Removing a Key Lookup
-
Hi
I'd like to remove a key lookup against a large table and replace it with a join to a narrow index.
The code is mainly joining the table to itself
Select Count(*)
from Table1 as tab1
Inner join Table1 on tab1.Column2 = Database1.Schema1.Table1.Column2
Where tab1.Column3= 10
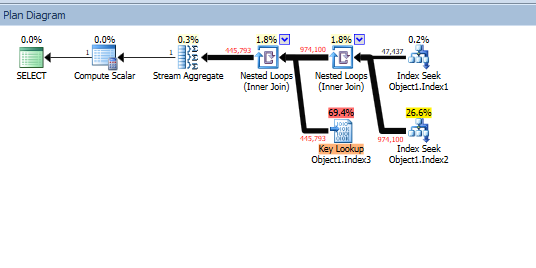
AND tab1.DateTime > Database1.Schema1.Table1.DateTimeI get an execution plan of, with a very expensive key lookup on the clustered index. I created an index with the DateTime Column but does;t use it. Can I force it's use instead of the Clustered Index?

-
Before we start to talk about tuning, I like to check a more basic thing. Are you perfectly confident that the query is returning the correct result? My interpretation of this query is "For every row X where Column3 = 10, count how many rows there are with the same value in Column2 and where DateTime is less than the DateTime for X. The return sum of these counts". That is, the returned value may exceed the total number of rows in the table.
Mind you, I know nothing of the business rules, so I may be completely off target. But it looks funny.
[font="Times New Roman"]Erland Sommarskog, SQL Server MVP, www.sommarskog.se[/font]
-
Hi Erland
Thanks for the reply....
The truth is it's not my code, I'm not sure what it's trying to achieve, I'd just like to try and make it more performant because it's killing one of my production boxes.
I'm a DBA not a developer, any "suggestions" I make is going to have to go through a whole testing cycle.
I'm really looking for ideas on how I can make it run smoother.
Thanks
Alex
-
I would try these two indexes:
CREATE INDEX IX_Table1_1 ON Table1(Column2, Column3, DateTime) INCLUDE (Id)
-- On Database 1
CREATE INDEX IX_Table1_1 ON Table1(Column2, DateTime)Also change the COUNT(*) to COUNT(tab1.ID), Assuming you have a NOT NULL ID column, any other not null column would do in the count though.
-
Hi Jonathon
Awesome....
This index really seemed to nail it.
CREATE INDEX IX_Table1_1 ON Table1(Column2, DateTime)
Thanks 🙂
Alex
-
I think you need to find the person or vendor responsible for this query. Trying to tune an incorrectly written query is an uphill battle.
You should be able to get rid of the key lookup with an index on (Column2, Datetime).I will need to add the disclaimer that I can trust your anonymisation can be trusted. I would not expect that query to even to run as written; those Database1.Schema1 in the middle of it is out of place.
But the query will kill your server even with that index I'm afraid, since you have a cartesian join in disguise.
[font="Times New Roman"]Erland Sommarskog, SQL Server MVP, www.sommarskog.se[/font]
-
Hi
could you explain how you worked out that
CREATE INDEX IX_Table1_1 ON Table1(Column2, DateTime)
would be a useful index
Thanks
Alex
- alex.palmer wrote:
Hi
could you explain how you worked out that
CREATE INDEX IX_Table1_1 ON Table1(Column2, DateTime)
would be a useful index
Thanks Alex
Just by looking at the join:
tab1.Column2 = Database1.Schema1.Table1.Column2
AND tab1.DateTime > Database1.Schema1.Table1.DateTimeYou can imagine two lists sorted on (Column2, DateTime) then to match them with those criteria you could just move down one list and easily match it to the other list.
-
Look at my verbal description. We want to find rows with a the same value in Column2 and where DateTime is bigger the ours. Thus, both columns need to be in the same index, and as always when you have an equi-condition and a range condition, you want the equi-condition first.
[font="Times New Roman"]Erland Sommarskog, SQL Server MVP, www.sommarskog.se[/font]
-
What you need is a covering index. Read up on that topic. Basically, it's called covering, because it contains all the key and projected columns referenced by the query which eliminates the need to perform bookmark lookups on the table to fetch supplemental columns. You build a covering index by leveraging the INCLUDE clause of the CREATE INDEX statement.
"Do not seek to follow in the footsteps of the wise. Instead, seek what they sought." - Matsuo Basho
-
I would of that the best index would be:
(Column3, Column2, DateTime)
given the WHERE condition.
Particularly if you later use the same query with:
Where tab1.Column3= 9
to query a different column.
And I'd move the WHERE condition into the JOIN, since JOIN typically gets evaluated first.
Select Count(*)
From Table1 as tab1
Inner join Table1 tab1b ON tab1.Column2 = tab1b.Column2 AND tab1.DateTime > tab1b.DateTime
Where tab1.Column3= 10SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
Scott,
I don't think your suggested index would help much, since the WHERE tab1.Column3 = 10 condition isn't as much the problem as the triangular self join from tab1 to tab2 on Column2 and DateTime. There is no condition on what tab2.Column3 should be.
-
I agree with Chris. The query requires two indexes: one for (Column3) INCLUDE (Column2, DateTime) and one for (Column2, DateTime). The first index is required to satisfy the condition Column3 = 10, the other condition is required to satisfy the join condition. That is, first find all rows where column3 is 10, and then for each for find all rows that match on Column2 and DateTime.
Apparently, the table already had a good index on Column3 in place, since where was no key lookup in that part of the plan.
Since it is a self-join it is a little confusing, but think of the two instances as separate tables.
[font="Times New Roman"]Erland Sommarskog, SQL Server MVP, www.sommarskog.se[/font]
-
Yeah, I was incorrectly thinking of column3 also matching.
I don't like having to have duplicative indexes. I'd probably go with just:
( column2, datetime ) INCLUDE ( column3 )
Sure, that index has to be scanned twice, but, initially at least, I think I prefer that to a dup index to fully maintain.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
Viewing 14 posts - 1 through 14 (of 14 total)
You must be logged in to reply to this topic. Login to reply