Precuations of reducing the VLFs
-
Hi All,
We have a database with 5TB size and has VLF near to 900.
Transaction log file size 700GB.
We are on SQL Server 2017 EE Always on availability group.
During restores/db refreshes and during AG fail over times it is taking 30-45 mins to bring the database online.
Question is how to reduce the VLFs? I don't want to remove the database from AG and if we have to resize the log file with MINIMAL DOWN TIME, then what are the precautions needs to be taken?
Regards,
Sam
-
Log File = 716,800GB
If you have 512MB VLFs - that would be 1,400 VLFs. At only 900 VLFs you have an average of less than 512MB per VLF. For each VLF to be sized at 512MB you would need an auto-growth setting of 8GB.
The rule is that one VLF will be created at the defined growth rate - if that size is less than 1/8th the size of the logs physical size. If the growth size is less than 64MB - then 4 VLFs will be created to cover the growth size. If the growth is between 64MB and 1GB - then 8 VLFs will be created - and if the growth is larger than 1GB then 16 VLFs (8GB / 16 = 512MB per VLF).
Given the current size of your log file - the growth rate would need to be less than ~86MB to satisfy the first requirement (1 VLF created) per growth. The fact that you only have 900 VLFs means you have less than would have been created if you used an 8GB growth rate.
For a 5TB database - a 700GB transaction log isn't out of the ordinary, and the fact that you only have 900 VLFs is well within the expected number and shouldn't be a concern.
Reducing the number of VLFs isn't going to resolve your issue. It isn't the size of the transaction log or the number of VLFs that is causing the databases to take a long time to recover - it is a factor of how much data is in the send and redo queues that need to be hardened on the replica or the fact that you are removing and adding databases (automatic seeding?).
A failover should be almost instantaneous if the replica is in synchronous mode and fully synchronized. If the fail over is taking a long time - then it is waiting to become synchronized before it can perform the fail over, which also means the replica you are attempting to fail over to is not fully synchronized (in either synch or asynch configurations) and has a very large redo queue or the send queue on the current primary is way behind.
I suspect your issues are somewhere else and not related to the transaction log size or number of VLFs.
Jeffrey Williams
“We are all faced with a series of great opportunities brilliantly disguised as impossible situations.”― Charles R. Swindoll
How to post questions to get better answers faster
Managing Transaction Logs -
700GB log file for a 5TB database? Have you determined what caused it to grow that large and, if you reduce the size, will it grow to be that large again?
And 900 VLFs for 700GB isn't that bad. I'd worry more about, like I said, what caused it to grow to that size.
Any bets on it being Index Maintenance?
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
If Jeffrey, thanks for your inputs. Have some doubts. please clarify.
For a 5TB database - a 700GB transaction log isn't out of the ordinary, and the fact that you only have 900 VLFs is well within the expected number and shouldn't be a concern.
What is the formula to calculate like how many VLFs we get roughly for a 5TB database ?
A failover should be almost instantaneous if the replica is in synchronous mode and fully synchronized. If the fail over is taking a long time - then it is waiting to become synchronized before it can perform the fail over, which also means the replica you are attempting to fail over to is not fully synchronized (in either synch or asynch configurations) and has a very large redo queue or the send queue on the current primary is way behind.
In that case, how to go about troubleshooting this issue to make sure there is less time involved during failover? by the way, is that under our control or based on activity happening at that time? or else during patching time, we should not allow the application connections coming to sql servers to ensure no activity is running on primary replica? or how to check if there is network bandwidth issue and tricks if thats a network latency issue?
- Jeff Moden wrote:
700GB log file for a 5TB database? Have you determined what caused it to grow that large and, if you reduce the size, will it grow to be that large again?
And 900 VLFs for 700GB isn't that bad. I'd worry more about, like I said, what caused it to grow to that size.
Any bets on it being Index Maintenance?
Yeah, we do index rebuilds quite often but I am not 100% sure. but definitely that could be one of the reasons.
Jeff, I got your point. Could you please give me some ideas on how trace out that long running query which might causing the LOG file to grow that big? or which session is taking up most of the log space in a day/week/month? based on that may be we get an idea, to tell what should be the ideal size of transaction log file. now i see some free space in the log.
-
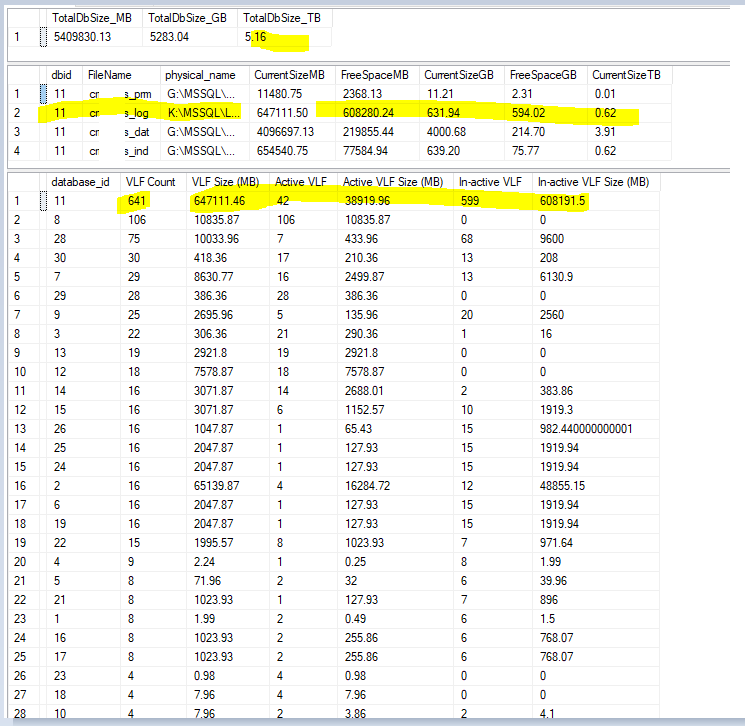
Current VLF count info and AG properties.

AG properties
- vsamantha35 wrote:
Yeah, we do index rebuilds quite often but I am not 100% sure. but definitely that could be one of the reasons.
Jeff, I got your point. Could you please give me some ideas on how trace out that long running query which might causing the LOG file to grow that big? or which session is taking up most of the log space in a day/week/month? based on that may be we get an idea, to tell what should be the ideal size of transaction log file. now i see some free space in the log.
Here's a link for the Extended Event stuff that I used as a source.
https://www.brentozar.com/archive/2015/12/tracking-tempdb-growth-using-extended-events/
It's not necessarily a "long running query" that causes the issue.
If it turns out to be index maintenance, let's talk.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
I already outlined the logic for how VLFs are created - and it all depends on how large the growth and whether or not that growth is smaller than 1/8 the physical log file size. Review the auto growth settings on the transaction log - each growth will either create 1, 4, 8 or 16 VLFs, depending on the size of the growth.
I see nothing here that would cause issues with the AG databases recovering in a timely manner. It really depends on the activity on the system at the time of failover and how you are performing those tasks.
How are you performing your failover? Are you issuing a failover command - or just restarting the primary - or something else?
And why do you need to restore any databases into the AG?
Jeffrey Williams
“We are all faced with a series of great opportunities brilliantly disguised as impossible situations.”― Charles R. Swindoll
How to post questions to get better answers faster
Managing Transaction Logs -
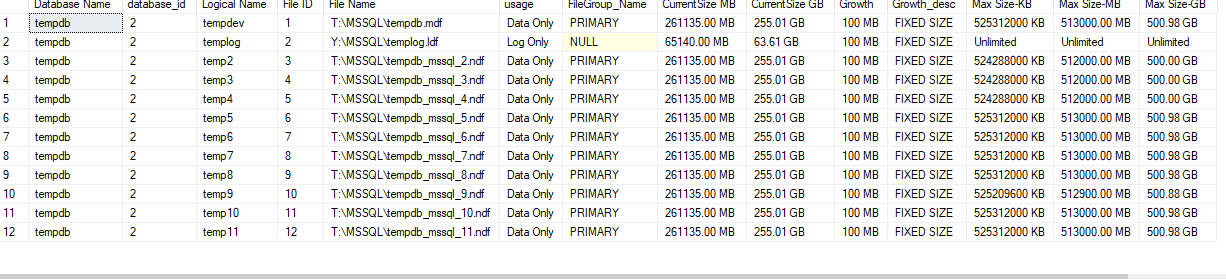
Below are the autogrowth settings.
for user db
for tempdb
How are you performing your failover?
Mostly it is automatic failover. only when we do a Disaster recovery drill, we do a manual failover
Are you issuing a failover command - or just restarting the primary - or something else?
during monthly production patching window time, they bring the secondaries down and then patch the primary.
And why do you need to restore any databases into the AG?
I meant, when we try to take a full backup from production which is in AG, and restore/refresh/clone it on non-prod environment, the database recovery taking time. In sp_wia it shows percent_complete as 99% but it will take 30-40 mins sometimes to bring the database online.


Viewing 9 posts - 1 through 9 (of 9 total)
You must be logged in to reply to this topic. Login to reply