Remove partitioning
-
We have a large table where development created a partitioned unique non-clustered index years ago. The table itself shows as not partitioned. The whole thing is way out of date and I'd just like to remove partitioning and consolidate the files/filegroups into Primary. In QA, how should I proceed?

-
I'd just like to remove partitioning and consolidate the files/filegroups into Primary
I have to ask, why? What's wrong with it the way it is? What advantage do you expect to gain? What is your goal other than personal preference?
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
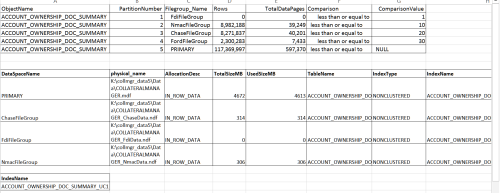
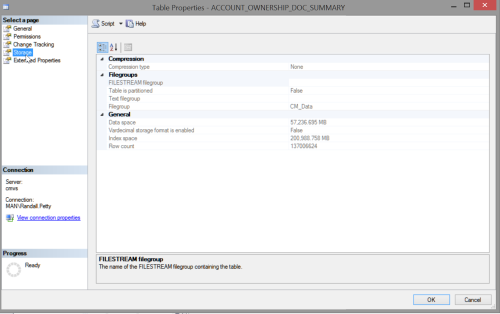
The partition scheme was put in place by development ( pre-DBA ) many years ago and only covers 3 of our original customers, one of which is no longer a customer although their data is still in place. The other 3,000 + customers and 117 million records in this table fall in to "partition 5" other -- Primary file group. Since the database is already spread over 20 files on a number of netapp LUNs, this old partitioning arrangement isn't needed, is very unlikely to be expanded to cover the bulk of our clients ( and may be hurting performance ).
I'm not sure about how to verify the help/hurt, but I do see the unique NC ( non aligned ) partitioned index in some execution plans. Doing much of anything with such a large table can easily be a weekend project, so if I can verify it's not hurting, might be best left alone. It just seems, at a minimum, untidy.
-
At a high level, all of the partitions must be merged to a single partition. All tables are "partitioned" in that they have a single partition.
I've not done a deep dive on the article but the following seems to be a reasonable approach.
http://www.patrickkeisler.com/2013/01/how-to-remove-undo-table-partitioning.html--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Thanks for the link. I'll dig into it ( scanned it last week ).
I understood about every table having at least one partition -- but it is odd that management studio shows this table as not partitioned -- I guess that's because the partitioned index is "non aligned."
- Indianrock - Saturday, February 11, 2017 5:49 PM
It may, indeed, not be partitioned. It may only be the index(es), which does seem very odd indeed. I wasn't even aware that such a thing could occur.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
As a bit of a sidebar, how much of the data is subject to change? Does the data in the table become totally static after some period of time? If so, consider some form of Temporal Partitioning where the older (probably by month), static rows are made to live in READ_ONLY monthly (forexample) partitions that no longer need to be backed up or have any type of index maintenance applied. It's a huge time saver for nightly runs.
I have a single such table that currently has a bit more than 800GB (call recordings for about 8 years). Even back when it was "only" a half TB (500GB), the nightly backup times and size on disk (we always keeps 2 nightly backups) were just insane. After partitioning and setting the legacy monthly file groups to READ_ONLY (we did backups of each partition once done) we were able to limit our backups to only the current month, which normally come in at about 11GB at the end of the month (nearly nothing at the beginning of the month).
It also allows us to do "piece-meal" restores. If one part of a disk goes bad, we can do an "online piece-meal" restore of just the month or two affected without taking the database offline. It also affords the ability to "get back in business" for a partial restore of the guts of the system and the current month in about 10 minutes instead of hours. Then we can take our time restoring the READ_ONLY file groups without much interference in the use of the database.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Much of the data isn't static.... the following is from an email I sent out to our team this morning on a search that uses this partitioned index
This is the basic search which specifies a client and a double wildcard LIKE on a portion of the VIN number. It orders by the AccountID.
The original form includes the accountID and ownership doc id which I’d guess have no value for the customer. This ran 9 minutes. Removing those two and ordering by Account Number reduced the run time to 23 seconds. Leaving the original columns in and dropping the order by altogether gave a runtime of 18 seconds. All 3 execution plans are attached.-- PROD:
-- 1. AS IS 9 minutes Sunday morning
-- 2. remove accountID, ownershipdocid and order by 9 (accountnumber) 23 seconds
-- 3. Original with no order by 18 secondsOriginal form – uses the partitioned index on the summary table and winds up with huge variance between estimated rows and actual rows. This partitioned index only carves out partitions for clients ( obfuscated ) Nxxx, Cxxx and deactivated client Fxxx. Hxxx and most of our clients aren’t included in this old partitioned index scheme.
Original form of the query
exec sp_executesql N'SELECT TOP 100 AccountOwnershipDocSummary02.ACCOUNT_ID AS AccountId,AccountOwnershipDocSummary02.OWNERSHIP_DOC_ID AS OwnershipDocId,
AccountOwnershipDocSummary02.OWNER_FULL_NAMES AS Owners,AccountOwnershipDocSummary02.BORROWER_FULL_NAMES AS Borrowers,AccountOwnershipDocSummary02.OWNERSHIP_DOC_MODIFIED_MANUFACTURER_ID AS OwnershipDocVin,AccountOwnershipDocSummary02.ACCOUNT_MODIFIED_MANUFACTURER_ID AS ModifiedAccountVin,AccountOwnershipDocSummary02.ORIGINAL_ACCOUNT_MANUFACTURER_ID AS OriginalAccountVin,AccountOwnershipDocSummary02.OWNERSHIP_DOC_ISSUING_STATE_ABBR AS OwnershipDocState,AccountOwnershipDocSummary02.CLIENT_ID AS ClientId,AccountOwnershipDocSummary02.LIENHOLDER_IDENTIFIER AS LienholderIdentifier,AccountOwnershipDocSummary02.CUSTOM_ATTRIBUTE_1 AS AccountNumber,AccountOwnershipDocSummary02.CUSTOM_ATTRIBUTE_2 AS LoanNumber,AccountOwnershipDocSummary02.CUSTOM_ATTRIBUTE_3 AS LoanSuffix,AccountOwnershipDocSummary02.CUSTOM_ATTRIBUTE_4 AS Branch,AccountOwnershipDocSummary02.EXPECTED_TITLING_STATE_ABBR AS AccountState,AccountOwnershipDocSummary02.STATUS AS Status,AccountOwnershipDocSummary02.LICENSE_NUMBER AS LicenseNumber,AccountOwnershipDocSummary02.OWNERSHIP_DOC_DOCUMENT_NUMBER AS TitleNumber,Client14.SHORT_NAME AS ClientShortName, @LargeClient2 AS LargeClient FROM ACCOUNT_OWNERSHIP_DOC_SUMMARY AS AccountOwnershipDocSummary02 INNER JOIN ORGANIZATION AS Client14 ON AccountOwnershipDocSummary02.CLIENT_ID=Client14.ORGANIZATION_ID WHERE ((AccountOwnershipDocSummary02.CLIENT_ID = @DerivedTable01_CLIENT_ID20 AND ((AccountOwnershipDocSummary02.CUSTOM_ATTRIBUTE_1 LIKE @DerivedTable01_CUSTOM_ATTRIBUTE_141))))
ORDER BY 1',N'@DerivedTable01_CLIENT_ID20 int,@DerivedTable01_CUSTOM_ATTRIBUTE_141 varchar(8000),@LargeClient2 int',@DerivedTable01_CLIENT_ID20=11330,@DerivedTable01_CUSTOM_ATTRIBUTE_141='%174779710%',@LargeClient2=1--Parameter Compiled Value
--[@LargeClient2] (1)
--[@DerivedTable01_CUSTOM_ATTRIBUTE_141] '%174779710%'
--[@DerivedTable01_CLIENT_ID20] (11330)
-
It sounds like you've described a non-clustered index that is partitioned separate from the base table. Can you post the definition of the index?
If that is the case and you want to get rid of the partitions, why can't you drop the partitioned index and create a new NCI in its place?
Wes
(A solid design is always preferable to a creative workaround) -
Here is the index. I need a QA environment to test, but I would definitely like to test disabling the index and then verify that none of the data for the two active clients in this partitioning scheme is missing or unavailable. There are many useful indexes on this table so I'm doubtful this index is needed and seems in some cases it's used and causes very bad estimated/actual row variances and slow plans.
ALTER TABLE [dbo].[ACCOUNT_OWNERSHIP_DOC_SUMMARY] ADD CONSTRAINT [ACCOUNT_OWNERSHIP_DOC_SUMMARY_UC1] UNIQUE NONCLUSTERED
(
[CLIENT_ID] ASC,
[ACCOUNT_ID] ASC,
[OWNERSHIP_DOC_ID] ASC
) - Indianrock - Tuesday, February 14, 2017 9:30 AM
The uniqueness affects the quality of your data, but the non-clustered index will not affect the data that exists in the underlying table. You won't loose any data by removing or disabling it.
Wes
(A solid design is always preferable to a creative workaround) - Indianrock - Tuesday, February 14, 2017 9:30 AM
If the index is deemed important, and it's only the partitioning you want to remove, you can keep the index by rebuilding it onto a single filegroup instead of the partitioning function.
To do so, use CREATE INDEX and include the DROP_EXISTING keyword: (yes, use CREATE even though the index already exists and is online)CREATE UNIQUE NONCLUSTERED INDEX [ACCOUNT_OWNERSHIP_DOC_SUMMARY_UC1]
ON [dbo].[ACCOUNT_OWNERSHIP_DOC_SUMMARY] ([CLIENT_ID], [ACCOUNT_ID], [OWNERSHIP_DOC_ID])
WITH (DROP_EXISTING = ON, ONLINE = ON) ON [PRIMARY];
GO
...I chose the PRIMARY filegroup just as an example. This should go in another filegroup.
Here's the full test script:-- Sample table
CREATE TABLE [dbo].[testing_ACCOUNT_OWNERSHIP_DOC_SUMMARY]
(
[CLIENT_ID] int NOT NULL PRIMARY KEY,
[ACCOUNT_ID] int NOT NULL,
[OWNERSHIP_DOC_ID] int NOT NULL,
[ExtraCol1] datetime NOT NULL,
[ExtraCol2] varchar(64) NULL
);
GO-- sample partition function and scheme
CREATE PARTITION FUNCTION tstPFunc(int) AS RANGE RIGHT FOR VALUES (1, 2, 3, 4, 5, 6, 7);
GO
CREATE PARTITION SCHEME tstPSchm AS PARTITION tstPFunc ALL TO ([PRIMARY]);
GOALTER TABLE [dbo].[testing_ACCOUNT_OWNERSHIP_DOC_SUMMARY] ADD CONSTRAINT [ACCOUNT_OWNERSHIP_DOC_SUMMARY_UC1] UNIQUE NONCLUSTERED
(
[CLIENT_ID] ASC,
[ACCOUNT_ID] ASC,
[OWNERSHIP_DOC_ID] ASC
) ON tstPSchm(CLIENT_ID);
GOINSERT [dbo].[testing_ACCOUNT_OWNERSHIP_DOC_SUMMARY](CLIENT_ID, ACCOUNT_ID, OWNERSHIP_DOC_ID, ExtraCol1, ExtraCol2)
VALUES (1, 100, 12, getdate(), 'testing'), (2, 200, 23, getdate(), ''), (3, 300, 33, getdate(), ''), (4, 400, 43, getdate(), ''), (5, 500, 53, getdate(), ''), (6, 600, 63, getdate(), '');
GO-- See where the rows landed
SELECT object_name(object_id) as [TableName], index_id, partition_number, row_count
FROM sys.dm_db_partition_stats WHERE object_id = object_id('[dbo].[testing_ACCOUNT_OWNERSHIP_DOC_SUMMARY]');
GO-- Remove partitioning, but keep the index by re-creating it on a target filegroup:
CREATE UNIQUE NONCLUSTERED INDEX [ACCOUNT_OWNERSHIP_DOC_SUMMARY_UC1]
ON [dbo].[testing_ACCOUNT_OWNERSHIP_DOC_SUMMARY] ([CLIENT_ID], [ACCOUNT_ID], [OWNERSHIP_DOC_ID])
WITH (DROP_EXISTING = ON, ONLINE = ON) ON [PRIMARY];
GO-- See where the rows landed
SELECT object_name(object_id) as [TableName], index_id, partition_number, row_count
FROM sys.dm_db_partition_stats WHERE object_id = object_id('[dbo].[testing_ACCOUNT_OWNERSHIP_DOC_SUMMARY]');
GO-Eddie
Eddie Wuerch
MCM: SQL -
Thanks!!



Viewing 13 posts - 1 through 13 (of 13 total)
You must be logged in to reply to this topic. Login to reply