Pivot account date list to account start and end dates with missing dates
-
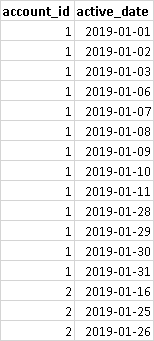
I have this requirement to convert a list of account active dates to summarize the active start and end dates for each sequence of dates. For example, this is the list of active dates for two accounts.

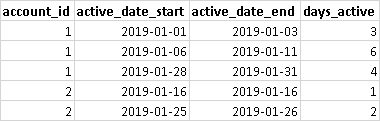
And this is the required result set.
However, it's been a puzzle on how to actually do this. Has anyone done this before?
Here's some code with sample data.
If Object_Id('dbo.account_active') Is Not Null
Drop Table dbo.account_active;
Create Table dbo.account_active(
account_active_id int Identity(1,1),
account_id int,
active_date date);
Insert Into dbo.account_active(
account_id,
active_date)
Values
(1,'2019-01-01'),
(1,'2019-01-02'),
(1,'2019-01-03'),
(1,'2019-01-06'),
(1,'2019-01-07'),
(1,'2019-01-08'),
(1,'2019-01-09'),
(1,'2019-01-10'),
(1,'2019-01-11'),
(1,'2019-01-28'),
(1,'2019-01-29'),
(1,'2019-01-30'),
(1,'2019-01-31'),
(2,'2019-01-16'),
(2,'2019-01-25'),
(2,'2019-01-26');
Select
aa.account_id,
aa.active_date
From
dbo.account_active As aa;Thank you!
-
The following code is based on a solution previously provided by Drew Allen
https://www.sqlservercentral.com/Forums/FindPost2025579.aspx
WITH cteStart AS (
SELECT aa.account_id, aa.active_date
, aa.account_active_id
, is_start = CASE WHEN aa.active_date > DATEADD(dd, 1, LAG( aa.active_date ) OVER (PARTITION BY aa.account_id ORDER BY aa.active_date)) THEN 1 ELSE 0 END
FROM dbo.account_active AS aa
)
, cteGroup AS (
SELECT *, grp = SUM( s.is_start ) OVER ( PARTITION BY s.account_id ORDER BY s.active_date ROWS UNBOUNDED PRECEDING )
FROM cteStart AS s
)
SELECT g.account_id
, active_date_start = MIN( g.active_date )
, active_date_end = MAX( g.active_date )
, days_active = DATEDIFF(dd, MIN( g.active_date ), MAX( g.active_date )) +1
FROM cteGroup AS g
GROUP BY g.account_id, g.grp
ORDER BY g.account_id, MIN( g.active_date ); -
That does work, however, I didn't mention that there is an older environment where this needs to run and LAG is not available.
I did get a pre-LAG solution that works. Thanks to Jingyang Li over at the MSDN SQL Server forum.
With mycte
As (Select
*,
Dateadd(DAY,-Row_Number() Over(Partition By account_id
Order By
active_date),active_date) As grp
From
account_active)
Select
account_id,
Min(active_date) As active_date_start,
Max(active_date) As active_date_end,
Count(*) As days_active
From
mycte
Group By
account_id,
grp
Order By
account_id,
Min(active_date); -
Thanks for posting the alternate solution, which seems to have a better execution plan than the one that I posted.
-
After some larger data set testing I found the solution above does not work for all data sets. Mainly those with duplicate active_dates for an account_id. I also got several other solutions (4 in total) and only 1 of the 4 handles data sets having duplicate account_id and active_dates.
I worked through the code by creating a data set of 5,000,000 rows of randomly generated data.
This code creates a large data set that is variable controlled. The date range of the data can start at 2019-03-01 to the current date. account_ids can range from 1 to 10,000.
-- Variables used to create test data.
Declare
-- The maximum id to generate for accounts.
@account_id_max int = 10000,
-- Number of rows of randomly generated data.
@rows_to_create int = 5000000,
-- The earliest date to use for active date.
@date_earliest date = '2019-03-01',
@day_add_current int;
-- Calculate the number of days between the earliest date and now.
Set @day_add_current = Datediff(DAY,@date_earliest,Getdate());
If Object_Id('dbo.account_active') Is Not Null
Drop Table dbo.account_active;
-- Table to store randomly generated data.
Create Table dbo.account_active(
account_active_id int Identity(1,1),
account_id int,
active_date date);
-- Original data for testing.
Insert Into dbo.account_active(
account_id,
active_date)
Values
(1,'2019-01-01'),
(1,'2019-01-02'),
(1,'2019-01-03'),
(1,'2019-01-06'),
(1,'2019-01-07'),
(1,'2019-01-08'),
(1,'2019-01-09'),
(1,'2019-01-10'),
(1,'2019-01-11'),
(1,'2019-01-28'),
(1,'2019-01-29'),
(1,'2019-01-30'),
(1,'2019-01-31'),
(2,'2019-01-16'),
(2,'2019-01-25'),
(2,'2019-01-26');
-- Randomly generated data.
With random_data
As (Select
1 As row_id
Union All
Select
1 + row_id
From
random_data
Where row_id < @rows_to_create)
Insert Into dbo.account_active(
account_id,
active_date)
Select
Abs(Cast(Newid() As binary(6)) % @account_id_max) + 1 As account_id,
Dateadd(DAY,Abs(Cast(Newid() As binary(6)) % @day_add_current),@date_earliest) As active_date
From
random_data Option(
MaxRecursion 0);
Create NonClustered Index IX_account_active_active_date On dbo.account_active(active_date)
Include(account_id);
Create NonClustered Index IX_account_active_id On dbo.account_active(account_active_id)
Include(account_id,active_date);
Update Statistics account_active;This code uses the data set to show the differences between the original solutions provided and modified ones that address the original requirements. I also document for each solution which versions of SQL Server they will work.
Dbcc DropCleanBuffers;
-- Report date range.
Declare
@date_start date = '2019-05-01',
@date_end date = '2019-05-31';
--Solution 1 (2012 and later) original doesn't account for duplicate active_dates.
With mycte
As (Select
account_id,
active_date,
Case
When Datediff(day,Lag(active_date) Over(Partition By account_id
Order By
active_date),active_date) <= 1 Then 0
Else 1
End As flag
From
dbo.account_active
Where
active_date >= @date_start And
active_date <= @date_end),
mycte1
As (Select
account_id,
active_date,
flag,
Sum(flag) Over(Partition By account_id
Order By
active_date) As grp
From
mycte)
Select
account_id,
Min(active_date) As active_date_start,
Max(active_date) As active_date_end,
Count(*) As days_active
From
mycte1
Group By
account_id,
grp
Order By
account_id,
Min(active_date);
--Solution 1 (2012 and later) accounting for duplicate active dates.
With mycte
As (Select
account_id,
active_date,
Case
When Datediff(day,Lag(active_date) Over(Partition By account_id
Order By
active_date),active_date) <= 1 Then 0
Else 1
End As flag
From
dbo.account_active
Where
active_date >= @date_start And
active_date <= @date_end),
mycte1
As (Select
account_id,
active_date,
flag,
Sum(flag) Over(Partition By account_id
Order By
active_date) As grp
From
mycte)
Select
account_id,
Min(active_date) As active_date_start,
Max(active_date) As active_date_end,
--Count(*) As days_active <- original
DATEDIFF(day,Min(active_date),Max(active_date)) + 1 As days_active
From
mycte1
Group By
account_id,
grp
Order By
account_id,
Min(active_date);
--solution 2 (pre-2012) original doesn't account for duplicate active dates.
With mycte
As (Select
account_active.account_id,
account_active.active_date,
Dateadd(DAY,-Row_Number() Over(Partition By account_id
Order By
active_date),active_date) As grp
From
account_active
Where
active_date >= @date_start And
active_date <= @date_end)
Select
account_id,
Min(active_date) As active_date_start,
Max(active_date) As active_date_end,
Count(*) As days_active
From
mycte
Group By
account_id,
grp
Order By
account_id,
Min(active_date);
--solution 2 (pre-2012) accounts for duplicate active dates.
With dedupe
As (Select
aa.account_active_id
From
account_active As aa_delete
Join
(Select
account_active_id,
account_id,
active_date,
Row_Number() Over(Partition By account_id,
active_date
Order By
account_active_id) As rownumber
From
account_active
Where
active_date >= @date_start And
active_date <= @date_end) As aa On aa.account_active_id = aa_delete.account_active_id
Where aa.rownumber = 1),
mycte
As (Select
aa.account_id,
aa.active_date,
Dateadd(DAY,-Row_Number() Over(Partition By aa.account_id
Order By
aa.active_date),aa.active_date) As grp
From
dedupe As d
Join account_active As aa On aa.account_active_id = d.account_active_id)
Select
account_id,
Min(active_date) As active_date_start,
Max(active_date) As active_date_end,
Count(*) As days_active
From
mycte
Group By
account_id,
grp
Order By
account_id,
Min(active_date);
-- Solution 3 (pre-2012) doesn't account for duplicate active_dates.
Select
Account_ID,
active_date_Start = Min(active_date),
active_date_End = Max(active_date),
Days_Active = Datediff(DAY,Min(active_date),Max(active_date)) + 1
From
(Select
s.account_id,
s.active_date,
Grp = Datediff(DAY,'1900-01-01',active_date) - Row_Number() Over(Partition By Account_id
Order By
active_date)
From
account_active As s
Where
s.active_date >= @date_start And
s.active_date <= @date_end) As A
Group By
Account_id,
Grp
Order By
Account_id,
Min(active_date);
-- Solution 3 (pre-2012) accounts for duplicate active_dates.
Select
Account_ID,
active_date_Start = Min(active_date),
active_date_End = Max(active_date),
Days_Active = Datediff(DAY,Min(active_date),Max(active_date)) + 1
From
(Select
s.account_id,
s.active_date,
Grp = Datediff(DAY,'1900-01-01',active_date) - Dense_Rank() Over(Partition By Account_id
Order By
active_date)
From
account_active As s
Where
s.active_date >= @date_start And
s.active_date <= @date_end) As A
Group By
Account_id,
Grp
Order By
Account_id,
Min(active_date);
-- Solution 4 (2012 and later) already accounted for duplicate active_dates.
With cteStart
As (Select
aa.account_id,
aa.active_date,
is_start = Case
When aa.active_date > Dateadd(dd,1,Lag(aa.active_date) Over(Partition By aa.account_id
Order By
aa.active_date)) Then 1
Else 0
End
From
dbo.account_active As aa
Where
aa.active_date >= @date_start And
aa.active_date <= @date_end),
cteGroup
As (Select
s.account_id,
s.active_date,
grp = Sum(s.is_start) Over(Partition By s.account_id
Order By
s.active_date Rows UNBOUNDED Preceding)
From
cteStart As s)
Select
g.account_id,
active_date_start = Min(g.active_date),
active_date_end = Max(g.active_date),
days_active = Datediff(dd,Min(g.active_date),Max(g.active_date)) + 1
From
cteGroup As g
Group By
g.account_id,
g.grp
Order By
g.account_id,
Min(g.active_date); -
Firstly, your random data generator - Using a recursive CTE to create a list of numbers is very inefficient. Below is a more performant script to create your sample data. (Thanks to Jeff Moden)
--Your code -- Takes 1 min 15 seconds on my machine
WITH random_data AS (
SELECT row_id = 1
UNION ALL
SELECT 1 + random_data.row_id
FROM random_data
WHERE random_data.row_id < @rows_to_create
)
INSERT INTO dbo.account_active ( account_id, active_date )
SELECT account_id = ABS( CAST(NEWID() AS binary(6)) % @account_id_max ) + 1
, active_date = DATEADD( DAY, ABS( CAST(NEWID() AS binary(6)) % @day_add_current ), @date_earliest )
FROM random_data
OPTION ( MAXRECURSION 0 );
--Improved code -- Taks 9 seconds on my machine
WITH T(N) AS (SELECT N FROM (VALUES (0),(0),(0),(0),(0),(0),(0),(0),(0),(0)) AS X(N))
, random_data(row_id) AS (SELECT TOP(@rows_to_create) ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) AS N FROM T T1,T T2,T T3,T T4,T T5,T T6,T T7,T T8,T T9)
INSERT INTO dbo.account_active ( account_id, active_date )
SELECT account_id = ABS( CAST(NEWID() AS binary(6)) % @account_id_max ) + 1
, active_date = DATEADD( DAY, ABS( CAST(NEWID() AS binary(6)) % @day_add_current ), @date_earliest )
FROM random_data
OPTION ( MAXRECURSION 0 );The query that you got from Jingyang Li over at the MSDN SQL Server forum, can be easily modified to get the correct result by simply adding a GROUP BY to the CTE
WITH mycte AS (
SELECT aa.account_id,
aa.active_date,
grp = DATEADD( DAY, -ROW_NUMBER() OVER ( PARTITION BY aa.account_id ORDER BY aa.active_date ), aa.active_date )
FROM account_active AS aa
WHERE aa.active_date >= @date_start
AND aa.active_date <= @date_end
GROUP BY aa.account_id, aa.active_date -- Added to take care of Duplicates
)
SELECT cte.account_id
, active_date_start = MIN( cte.active_date )
, active_date_end = MAX( cte.active_date )
, days_active = COUNT( * )
FROM mycte AS cte
GROUP BY cte.account_id, cte.grp
ORDER BY cte.account_id, cte.grp; -
I wasn't as concerned with the random data generation as I was with the queries for the actual data. Thank you though as it is much better. I tried it to create 50,000,000 rows and it did quite well. Adding GROUP BY worked as well.
Thank you!
-
For those who may be lurking on this thread and possibly not understanding how the code on this thread works, especially with the most recent corrections submitted by DesNorton above, please see the following article.
https://www.sqlservercentral.com/articles/group-islands-of-contiguous-dates-sql-spackle
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - DesNorton wrote:
The query that you got from Jingyang Li over at the MSDN SQL Server forum, can be easily modified to get the correct result by simply adding a GROUP BY to the CTE
WITH mycte AS (
SELECT aa.account_id,
aa.active_date,
grp = DATEADD( DAY, -ROW_NUMBER() OVER ( PARTITION BY aa.account_id ORDER BY aa.active_date ), aa.active_date )
FROM account_active AS aa
WHERE aa.active_date >= @date_start
AND aa.active_date <= @date_end
GROUP BY aa.account_id, aa.active_date -- Added to take care of Duplicates
)
SELECT cte.account_id
, active_date_start = MIN( cte.active_date )
, active_date_end = MAX( cte.active_date )
, days_active = COUNT( * )
FROM mycte AS cte
GROUP BY cte.account_id, cte.grp
ORDER BY cte.account_id, cte.grp;Instead of adding a GROUP BY in the CTE, I would change the ROW_NUMBER() to a DENSE_RANK(). I haven't had a chance to test.
Drew
J. Drew Allen
Business Intelligence Analyst
Philadelphia, PA - drew.allen wrote:DesNorton wrote:
The query that you got from Jingyang Li over at the MSDN SQL Server forum, can be easily modified to get the correct result by simply adding a GROUP BY to the CTE
WITH mycte AS (
SELECT aa.account_id,
aa.active_date,
grp = DATEADD( DAY, -ROW_NUMBER() OVER ( PARTITION BY aa.account_id ORDER BY aa.active_date ), aa.active_date )
FROM account_active AS aa
WHERE aa.active_date >= @date_start
AND aa.active_date <= @date_end
GROUP BY aa.account_id, aa.active_date -- Added to take care of Duplicates
)
SELECT cte.account_id
, active_date_start = MIN( cte.active_date )
, active_date_end = MAX( cte.active_date )
, days_active = COUNT( * )
FROM mycte AS cte
GROUP BY cte.account_id, cte.grp
ORDER BY cte.account_id, cte.grp;Instead of adding a GROUP BY in the CTE, I would change the ROW_NUMBER() to a DENSE_RANK(). I haven't had a chance to test. Drew
If you use the DENSE_RANK, then you also need to replace the COUNT(*) with DATEDIFF(dd, MIN( cte.active_date ), MAX( cte.active_date )) +1.
However, on my environment, the COUNT(*) appears to have a better perf - See the attached sqlplan file
Viewing 10 posts - 1 through 10 (of 10 total)
You must be logged in to reply to this topic. Login to reply