Performance improves after reboot
- RVO - Friday, February 10, 2017 7:56 PM
Because they are no longer exactly the same size. This can get you uneven usage patterns.
Best,
Kevin G. Boles
SQL Server Consultant
SQL MVP 2007-2012
TheSQLGuru on googles mail service - RVO - Wednesday, February 8, 2017 4:24 PM
Problems like this are a real bugger to find. Of course, you already know that. 😉
I agree with the idea that there may be something to do with the size of TempDB. 32GB per file for 8 files seems like an awful lot of TempDB even for a 3TB box and especially since only 128GB of memory has been allocated. Something is using way too many TempDB resources and I'd try to find out what that is. I'd also do as Kevin suggested and ensure that trace flags 1117 and 1118 were activated during the boot up sequence of SQL Server. To provide a perspective, we have a 2TB server that is both heavily OLTP and Batch (think tons of bi-directional ETL) and none of our 8 two GB TempDB files has ever grown over the past 3 years. Of course, you'll need to find out the code that's running during any TempDb growth after a reboot to aid you in finding the cause. As a bit of a sidebar, a quick "patch" might be to get them to bring the server up to 256GB of ram. It's a quick "patch" and well worth the try
If it's not that, then the "joy" of discovery begins. Again, I'm no expert here because it's only happened to me twice (turned out to be connection leaks and it was a very long time ago) and so folks like Kevin Boles will have a better solution/quicker solution (especially if you can get him on-site for a couple of days... it would seriously be worth it and for more than just this one problem) than I, but here's what my approach has been in the past.
I don't know for sure but this sounds typical of a system that is experiencing either a ton of one-off items in the plan-cache, some really bad parameter sniffing (especially if the daily ETL is inbound), memory leaks, connection leaks, or some combination. For troubleshooting, the first thing I'd do when it seems bad enough to warrant a reboot is to fire up a good perfmon chart and get a half hour sample of disk reads, disk writes, CPU, etc. Then, I'd run DBCC FREEPROCCACHE and see what happens over the next half hour. If that fixes it, then I'd make sure that the Optimize for Ad Hoc Queries option were turned on, re-execute the DBCC FREEPROCCACHE command, and watch it again. If that fixes it, then you might have your answer; it may have been a lot of one-off items in the plan-cache. If it doesn't fix it, then it may be some really bad parameter sniffing (you'll need to start checking what code is doing) or it may be a memory or connection leak, which would really be a pain.
For possible connection leaks, do a reboot and, after 24 hours have passed, start counting and recording the number of connections on the box at the same time every day. I don't need to explain much here. If you have a connection leak, it'll become obvious especially when you compare the last 24 hour measurement prior to you doing a reboot to the first 24 hour measurement.
Memory leaks are a bit more difficult to figure out but the use of Resource Monitor would give you a clue as to if they were a problem.
Both Connection Leaks and Memory Leaks are really difficult to find the source of, especially if they're due to something the front end is doing but they could also be caused by things like people not closing global cursors or maybe something like the old problem of sp_OA* procs being used (it's supposedly been fixed but who knows).
And finally, it may have nothing to do with the SQL Server at all. It may be the Web Servers. You have to check them for effect when you reboot the SQL Server because it may (I'm no expert here... just basing this on what others have found where I work) have something to do with a cache reset or implicit connection leak repair when all of the connections are broken by rebooting the SQL Server.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Thanks for the props Jeff!!
You bring up a good point though which is what patch level is the OP on. There are indeed memory leaks that have been patched up over the years ( as well as other important fixes of other types that could possibly cause cumulative performance degradation).
Best,
Kevin G. Boles
SQL Server Consultant
SQL MVP 2007-2012
TheSQLGuru on googles mail service -
Hi,
I don't want to add any petrol to the fire, so I'll try and be brief.
Start with the simplest thing I once did - the Windows Eventviewer, this can give clues, as the operating system needs some space as well, although someone already mentioned that reducing memory allocated to the SQL instance is one thing to look at. In Windows you also set up monitors to run periodically. Run "perfmon" and setup some SQL monitors. Create a baseline after the reboot. Sorry, it's gonna take you at least 2 weeks maybe more to locate the problem. This is a DBA full time task.
- JasonClark - Wednesday, February 8, 2017 10:11 PM
An excellent article indeed, just what I was looking for for the past 12 months 😎
-
Jeff, as usually your response is the most thorough, detailed, to the point.
Thanks a lot.
Just a few questions."....it may have been a lot of one-off items in the plan-cache.."Can you please explain? What does it mean?
"...start counting and recording the number of connections on the box at the same time every day..."Do you mean number of sessions in sp_whoisactive ?
-
Dear,
Kevin G. Boles,We are located in Toronto Canada.
What is the best way to contact you? -
I read this article by Kimberly L. Tripp.
Very interesting stuff about wasting Cache, Ad Hoc Queries optimization,
bad plans:http://www.sqlskills.com/blogs/kimberly/plan-cache-and-optimizing-for-adhoc-workloads/
- RVO - Monday, February 13, 2017 8:09 PM
Thank you for the nice feedback but I could also be wrong all the way around. There are a ton of possibilities based on the symptoms of your box. I'm just suggesting a couple of things that helped me in the past. :blush:
Just a few questions.
"....it may have been a lot of one-off items in the plan-cache.."
Can you please explain? What does it mean?As you know, when code executes, it's saved in cache so that if it needs to execute again but with only slightly different parameters, SQL Server can reuse the execution plan instead of going through the expensive process of compiling a new one. For a lot of smaller queries, the parameters are substantially different and so execution plan reuse might not be possible but the execution plan is still cached. That takes memory and it also takes a bit of time for SQL Server to sift through them all. There can be tens of thousands over time since the last reboot.
One way to keep these "ad hoc" single plans from stacking up in cache is to turn on the "Optimize for Ad Hoc Workloads" server-wide setting. I don't know the magic of it all but it keeps a plan from being entirely cached unless it's used a second time. Using DBCC FREEPROCCACHE also clears those little buggers out and is a fairly inexpensive test compared to a reboot."...start counting and recording the number of connections on the box at the same time every day..."
Do you mean number of sessions in sp_whoisactive ?Sure but you might not need something that sophisticated. Just running sp_who or sp_who2 will be good enough. On most systems, the number of connections stabilizes after 24 hours or so. On systems with connection leaks, they continue to grow every day. Each connection is also allocated memory. Another name for a connection leak is a connection that was never properly closed. Connection pooling, if you have it running, allows for reuse of connections without closing them because opening and closing connections is time consuming. But, if the number of connections continues to grow for more than a day or two, something isn't closing or reusing connections. Of course, rebooting fixes all of that.
Also, if you have index maintenance routines that run on a regular basis, they could be pushing plans out of cache during index rebuilds, which inherently rebuilds stats and that will cause recompiles of plans for cache. Since you also have ETL batches running on your box, that could cause some "bad" parameter sniffing. I occasionally have that problem even though I don't rebuild indexes anymore. The massive ETL jobs just have their way with memory. The thing that hints at that to me is the size of your TempDB files. Before your next reboot, try DBCC FREEPROCCACHE on your system, as I previously suggested. Undoubtedly, a lot of people will tell you to never do that but 1) it's a whole lot cheaper than rebooting the machine especially since no one will be knocked off by a reboot and 2) it has worked wonders for me until we can make all of our code a bit more bullet proof (and we have tons of legacy code that isn't... we could fix a lot of it fairly quickly but time to do regression testing is a killer for our busy schedule).
Still all of that is just hints and I could be totally wrong because I can't put my hands on your server. Getting Kevin in there (even if it were by RDP connection) for a couple of days would be my best recommendation.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Jeff,
Is Kevin G. Boles specialty - performance issues?
What is the best way to contact Kevin?Couple of questions.
Correct me if I'm wrong.
---------------------------------------------------------------------------------------------------------------------------------------------------------
For the same query, SQL Server stores multiple plans in cache for different parameters.
If let's say for query A you had 5 good plans (1,2,3,4,5)
and then somebody runs same query with weird rare parameters which creates another cached plan A6
and this plan is very bad. So the impact is that from now on plan A6 might be reused by SQL Server
and it will cause performance degradation.
--------------------------------------------------------------------------------------------------------------------------------------------------------Other questions.
For a lot of smaller queries, the parameters are substantially different and so execution plan reuse might not be possible but the execution plan is still cached.
"substantially different" from what?I use this query to view current cache below.
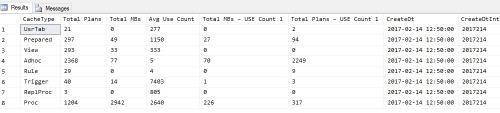
SELECT
objtype AS [CacheType],
COUNT_BIG(*) AS [Total Plans],
SUM(CAST(size_in_bytes AS DECIMAL(18, 2))) / 1024 / 1024 AS [Total MBs],
AVG(usecounts) AS [Avg Use Count],
SUM(CAST((CASE WHEN usecounts = 1 THEN size_in_bytes
ELSE 0
END) AS DECIMAL(18, 2))) / 1024 / 1024 AS [Total MBs – USE Count 1],
SUM(CASE WHEN usecounts = 1 THEN 1
ELSE 0
END) AS [Total Plans – USE Count 1]
FROM sys.dm_exec_cached_plans
GROUP BY objtype
ORDER BY [Total MBs – USE Count 1] DESC
GOResults are attached

What does it tell you?
Do we need Ad Hoc Optimized?We don't do scheduled Index Rebuild.
We only manually do UPDATE STATISTICS full scan every 2-3 weeks. -
Jeff,
About Connection leak.
-------------------------------------
sp_who2 returns 360 rows.
90% of them are sleeping,
5% are BACKGROUND or SUSPENDED.
Do I need to count all of them? -
The number you're looking for is the 360 that was returned.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Perry White,
Can you please explain your comment below?
What does it mean "when buffer pool recharges"?Disk usage will increase as the buffer pool recharges. -
Jonnathan,
Why ETL would get faster if I shrink TEMPDB files?
- RVO - Tuesday, February 14, 2017 4:02 PM
Nothing happens in SQL Server with stuff that isn't in RAM first. Thus if anything flushes part or most of the stuff that is currently in RAM out so new stuff can come in to be processed then some or even most of that stuff that was flushed out will need to come back into memory so it can be processed. Often those pages are for "hot", active data and they cause other applications that need them to bog down waiting for IO from disk. Remember, memory is MICROSECOND timescale. Rotating disks are often tens to hundreds of milliseconds and even SSDs are a few milliseconds. That is 3-5 ORDERS OF MAGNITUDE slower.
Best,
Kevin G. Boles
SQL Server Consultant
SQL MVP 2007-2012
TheSQLGuru on googles mail service
Viewing 15 posts - 16 through 30 (of 114 total)
You must be logged in to reply to this topic. Login to reply