query filling up tempdb
-
Hi All,
Need some help in tune a function which is reading TB's of data and because of which tempdb gets filled in no time and causing all sorts of high cpu issue. This functions gets called every 30 mins. Not sure why they are calling every 30 mins before even the previous execution doesnt even finish and get stuck in the 3rd INSERT statement within the func call. At this point, we have asked us to disable that process. Here is how the function is called.
SELECT * FROM [dbo].[fn_monitor_cm_contact_not_merged] (null)
and it reads last 30 mins of data from the tables involved. I see they are using a lot of self-joins and they are very big tables in terms of rows. I need some help in tuning or making these query faster. I feel, that we might need to create the right indexes . I see some indexes but they are aren't being used. probably we need to drop/disable those unused indexes and create some useful indexes. other thing is, there are using a table variable for storage large resultset. is it good thing or a bad thing. As per my knowledge, table varaibles are good for small resultsets which can stored inside memory but when dealing with large resultsets, temp table is better as it can have statistics. I need some guidance on that. I am attaching the table structures, existing indexes , rowcounts and tablesizes.
Looking for some help here to tune this function code.
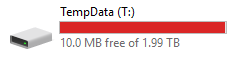
Other part of my question, how to size tempdb for such queries? I dont even if we increase to 4TB, this query alone would eat up everything when called multiple times by the app and it is a big cpu hogger and not letting other queries to finish.
if you need any additional info, please let me know.

Here is the code
<?query --
(@P0 nvarchar(4000))SELECT * FROM [dbo].[fn_monitor_cm_contact_not_merged] (@P0)
--?>
CREATE FUNCTION [dbo].[fn_monitor_cm_contact_not_merged] (@enddate varchar(30))
RETURNS @ResultSet table
(
TABLE_NAME varchar(100),
ROWID_OBJECT varchar(14),
PARTY_ID varchar(14),
status_code varchar(100),
status_desc varchar(2000)
)
AS
BEGIN
DECLARE @status_code VARCHAR(100),
@status_desc VARCHAR(2000);
BEGIN
SET @status_code = '200'
SET @status_desc = 'Success.'
Insert into @ResultSet
select DISTINCT
'C_B_PARTY_COMM',
CASE
WHEN C1.ROWID_OBJECT > C2.ROWID_OBJECT THEN
C1.ROWID_OBJECT
ELSE
C2.ROWID_OBJECT
END,
CASE
WHEN C1.ROWID_OBJECT > C2.ROWID_OBJECT THEN
C1.PARTY_ID
ELSE
C2.PARTY_ID
END,
@status_code,
@status_desc
from C_B_PARTY_COMM (NOLOCK) C1
inner join C_B_PARTY_COMM (NOLOCK) C2
on C1.COMM_VAL = C2.COMM_VAL
AND C2.HUB_STATE_IND = 1
AND C2.COMM_TYP_CD = 'EMAIL'
AND C2.CONSOLIDATION_IND = 1
AND C2.LAST_UPDATE_DATE <= DATEADD(MINUTE, -30, GETDATE())
where C1.ROWID_OBJECT <> C2.ROWID_OBJECT
AND C1.PARTY_ID <> C2.PARTY_ID
AND C1.HUB_STATE_IND = 1
AND C1.COMM_TYP_CD = 'EMAIL'
AND C1.CONSOLIDATION_IND = 1
AND C1.LAST_UPDATE_DATE <= DATEADD(MINUTE, -30, GETDATE())
Insert into @ResultSet
SELECT DISTINCT
'C_B_PARTY_ADDR',
CASE
WHEN C1.ROWID_OBJECT > C2.ROWID_OBJECT THEN
C1.ROWID_OBJECT
ELSE
C2.ROWID_OBJECT
END,
CASE
WHEN C1.ROWID_OBJECT > C2.ROWID_OBJECT THEN
C1.PARTY_ID
ELSE
C2.PARTY_ID
END,
@status_code,
@status_desc
FROM C_B_PARTY_ADDR (NOLOCK) C1
INNER JOIN C_B_PARTY_ADDR (NOLOCK) C2
ON C1.PARTY_ID = C2.PARTY_ID
AND C1.ADDR_TYP_CD = C2.ADDR_TYP_CD
and C2.HUB_STATE_IND = 1
AND C2.CONSOLIDATION_IND = 1
AND C2.LAST_UPDATE_DATE <= DATEADD(MINUTE, -30, GETDATE())
INNER JOIN C_B_PARTY (NOLOCK) P1
ON P1.ROWID_OBJECT = C1.PARTY_ID
AND P1.PARTY_TYP_CD = 'Contact'
INNER JOIN C_B_PARTY (NOLOCK) P2
ON P2.ROWID_OBJECT = C2.PARTY_ID
AND P2.PARTY_TYP_CD = 'Contact'
WHERE C1.ROWID_OBJECT <> C2.ROWID_OBJECT
AND C1.HUB_STATE_IND = 1
AND C1.CONSOLIDATION_IND = 1
AND C1.LAST_UPDATE_DATE <= DATEADD(MINUTE, -30, GETDATE())
Insert into @ResultSet
SELECT DISTINCT
'C_B_PARTY_COMM',
CASE
WHEN C1.ROWID_OBJECT > C2.ROWID_OBJECT THEN
C1.ROWID_OBJECT
ELSE
C2.ROWID_OBJECT
END,
CASE
WHEN C1.ROWID_OBJECT > C2.ROWID_OBJECT THEN
C1.PARTY_ID
ELSE
C2.PARTY_ID
END,
@status_code,
@status_desc
FROM C_B_PARTY_COMM (NOLOCK) C1
INNER JOIN C_B_PARTY_COMM (NOLOCK) C2
ON C1.COMM_VAL = C2.COMM_VAL
AND C1.PARTY_ID = C2.PARTY_ID
AND C1.COMM_TYP_CD = C2.COMM_TYP_CD
AND COALESCE(C1.COMM_USG, '1') = COALESCE(C2.COMM_USG, '1')
and C2.HUB_STATE_IND = 1
AND C2.CONSOLIDATION_IND = 1
AND C2.LAST_UPDATE_DATE <= DATEADD(MINUTE, -30, GETDATE())
INNER JOIN C_B_PARTY (NOLOCK) P1
ON P1.ROWID_OBJECT = C1.PARTY_ID
AND P1.PARTY_TYP_CD = 'Contact'
INNER JOIN C_B_PARTY (NOLOCK) P2
ON P2.ROWID_OBJECT = C2.PARTY_ID
AND P2.PARTY_TYP_CD = 'Contact'
WHERE C1.ROWID_OBJECT <> C2.ROWID_OBJECT
AND C1.HUB_STATE_IND = 1
--AND C1.COMM_TYP_CD='EMAIL' AND C2.COMM_TYP_CD='EMAIL'
AND C1.CONSOLIDATION_IND = 1
AND C1.LAST_UPDATE_DATE <= DATEADD(MINUTE, -30, GETDATE())
Insert into @ResultSet
SELECT DISTINCT
'C_B_CONTACT',
CASE
WHEN C1.ROWID_OBJECT > C2.ROWID_OBJECT THEN
C1.ROWID_OBJECT
ELSE
C2.ROWID_OBJECT
END,
CASE
WHEN C1.ROWID_OBJECT > C2.ROWID_OBJECT THEN
C1.PARTY_ID
ELSE
C2.PARTY_ID
END,
@status_code,
@status_desc
FROM C_B_CONTACT (NOLOCK) C1
INNER JOIN C_B_CONTACT (NOLOCK) C2
ON C1.PARTY_ID = C2.PARTY_ID
and C2.HUB_STATE_IND = 1
AND C2.CONSOLIDATION_IND = 1
AND C2.LAST_UPDATE_DATE <= DATEADD(MINUTE, -30, GETDATE())
WHERE C1.ROWID_OBJECT <> C2.ROWID_OBJECT
AND C1.HUB_STATE_IND = 1
AND C1.CONSOLIDATION_IND = 1
AND C1.LAST_UPDATE_DATE <= DATEADD(MINUTE, -30, GETDATE())
Insert into @ResultSet
SELECT DISTINCT
'C_B_PARTY_CONTACT_ROLE',
CASE
WHEN C1.ROWID_OBJECT > C2.ROWID_OBJECT THEN
C1.ROWID_OBJECT
ELSE
C2.ROWID_OBJECT
END,
CASE
WHEN C1.ROWID_OBJECT > C2.ROWID_OBJECT THEN
C1.PARTY_ID
ELSE
C2.PARTY_ID
END,
@status_code,
@status_desc
FROM C_B_PARTY_CONTACT_ROLE (NOLOCK) C1
INNER JOIN C_B_PARTY_CONTACT_ROLE (NOLOCK) C2
ON C1.PARTY_ID = C2.PARTY_ID
AND C1.PARTY_REL_ID = C2.PARTY_REL_ID
AND C1.CONTACT_RANK = C2.CONTACT_RANK
AND C1.CONTACT_ROLE = C2.CONTACT_ROLE
and C2.HUB_STATE_IND = 1
AND C2.CONSOLIDATION_IND = 1
AND C2.LAST_UPDATE_DATE <= DATEADD(MINUTE, -30, GETDATE())
WHERE C1.ROWID_OBJECT <> C2.ROWID_OBJECT
AND C1.HUB_STATE_IND = 1
AND C1.CONSOLIDATION_IND = 1
AND C1.LAST_UPDATE_DATE <= DATEADD(MINUTE, -30, GETDATE())
Insert into @ResultSet
SELECT DISTINCT
'C_B_PARTY_REL',
CASE
WHEN C1.ROWID_OBJECT > C2.ROWID_OBJECT THEN
C1.ROWID_OBJECT
ELSE
C2.ROWID_OBJECT
END,
CASE
WHEN C1.ROWID_OBJECT > C2.ROWID_OBJECT THEN
C1.PARENT_PARTY_ID
ELSE
C2.PARENT_PARTY_ID
END,
@status_code,
@status_desc
FROM C_B_PARTY_REL (NOLOCK) C1
INNER JOIN C_B_PARTY_REL (NOLOCK) C2
ON C1.PARENT_PARTY_ID = C2.PARENT_PARTY_ID
AND C1.CHILD_PARTY_ID = C2.CHILD_PARTY_ID
AND C1.HIERARCHY_CODE = C2.HIERARCHY_CODE
AND C1.REL_TYPE_CODE = C2.REL_TYPE_CODE
and C2.HUB_STATE_IND = 1
AND C2.CONSOLIDATION_IND = 1
AND C2.LAST_UPDATE_DATE <= DATEADD(MINUTE, -30, GETDATE())
INNER JOIN C_B_PARTY (NOLOCK) P1
ON P1.ROWID_OBJECT = C1.PARENT_PARTY_ID
AND P1.PARTY_TYP_CD = 'Contact'
INNER JOIN C_B_PARTY (NOLOCK) P2
ON P2.ROWID_OBJECT = C2.PARENT_PARTY_ID
AND P2.PARTY_TYP_CD = 'Contact'
WHERE C1.ROWID_OBJECT <> C2.ROWID_OBJECT
AND C1.HUB_STATE_IND = 1
AND C1.CONSOLIDATION_IND = 1
AND C1.LAST_UPDATE_DATE <= DATEADD(MINUTE, -30, GETDATE())
END
RETURN
ENDTable structures, index info
-
can you also get a ACTUAL execution plan of doing those sqls
and there is some duplication of access to table C_B_PARTY
take following snippet.
take following snippet.
first INNER join uses C1.PARTY_ID = C2.PARTY_ID
so the joins to
C_B_PARTY P1 on P1.ROWID_OBJECT = C1.PARTY_ID
C_B_PARTY P2 on P2.ROWID_OBJECT = C2.PARTY_ID
are accessing the exact same records - cant see a reason for it
FROM C_B_PARTY_COMM (NOLOCK) C1
INNER JOIN C_B_PARTY_COMM (NOLOCK) C2
ON C1.COMM_VAL = C2.COMM_VAL
AND C1.PARTY_ID = C2.PARTY_ID
AND C1.COMM_TYP_CD = C2.COMM_TYP_CD
AND COALESCE(C1.COMM_USG, '1') = COALESCE(C2.COMM_USG, '1')
and C2.HUB_STATE_IND = 1
AND C2.CONSOLIDATION_IND = 1
AND C2.LAST_UPDATE_DATE <= DATEADD(MINUTE, -30, GETDATE())
INNER JOIN C_B_PARTY (NOLOCK) P1
ON P1.ROWID_OBJECT = C1.PARTY_ID
AND P1.PARTY_TYP_CD = 'Contact'
INNER JOIN C_B_PARTY (NOLOCK) P2
ON P2.ROWID_OBJECT = C2.PARTY_ID
AND P2.PARTY_TYP_CD = 'Contact'and in all the queries above although you do join to C_B_PARTY those tables are then not used so I assume the only reason for having them is that you require the data to be on those tables, and you don't have foreign keys between C_B_PARTY and the other tables to ensure this ID exists.
Investigate and potentially remove both joins - if nothing else remove one of them as it is redundant.
-
I cant get the actual plan but I will try it is executing for ever, especially its getting stuck at 3rd INSERT. But I am attaching the estimated plan.
-
- frederico_fonseca wrote:
can you also get a ACTUAL execution plan of doing those sqls
and there is some duplication of access to table C_B_PARTY
take following snippet.
take following snippet.
first INNER join uses C1.PARTY_ID = C2.PARTY_ID
so the joins to
C_B_PARTY P1 on P1.ROWID_OBJECT = C1.PARTY_ID
C_B_PARTY P2 on P2.ROWID_OBJECT = C2.PARTY_ID
are accessing the exact same records - can't see a reason for it
FROM C_B_PARTY_COMM (NOLOCK) C1
INNER JOIN C_B_PARTY_COMM (NOLOCK) C2
ON C1.COMM_VAL = C2.COMM_VAL
AND C1.PARTY_ID = C2.PARTY_ID
AND C1.COMM_TYP_CD = C2.COMM_TYP_CD
AND COALESCE(C1.COMM_USG, '1') = COALESCE(C2.COMM_USG, '1')
and C2.HUB_STATE_IND = 1
AND C2.CONSOLIDATION_IND = 1
AND C2.LAST_UPDATE_DATE <= DATEADD(MINUTE, -30, GETDATE())
INNER JOIN C_B_PARTY (NOLOCK) P1
ON P1.ROWID_OBJECT = C1.PARTY_ID
AND P1.PARTY_TYP_CD = 'Contact'
INNER JOIN C_B_PARTY (NOLOCK) P2
ON P2.ROWID_OBJECT = C2.PARTY_ID
AND P2.PARTY_TYP_CD = 'Contact'and in all the queries above although you do join to C_B_PARTY those tables are then not used so I assume the only reason for having them is that you require the data to be on those tables, and you don't have foreign keys between C_B_PARTY and the other tables to ensure this ID exists.
Investigate and potentially remove both joins - if nothing else remove one of them as it is redundant.
Problem with this function call is. it never finishes. eventually had to kill it or restart sql server. so, temporarily we requested the app team to disable the schedule of this process. it ran over 12 hrs and never completed and state shows as runnable for most of the time.
-
One more observation, on that database RCSI is enabled. Is there any good reason for using (NOLOCK) hint? I feel, since it is a SELECT it should get the copy from tempdb version store when there are changes to that table. what's the drawback of having that (NOLOCK) in the selects when RCSI is turned on?
-
before we can even suggest anything else...
1 - WHY are they returning 40 Million rows on a function call? what purpose does this accomplish?
ask the devs what is this output used to - it may be a case that they should limit the number of rows returned in each call.
2 - can this be replaced with a Stored Proc - doing this would considerably reduce the table access and the need for SQL to maintain Row versions on tempdb (which is likely what is eating up all your space when this runs)
run this to check this space
SELECT
DB_NAME(database_id) as 'Database Name',
reserved_page_count,
reserved_space_kb
FROM sys.dm_tran_version_store_space_usage;potential changes - may not be correct and would need to be implemented in a non prod environment with similar size data and with a server with similar spec
Query 1
Proposed new index on C_B_PARTY_COMM
Columns
HUB_STATE_IND
CONSOLIDATION_IND
COMM_TYP_CD
COMM_VAL
LAST_UPDATE_DATE
include columns
ROWID_OBJECT
PARTY_ID
query 4
remove second join to C_B_PARTY as it is not required
Proposed new index on C_B_PARTY_ADDR
columns
HUB_STATE_IND
CONSOLIDATION_IND
PARTY_ID
ADDR_TYP_CD
LAST_UPDATE_DATE
include columns
ROWID_OBJECT
Query 3
Proposed new index on C_B_PARTY_COMM
Columns
HUB_STATE_IND
CONSOLIDATION_IND
COMM_TYP_CD
COMM_VAL
PARTY_ID
COMM_USG
LAST_UPDATE_DATE
include columns
ROWID_OBJECT
query 4
remove second join to C_B_PARTY as it is not required
change existing index SVR1_WT3JAS on C_B_CONTACT
columns
CONSOLIDATION_IND
HUB_STATE_IND
LAST_UPDATE_DATE -- new column on index
Included columns
PARTY_ID -- new include
Query 6
remove second join to C_B_PARTY as it is not required
proposed new index on C_B_PARTY_REL
columns
HUB_STATE_IND
CONSOLIDATION_IND
PARENT_PARTY_ID
CHILD_PARTY_ID
HIERARCHY_CODE
REL_TYPE_CODE
LAST_UPDATE
include columns
ROWID_OBJECT - vsamantha35 wrote:
I cant get the actual plan but I will try it is executing for ever, especially its getting stuck at 3rd INSERT. But I am attaching the estimated plan.
You have a lot of code to sort through. Can you go back to your original post an mark that INSERT with a comment that says --Gets Stuck Here so we can be absolutely sure that neither we nor you have miscounted?Never mind... see below.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
I'll also add that what looks to be the "3rd INSERT" is the only one that has non-sargable criteria in the Joins ...
AND COALESCE(C1.COMM_USG,'1') = COALESCE(C2.COMM_USG,'1') and C2.HUB_STATE_IND = 1
AND C2.CONSOLIDATION_IND = 1 AND C2.LAST_UPDATE_DATE <= DATEADD(MINUTE, -30, GETDATE())The other thing is that every one of the INSERTs is using DISTINCT. That's likely being used to overcome 1 or more "accidental CROSS JOINs" that are manifested by insufficient criteria. Normally such things can be repaired by splitting the query up and using a temp table to hold the offending data so that it's not duplicated in such a fashion.
Last but not least, all the queries are working with millions of rows, which seems to support the above problem but some of the killers is that some of the non-clustered indexes are doing MILLIONs of individual seeks.
Also, both Temp Tables and Table Variables live in TempDB and you're populating a Table Variable with 10's of millions of rows.
As they say on TV though, "BUT WAIT! DON'T ORDER YET!".
You said in your narrative in your original post that "it reads last 30 mins of data from the tables involved" and yet ALL of your queries have the following criteria.
AND C1.LAST_UPDATE_DATE <= DATEADD(MINUTE, -30, GETDATE())
Do you see anything wrong with that criteria??? 😉
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - frederico_fonseca wrote:
before we can even suggest anything else...
1 - WHY are they returning 40 Million rows on a function call? what purpose does this accomplish?
ask the devs what is this output used to - it may be a case that they should limit the number of rows returned in each call.
2 - can this be replaced with a Stored Proc - doing this would considerably reduce the table access and the need for SQL to maintain Row versions on tempdb (which is likely what is eating up all your space when this runs)
run this to check this space
SELECT
DB_NAME(database_id) as 'Database Name',
reserved_page_count,
reserved_space_kb
FROM sys.dm_tran_version_store_space_usage;- where do we see that 40 million rows being processed? will check with dev team.
- for the user db as of now, it shows 5gb as reserved_space.
-
One more question, I have in my mind, usage (NOLOCK) is any use or shall we ask developer to remove it. RCSI is enabled on the user database. do you see any problem here?
-
Also, they are using a table variable @ResultSet . I believe estimated rows will be always =1 . Replacing it with a temp table is better option?
- Jeff Moden wrote:
You said in your narrative in your original post that "it reads last 30 mins of data from the tables involved" and yet ALL of your queries have the following criteria.
AND C1.LAST_UPDATE_DATE <= DATEADD(MINUTE, -30, GETDATE())
Do you see anything wrong with that criteria??? 😉
Jeff, could you please elaborate. I didn't get it. do you for see any problem?? meaning, except 30 min its reading the remaining hell lot of data? you mean, they should be adding more meaningful filter to reduce number of rows?? is that what you are asking?
Regards,
Sam
-
I also see, dev team is using DISTINCT operator as a common practice. Is there any proper ways to re-write to the queries to avoid the usage of distinct operator but still get the desired results as expected? any good articles please suggest. I will share it with the dev team. I see this DISTINCT usage in almost all the join queries.
Regards,
Sam
- vsamantha35 wrote:Jeff Moden wrote:
You said in your narrative in your original post that "it reads last 30 mins of data from the tables involved" and yet ALL of your queries have the following criteria.
AND C1.LAST_UPDATE_DATE <= DATEADD(MINUTE, -30, GETDATE())
Do you see anything wrong with that criteria??? 😉
Jeff, could you please elaborate. I didn't get it. do you for see any problem?? meaning, except 30 min its reading the remaining hell lot of data? you mean, they should be adding more meaningful filter to reduce number of rows?? is that what you are asking?
Regards,
Sam
Jeff is right - I missed that detail when I asked you about what this was used for.
What Jeff is saying is that the code retrieves everything that is OLDER than 30 mins (e.g. the <= (less than or equal) on LAST_UPDATE_DATE <= DATEADD(MINUTE, -30, GETDATE())) while what you stated is the "it reads LAST 30 mins of data from the tables involved
so either the code is wrong or your statement is wrong (both me and Jeff think its the code)

Viewing 15 posts - 1 through 15 (of 24 total)
You must be logged in to reply to this topic. Login to reply