Query Optimizer Suggests Wrong Index and Query Plan -- Why?
-
Comments posted to this topic are about the item Query Optimizer Suggests Wrong Index and Query Plan -- Why?
Mike Byrd
-
Hi Mike,
maybe the data distribution in your table has something to do with it? From the look of the query, I would suggest the same index as the QO by simply saying: put first the =, then <>, then the range. But this is by not knowing your statistics. Does your exec plan changes if your table stats are recomputed?
Also, how come your database names are different? You have AdventureWorks2017 and AdventureWorks2017Big. The later gives you the strange exec plan.
-
If I am not mistaken, the order of the columns in the recommended index is based on the order that they exist in the table.
SELECT Tablename = OBJECT_NAME( c.object_id )
, ColumnName = c.name
, ColumnOrder = c.column_id
FROM sys.columns AS c
WHERE c.object_id = OBJECT_ID( N'Sales.SalesOrderHeader', N'U' )
ORDER BY c.column_id;Determining the best order for the columns in the index requires knowledge of the data in the columns as well as the most likely queries to be run.
The general rule of thumb is to lead with fields filtered on equality, then inequality, then range. However, in this case, I suspect that would not be the best option.
- [Status] = @status - It is highly likely that the Status column is not very selective. So if you are looking for Status=2, and Status=2 is 90% of the records, you will end up with a scan.
- [TerritoryID] <> @TerritoryID - Again, it is highly likely that the TerritoryID column is not very selective. So if you are looking for TerritoryID<>7, and TerritoryID=7 is 5% of the records, you will end up with a scan.
- As time goes on, the number of records will probably grow, and you will be querying data acrross a smaller subset of the records in the table. Also, the index stats are based on the 1st column of the index only. For this reason, I would probably opt for something like this
CREATE NONCLUSTERED INDEX IX_SalesOrderHeader_ModifiedDateStatusTerritoryID
ON Sales.SalesOrderHeader (ModifiedDate, Status, TerritoryID)
INCLUDE (SalesOrderID, RevisionNumber);I assume that SalesOrderID is the PK for the table, so it is technically included in every index on the table. However, I prefer to explicitly include it if it is being selected in the output or used in a join.
-
Can it be related to the parameter @TerritoryID parameter usage in the inequality clause? Because there is a huge gab between the estimated number of rows and an actual number of rows.
After creating the suggested index I execute the following query, I don't see the additional part of the query.
SELECT SalesOrderID, RevisionNumber,TerritoryID, ModifiedDate
FROM Sales.SalesOrderHeader
WHERE ModifiedDate >= '1/1/2012'
AND ModifiedDate < '1/1/2013'
AND [Status] = 5
AND TerritoryID <> 6;And then I execute the following query and I don't see the additional part of the query plan.
DECLARE @StartDateDATETIME
SET @StartDate = '1/1/2012'
DECLARE @EndDateDATETIME
SET @EndDate = '1/1/2013'
DECLARE @StatusINT = 5
SET @Status = 5
DECLARE @TerritoryIDINT
SET @TerritoryID = 6
-- get all territories except Canada
SELECT SalesOrderID, RevisionNumber,TerritoryID, ModifiedDate
FROM Sales.SalesOrderHeader
WHERE ModifiedDate>= @StartDate
AND ModifiedDate< @EndDate
AND [Status]= @Status
AND
TerritoryID <> 6As a last, I try the following query and I obtain a more simple query plan.
DECLARE @StartDateDATETIME
SET @StartDate = '1/1/2012'
DECLARE @EndDateDATETIME
SET @EndDate = '1/1/2013'
DECLARE @StatusINT = 5
SET @Status = 5
DECLARE @TerritoryIDINT
SET @TerritoryID = 6
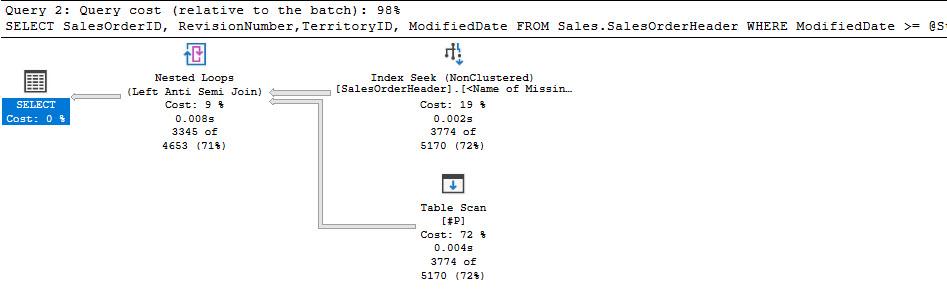
CREATE TABLE #P (Param1 INT)
INSERT INTO #P VALUES(6)
-- get all territories except Canada
SELECT SalesOrderID, RevisionNumber,TerritoryID, ModifiedDate
FROM Sales.SalesOrderHeader
WHERE ModifiedDate>= @StartDate
AND ModifiedDate< @EndDate
AND [Status]= @Status
AND
TerritoryID NOT IN (SELECT Param1 FROM #P)
-
I wouldn't make the Status a key column, since it's likely to change so often, at least in the earlier life stage of the row. The rows are small anyway, so if typically only a (relatively) short date range is searched for, I rate those scans to be less of an issue than constant deletes and inserts of rows every time the status changes. Thus, my proposed index definition would be:
CREATE UNIQUE NONCLUSTERED INDEX SalesOrderHeader__IX_ModifiedDate
ON Sales.SalesOrderHeader ( ModifiedDate, TerritoryID, SalesOrderID )
INCLUDE ( RevisionNumber, Status ) WITH ( FILLFACTOR = ... ) ON [PRIMARY];SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
I'm not sure this has to do with the issue at hand BUT, if you replace the parameter by its value directly, then the extra part of the exec plan disappears and goes back to normal...
soh.TerritoryID<>@TerritoryID -> Wrong plan
soh.TerritoryID<>6 -> Good plan. Not sure why, the seek predicate has been split in 2 parts:
In addition, why is the predicate only on the first 2 fields of the index?
Last, I had a quick look at the data distribution, status field is not filtering at all (5 for all rows).
select Status, count(*) as [Nb]
from sales.SalesOrderHeader
group by Status
/*
Status Nb
5 31465
*/
select TerritoryID, count(*) as [Nb]
from sales.SalesOrderHeader
group by TerritoryID
/*
TerritoryID Nb
9 6843
3 385
6 4067
7 2672
1 4594
10 3219
4 6224
5 486
2 352
8 2623
*/
-
I also think that the (main) issue is that the order of the columns in the proposed index,is based on the order of the columns in the table. Find a video of Brent Ozar where he explains that "Clippy" is doing this. Very entertaining and educational!
-
Missing index recommendations do not take into account cardinality, statistics, etc. when generating column order; they're grouped by equality predicate(s), inequality predicate(s), and include column(s) to possibly produce a covering index (avoiding key lookups). Within each group, the column order is just the order in the table definition, nothing fancy. For example, from the plan XML for this missing index recommendation we have an equality column on Status, inequality columns on TerritoryID and ModifiedDate (in table column order: 13 and 26, respectfully), and includes the RevisionNumber column to cover the SELECT list:
<MissingIndexes>
<MissingIndexGroup Impact="84.9354">
<MissingIndex Database="[AdventureWorks2017]" Schema="[Sales]" Table="[SalesOrderHeader]">
<ColumnGroup Usage="EQUALITY">
<Column Name="[Status]" ColumnId="6" />
</ColumnGroup>
<ColumnGroup Usage="INEQUALITY">
<Column Name="[TerritoryID]" ColumnId="13" />
<Column Name="[ModifiedDate]" ColumnId="26" />
</ColumnGroup>
<ColumnGroup Usage="INCLUDE">
<Column Name="[RevisionNumber]" ColumnId="2" />
</ColumnGroup>
</MissingIndex>
</MissingIndexGroup>
</MissingIndexes>We can visualize the content of the recommended index with a query:
SELECT Status, TerritoryID, ModifiedDate, RevisionNumber
FROM Sales.SalesOrderHeader
ORDER BY Status, TerritoryID, ModifiedDate;If we implement the recommended index, we can "seek" to 5 for the Status column, but have to read every row where TerritoryID is less than 6 or greater than 6 to evaluate ModifiedDate to determine if it falls within the specified range.
If the column order of the inequality column group is flipped in the index definition, then we get an index that looks like this (technically, the table's clustering key, SalesOrderID, is in there, too):
SELECT Status, ModifiedDate, TerritoryID, RevisionNumber
FROM Sales.SalesOrderHeader
ORDER BY Status, ModifiedDate, TerritoryID;CREATE INDEX Status_ModifiedDate_TerritoryID_Includes
ON Sales.SalesOrderHeader (Status, ModifiedDate, TerritoryID)
INCLUDE (RevisionNumber);If we implement this index definition, we can seek to Status of 5 and where the range for ModifiedDate begins within the index. Then, read all of the rows in the specified ModifiedDate range and evaluate the residual predicate on TerritoryID. This allows for fewer pages and rows to be read than with the recommended index definition for this query and its parameters.
Missing index recommendations are narrowly focussed on parts of a query (WHERE clause) and do not take into account things like ORDER BY, GROUP BY, DISTINCT, etc. where column order may allow reading fewer pages or eliminating an expensive sort operation. Don't misunderstand, I really like the feature, but I have found them to be more of a starting point when evaluating index recommendations or performing index tuning. It's Clippy saying, "hey, I got an idea".
-
Regarding the other "stuff" going on in the plan that uses the missing index recommendation definition (Nested Loops Join and Merge Interval operator branch), it's producing two rows that identify the range of values before and after a TerritoryID value of 6. For example, (and I am not saying these are the exact values produced in the Compute Scalar operators, just pseudocode) TerritoryID > 0 and TerritoryID < 6 for one execution and TerritoryID > 6 and TerritoryID < 11 for another execution. The Index Seek operator is executed twice. Rather than scanning the index once, the Optimizer chose to "seek" into the index twice on one range less than 6 and another range greater than 6.
If you were to modify the query to add on OR TerritoryID IS NULL (the column does allow NULL), the plan generated is what you'd expected, a scan of the nonclustered index, only.


Viewing 9 posts - 1 through 9 (of 9 total)
You must be logged in to reply to this topic. Login to reply