Cumulative TABLE (id INT, cumulative INT NULL)
DECLARE @id int
DECLARE @type_id int
DECLARE @node_id int
DECLARE @node_id_prev int = 0
DECLARE @value int
DECLARE @cumulative int = 0DECLARE c_Test CURSOR
FOR
SELECT
id, type_id, node_id, value
FROM @tableOPEN c_Test
FETCH NEXT FROM c_Test INTO @id, @type_id, @node_id, @valueWHILE (@@FETCH_STATUS = 0)
BEGIN
IF (@node_id_prev = 0) OR (@node_id <> @node_id_prev)
SET @cumulative = 0IF (@type_id = 1)
SET @cumulative = @cumulative + @value/* Insert cumulative value into temporary table */
/* The CASE statement is purely to simulate the result of the example - logic might not be as intended */
INSERT INTO @tbl_Cumulative (id, cumulative)
SELECT @id, CASE WHEN @type_id IS NULL AND @node_id = 2 OR @value IS NULL THEN NULL ELSE @cumulative ENDSET @node_id_prev = @node_id
FETCH NEXT FROM c_Test INTO @id, @type_id, @node_id, @value
ENDCLOSE c_Test
DEALLOCATE c_TestSELECT
t.*, c.cumulative AS conditional_cumulative
FROM @table t
LEFT OUTER JOIN @tbl_Cumulative c ON c.id = t.id -
Depending on the data set, using a cursor may not be the worst option, here is a quick example
😎USE TEEST;
GO
SET NOCOUNT ON;DECLARE @table TABLE (id INT,type_id INT,node_id INT, value INT)
INSERT INTO @table (id,type_id,node_id,value) VALUES
(1,NULL,1,150)
,(2,NULL,1,250)
,(3,1,1,100)
,(4,1,1,200)
,(5,NULL,1,NULL)
,(6,NULL,2,300)
,(7,NULL,2,100)
,(8,1,2,500)
,(9,1,2,200)
,(10,1,2,200);DECLARE @RTTable TABLE (id INT,type_id INT,node_id INT, value INT, RTVal INT)
DECLARE @id INT = 0;
DECLARE @type_id INT = 0;
DECLARE @node_id INT = 0;
DECLARE @value INT = 0;
DECLARE @RTVal INT = 0;
DECLARE @Rtype_id INT = 0;
DECLARE @Rnode_id INT = 0;DECLARE R_SET CURSOR FAST_FORWARD
FOR
SELECT
T.id
,T.type_id
,T.node_id
,ISNULL(T.value * (0 + SIGN(T.type_id)),0) AS [Value]
FROM @table T
ORDER BY T.id ASC;OPEN R_SET;
FETCH NEXT FROM R_SET
INTO @id,@type_id,@node_id,@value;
WHILE @@FETCH_STATUS = 0
BEGIN
IF (@type_id = @Rtype_id) AND (@node_id = @Rnode_id)
BEGIN
SET @RTVal = @RTVal + @value
INSERT INTO @RTTable(id,type_id,node_id,value,RTVal)
VALUES (@id,@type_id,@node_id,@value,@RTVal)
END
ELSE
BEGIN
SELECT @RTVal = @value
,@Rtype_id = @type_id
,@Rnode_id = @node_id;
INSERT INTO @RTTable(id,type_id,node_id,value,RTVal)
VALUES (@id,@type_id,@node_id,@value,@RTVal)
END
FETCH NEXT FROM R_SET
INTO @id,@type_id,@node_id,@value;
END
CLOSE R_SET;
DEALLOCATE R_SET;SELECT
RT.id
,RT.type_id
,RT.node_id
,RT.value
,RT.RTVal
FROM @RTTable RT
ORDER BY RT.id;Output
id type_id node_id value RTVal
----------- ----------- ----------- ----------- -----------
1 NULL 1 0 0
2 NULL 1 0 0
3 1 1 100 100
4 1 1 200 300
5 NULL 1 0 0
6 NULL 2 0 0
7 NULL 2 0 0
8 1 2 500 500
9 1 2 200 700
10 1 2 200 900
Viewing 13 posts - 1 through 13 (of 13 total)
You must be logged in to reply to this topic. Login to reply