Rebuilding Indexes very often is good?
- mig28mx - Thursday, March 22, 2018 10:59 AM
I'll have to say that you're mostly incorrect. As Brent Ozar says, "Defragging an index is a really expensive way to update statistics". Look at what you said...
Under the assumption that the query is ok and the trouble happens after the massive data insert, my best approach is there is typical cardinality problem. This presents when a query that works normal, starts to run slow from nowhere (at least that is that the users says).
If you see the execution plan, and notice that there is a big difference between estimated row count and actual row count then you have find out the confirmation of the cardinality problem.
Both of those are classic symptoms of out of date statistics... NOT fragmented indexes. As you say, if you do #3 first, you probably won't need to do #4. My observations have been that if you do #3 first, you usually won't have to ever do #4 unless you've suffered index inversion, which normally takes a database shrink to accomplish,
Restarting the instance to clear cache is insane so I hope it's not listed as #1 as the first think that you'd do. So is dropping all statistics, especially since 1) you can't drop index statistics directly and 2) if you have really big tables, you're users will form a lynch mob and come looking for you.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden - Thursday, March 22, 2018 8:04 AM
And I am excited to attend that presentation in the next 54 minutes 🙂
--Pra:-):-)--------------------------------------------------------------------------------
-
It was great meeting you tonight, Pra. Thank you for the great questions and thank you for introducing yourself. It was a pleasure.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
No rush but I am looking forward for you to release an article or post on the presentation you did yesterday. Very very good, Jeff!
--Pra:-):-)--------------------------------------------------------------------------------
- WonderPra - Friday, May 11, 2018 12:44 PM
Thank you, Pra. I'm humbled. The presentation and the code I used to do all the testing will be available on the PASS website tomorrow.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Hi Jeff,
When and where will the presentation be, I'm very interested also, but a newbie to any kind of DBA related topics. I'm based in the UK!
- simon.evans 66088 - Thursday, May 24, 2018 6:00 AM
The presentation was back on May 10th in Linvonia, MI. I've also submitted the presentation to 4 different SQL Saturdays in the US (won't know about those for a while). Of course, none of that helps folks in the UK. When I get the time, I do intend to convert it into a short series of articles here on SSC.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
By default, I typically have a daily job that will REORGANIZE (partitions) having fragmentation > 15%, and a weekend job that will REBUILD (partitions) having fragmentation > 30%, but that depends on the table/index design, the demands of the data load process, and the usage patterns of the data readers. These jobs are scheduled using Ola Hallengren's framework.
"Do not seek to follow in the footsteps of the wise. Instead, seek what they sought." - Matsuo Basho
- Eric M Russell - Friday, May 25, 2018 12:19 PM
That's part of the presentation I've put together and have already given once. Like almost everyone else, I used to use the standard "Best Practices" of 10% and 30%. It's hard to believe but it turns out that those settings not only perpetuate bad page splits (which are the sole cause of fragmentation) but they also guarantee that bad page splits will happen every day (2 bad page splits every 3 minutes at 80% Fill Factor for a 123 byte wide index). To add insult to injury, the standard "Best Practices" methods actually cause the bad page splits to occur at a steeper rate than not doing any index maintenance at all (Brent Ozar's suggestion and I prove it in the presentation, and it was great but isn't a panacea and doesn't actually prevent page splits... it just keeps them from "bunching up" and produces a more gentle rate of splitting).
And, no... I'm not calling anyone names for saying what they do and it turns out to the roughly the same as what Books Online recommends (which is what I refer to as the standard "Best Practices"). Most people just don't know the trouble they cause because most people haven't done the kind of testing I do (and the code is included as a zip file attached to the presentation).
The method I now use virtually eliminates all page splits for 4.5 weeks at an 80% Fill Factor and 8 weeks for a 70% Fill Factor before the index needs to be rebuilt and actually has fewer pages splits (and better performance) than an "append only" index of the same width even though all of those page splits are referred to as "good" page splits. For more narrow indexes, the times between defrags are even longer with 0 page splits for most of the time... and that's using a random GUID for the leading column for the testing! 😀
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
p.s. Almost forgot... One of the attendees of the presentation called me to say the new methods I've developed will be a real "game changer in the industry" and he's setting up for me to give the presentation at his company.
The bummer is that I didn't complete my testing until the day after the PASS Summit stopped taking session submittals.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
I'm also looking forward to reading the article, but from the graph, it looks like simply using a 70% fill factor almost eliminates index problems. Am I interpreting that correctly?
- pdanes - Tuesday, May 29, 2018 2:49 AM
Yes and no. From the graph I provided, the 70% Fill Factor looks pretty good compared to the other Fill Factors. However, the graph only contains the BASELINE (ever increasing with no splits), NO DEFRAG (which settles out on a nice smooth 68% Fill Factor), and 70, 80, 90, and 100% Fill Factors using the current "Best Practice" of ...
Page Count < 1,000 Pages.
No Index MaintenancePage Count >= 1,000 Pages
Check avg_fragmentation_in_percent
< 10% : No Index Maintenance
>= 10% and < 30% : Reorganize
>= 30% : RebuildThe trouble with that "Best Practice" is that it causes...
1. Concentrated periods of Page Splits
2. Perpetual Page Splits
3. Perpetual Fragmentation
4. Perpetual post maintenance performance problems.
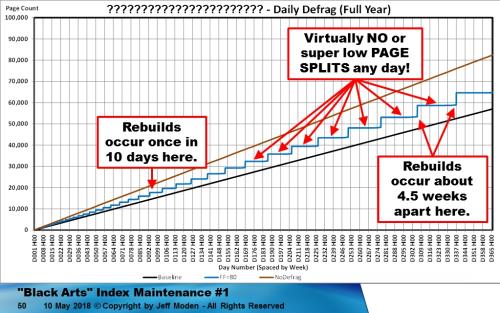
5. And, in a highly ironic "Catch 22", the perpetual need for Index Maintenance. It's a bit like drug addiction... the more you do, the more you need to do.I don't want to give up too much of the punch line, which would seriously spoil the article, but remember that any increase in page count above the baseline is due to virtually ALL bad page splits. Then look at the results from the new method I've developed. Not only does it virtually eliminate page splits for weeks at a time (which is what I thought the "Best Practices" method was supposed to do), it also greatly reduces the need for doing Index Maintenance, as well. The following chart is what happens to a random GUID Clustered Index (same as the other chart) using the new defragmentation method. (Note... this chart has a scale change from the previous chart. It's for a year rather than just 5 weeks).

In this case, the nearly vertical increases in page count are NOT due to page splits. They're due to proper Index Maintenance. The read and write performance is actually better than the BASELINE of having only an ever increasing Clustered Key because even the all "good" page splits in the ever increasing BASELINE are "bad"!
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Hm, now I'm really curious. Thanks for the explanation, although I'm still a litttle fuzzy on the details. However, my system is running well enough, so I can afford to wait for your article on the subject. Hope you let us all know when it's done.
Viewing 13 posts - 31 through 43 (of 43 total)
You must be logged in to reply to this topic. Login to reply