Pivot data without aggregating
-
Greetings,
I have a table of ID's and activities like the following and I need to pivot the data as shown below into a View
ID Activity
1 Swimming
2 Skating
1 Gymnastics
3 Swimming
The Desired state is as follows:
ID Swimming Skating Gymnastics
1 1 0 0
2 0 1 0
3 1 0 0
There are 150,000 entries in the table with 40 different activities. I have tried using pivot and can get an aggregated value of ID's by activity but that is not what I am looking for. I could create a temp table and update from the base table but that is not a very elegant solution. Can Pivot be used for this purpose or should I look at other options? Thanks
-
Probably a bit messy, but what about using a CASE statement? Something along the lines of:
SELECT ID
, CASE WHEN EXISTS (SELECT 1
FROM <table> AS inner
WHERE outer.ID = inner.ID AND Activity = 'Swimming')
THEN 1
ELSE 0
...
FROM <table> AS outerWill result in 40 different CASE statements, but avoids the PIVOT. Mind you, I think that PIVOT should work as long as you don't have duplicate rows. I am not certain what issue you had with aggregated ID, but if the problem was due to duplicate rows, you could use a subquery and put a distinct on the query so you don't have any duplicate rows before you do the pivot.
I am also a bit confused about the "expected" results as I see that ID 1 has both Swimming and Gymnastics, but your expected results ONLY lists swimming. Just curious how you determine if swimming OR gymnastics should be marked? If it is based on the previous rows, how do you determine what is a "previous" row? Are you capturing any datetime information on the data? If it is a mistake in the expected results, then could you elaborate on why an aggregate on ID is problematic? To me that feels like the correct use, but if not, then I can think of alternate options, but it depends on what your results should look like...
The above is all just my opinion on what you should do.
As with all advice you find on a random internet forum - you shouldn't blindly follow it. Always test on a test server to see if there is negative side effects before making changes to live!
I recommend you NEVER run "random code" you found online on any system you care about UNLESS you understand and can verify the code OR you don't care if the code trashes your system. -
Yes, it can be done with PIVOT. You'll need to create an artificial column to aggregate on. AND you should investigate cross tabs.
Drew
J. Drew Allen
Business Intelligence Analyst
Philadelphia, PA -
@Drew.Allen - is there a reason you need an artificial column to aggregate on? Couldn't you use a COUNT on the ID, assuming there are no duplicate rows and if there are duplicate rows, couldn't you DISTINCT the results first and then COUNT on the ID?
The above is all just my opinion on what you should do.
As with all advice you find on a random internet forum - you shouldn't blindly follow it. Always test on a test server to see if there is negative side effects before making changes to live!
I recommend you NEVER run "random code" you found online on any system you care about UNLESS you understand and can verify the code OR you don't care if the code trashes your system. -
I think it's more likely that he's misstating what he wants, because he doesn't have enough knowledge, rather accurately stating that the solution should not use an aggregate. Assuming that aggregates are allowed produces a MUCH simpler and more efficient query.
SELECT ID
, MAX(CASE WHEN Activity = 'Swimming')
THEN 1
ELSE 0
END) AS Swimming
...
FROM <table>
GROUP BY IDEven in the unlikely event that he doesn't want an aggregate, it's probably going to be more efficient to use windowed functions rather than subqueries.
SELECT ID
, MAX(CASE WHEN Activity = 'Swimming')
THEN 1
ELSE 0
END) OVER(PARTITION BY ID) AS Swimming
...
FROM <table>Drew
J. Drew Allen
Business Intelligence Analyst
Philadelphia, PA - Mr. Brian Gale wrote:
@Drew.Allen - is there a reason you need an artificial column to aggregate on? Couldn't you use a COUNT on the ID, assuming there are no duplicate rows and if there are duplicate rows, couldn't you DISTINCT the results first and then COUNT on the ID?
The definition for PIVOT includes the following
<aggregation function>(<column being aggregated>)
Note that it says COLUMN being aggregated. It does not say EXPRESSION being aggregated. Part of reason for using a cross tab rather than a pivot, is that you have much more flexibility in the syntax.
Drew
J. Drew Allen
Business Intelligence Analyst
Philadelphia, PA -
Thanks for the feedback everyone, you were correct about the expected results, there should be a 1 for both swimming and gymnastics for id 1. I'll explore these suggestions and get back to you. At the end of the day, I want a list of distinct id's in Column 1 and a column for every activity with a 0 or 1 value based on whether a row with that activity exists for that ID.
-
Here's an example with an artificial column. I did try COUNT(ID), but it said invalid column.
DROP TABLE IF EXISTS dbo.Activities;
CREATE TABLE dbo.Activities
( ID INT,
Activity VARCHAR(100),
);
INSERT dbo.Activities (ID, Activity)
VALUES (1,'Swimming'), (2,'Skating'),(1, 'Gymnastics'), (3, 'Swimming');
WITH Act AS
( SELECT ID, Activity,
CAST(1 AS INT) AS CountFlag
FROM dbo.Activities
)
SELECT ID, ISNULL([Swimming],0) AS 'Swimming', ISNULL([Skating],0) AS 'Skating', ISNULL([Gymnastics],0) AS 'Gymnastics'
FROM
(
SELECT ID, Activity , CountFlag
FROM Act
) AS x
PIVOT
(
MAX(CountFlag)
FOR Activity IN ([Swimming], [Skating], [Gymnastics])
) AS x; -
duplicate
-
why doesn't pivot work for you?
2 ways of doing it with pivot below
drop table if exists #data
select *
into #data
from (values (1, 'Swimming')
, (2, 'Skating')
, (1, 'Gymnastics')
, (3, 'Swimming')
) t(ID, Activity)
select piv.ID
, coalesce(piv.Swimming, 0) as Swimming
, coalesce(piv.Skating, 0) as Skating
, coalesce(piv.Gymnastics, 0) as Gymnastics
from (select *
from #data
cross apply (select 1 as Cnt) t2
) t
PIVOT (max(t.Cnt) for activity IN ([Swimming], [Skating], [Gymnastics])
) as piv
order by piv.id
/*
or if list of activities not known use dynamic sql
*/
declare @sql nvarchar(max)
declare @basesql nvarchar(max)
declare @pivselect nvarchar(max)
declare @pivcolumns nvarchar(max)
set @basesql =
'select piv.ID
--pivselect
from (select *
from #data
cross apply (select 1 as Cnt) t2
) t
PIVOT (max(t.Cnt) for activity IN
(--pivcolumns
)
) as piv
order by piv.id
'
select @pivcolumns = STRING_AGG(quotename(t.activity), ',')
, @pivselect = STRING_AGG(', coalesce(piv.' + quotename(t.activity) + ', 0) as ' + QUOTENAME(t.activity), '')
within GROUP (ORDER by t.activity)
from (select distinct activity
from #data
) t
select @pivcolumns, @pivselect
set @sql = replace(replace(@basesql, '--pivselect', @pivselect), '--pivcolumns', @pivcolumns)
exec sys.sp_executesql @sql -
Just a suggestion... Keep It Super Simple and flexible at the same time.
Here's the test table (not part of the solution):
DROP TABLE IF EXISTS #TestTable;
GO
SELECT *
INTO #TestTable
FROM (VALUES
(1,'Swimming')
,(2,'Skating')
,(1,'Gymnastics')
,(3,'Swimming')
)v(ID, Activity)
;This is a simple CROSSTAB. It allows for simple totals for rows and columns without a lot of additional fanfare. It's usually faster than PIVOT and also lends itself very well to dynamic SQL (not shown here):
--===== Simple CROSSTABLE method includes row and column totals.
SELECT ID = IIF(GROUPING_ID(ID)=0,CONVERT(VARCHAR(10),ID),'Total')
,Swimming = SUM(IIF(Activity='Swimming' ,1,0))
,Skating = SUM(IIF(Activity='Skating' ,1,0))
,Gymnastics = SUM(IIF(Activity='Gymnastics' ,1,0))
,Total = COUNT(*) --This does the row totals
FROM #TestTable
GROUP BY ID WITH ROLLUP --This does the column totals
ORDER BY GROUPING_ID(ID), ID
;And here are the results... Notice in the code above that we didn't need even 1 ISNULL() or COALESCE() to get the missing zeros to display:

Here are some references on this old "Black Arts" method of pivoting:
This is how it works and a few reasons why it's better than Pivot... (Note... really old article used CASE instead of IIF)
https://www.sqlservercentral.com/contributions
This is how to create the code dynamically:
https://www.sqlservercentral.com/articles/cross-tabs-and-pivots-part-2-dynamic-cross-tabs
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally)
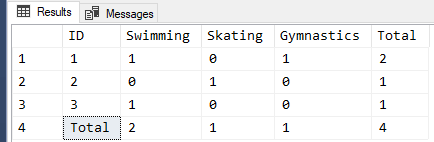
Viewing 11 posts - 1 through 11 (of 11 total)
You must be logged in to reply to this topic. Login to reply