Proc cache slowly decreasing in size until restart is required
-
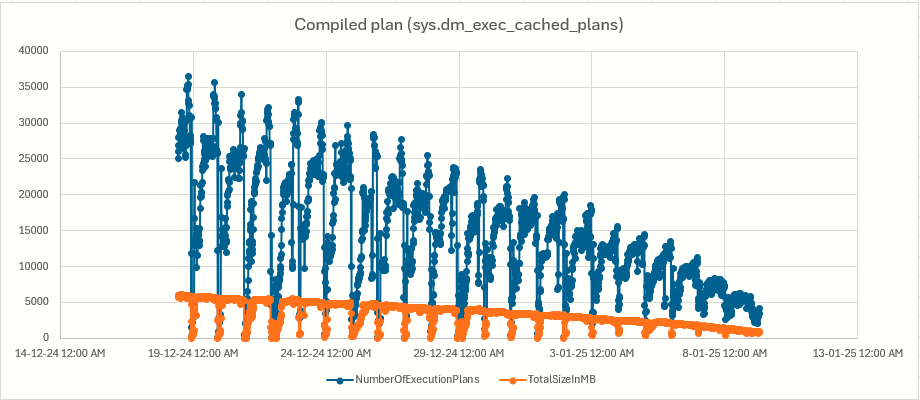
In SQL 2017 (14.0.3475.1) the size of the proc cache is slowly decreasing. The workload on the instance has the same profile every day and does not change with time. The proc cache size started at a little over 5G and after about 3 weeks is down to below 1G. Just before the previous restart, it even was 300MB. The effect of such a small proc size is a huge rate of recompilations causing severe performance problems in the app. A restart helps but is very intrusive.
The server has 16 cores and 128G RAM. Max memory is 120G. Page Life Expectancy is almost always above 2000 seconds.
The fact that this seems to be a slow and steady regression where the workload on average remains constant, suggests to me that we cannot relate it to the workload directly but we are looking at unwanted behavior in SQL Server 2017. I used the below query to monitor the cache size. We log every 15 minutes resulting in the below chart.
Has anyone ever seen anything like this? Would upgrading to 2019 or 2022 help? Google or ChatGPT gives no leads.

SELECT COUNT(*) AS NumberOfExecutionPlans,
SUM(cp.size_in_bytes) / 1048576 AS TotalSizeInMB
FROM sys.dm_exec_cached_plans cp
WHERE cacheobjtype = 'Compiled Plan' -
Thanks for posting your issue and hopefully someone will answer soon.
This is an automated bump to increase visibility of your question.
-
Like I said on the other thread with the identical name (Note: there is zero need to double post on this forum)...
This sounds like either a "Connection Leak" or a "Memory Leak". A "Connection Leak" is where no connection is ever closed and everyone gets a new connection (which take memory) or a "Memory Leak" where certain types of "Cursors" are simply not being closed and the code keeps opening new ones. It could also be some sort of "in-memory logging" that is never cleared except by a restart.
These types of things are frequently difficult to find but, man... is it ever worth it to find them and fix them.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Thanks for your response Jeff. The number of connections is stable. I should have mentioned that we have several of these database servers (1 instance per server) with comparable workload and different SQL versions. On 2019 or 2022 servers the proc cache remains constant. We are planning an upgrade on short term. Until now we might not have noticed it because of the monthly patching we're doing; it takes about a month before we hit critical levels. In December however, we had a freeze and skipped maintenance.
If we see it happening after the upgrade as well, we've got work to do.
-
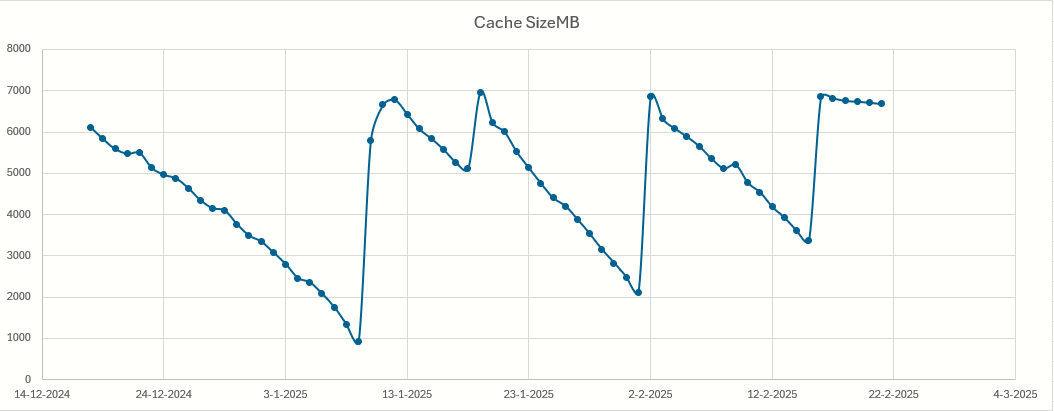
To round up this topic, we upgraded to SQL 2019 and the issue is gone or at least not a problem anymore. There is a bit of a decrease but nowhere near as steep as before.
Viewing 5 posts - 1 through 5 (of 5 total)
You must be logged in to reply to this topic. Login to reply