parsing records with empty spaces
- Jeff Moden - Friday, January 20, 2017 8:46 AM
Thanks , main problem with output format from Unix scrpt
I can 't use mycomnd | sed -r 's/\s+/,/g' |sed -r 's/,$//g' ( usage of | is restricted inside PowerShell script calling Unix script)
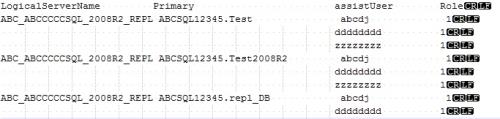
Bellow is image of output from command when I place it notepad++ in order to see delimiters
I could not figure out how to load data with this format using bulk insert

- ebooklub - Friday, January 20, 2017 9:17 AM
That looks different than what you said when I used bullets to replace the spaces to see. Is there any chance you could attach the file you've depicted above?
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden - Friday, January 20, 2017 10:32 AM
I modified values in file ,but kept same number of characters and position for each entry
-
So you did NOT add any spaces to try to line things up? I ask because the alignment of the right most column has flaws in it. I have to make sure of the format in order to make this easy for both of us. 😉 Is there any way that you could email an actual, untouched file to me with the understanding that I will not expose the content to anyone or anything else and will destroy the file as soon as I've solved your problem?
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden - Friday, January 20, 2017 11:17 AM
Hi Jeff,
1.no spaces added, file has original alignment.
2.I can't send original file (comp. policy)
3.Since we trying to create script that will be called 500 times (once for each server) ) daily I can't rely on exact alignment of the column,
output will always produce 4 columns, column1 and column2 might or might not contain values but "delimiter" will be same all the time
Thank you - ebooklub - Friday, January 20, 2017 11:40 AM
Got it... and figured so on #2 but had to ask. So there aren't just 2 leading spaces on these things... it's more like printed output than delimited output. That's a pretty simple substring job with the understanding that the starting position of each column can change but can also be easily derived from the first line in the file.
I'll be back.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Ok... Sorry this took so long but I was unexpectedly busy this weekend. I also apologize for the cruddy non-indented, non-aligned code this forum now spews out. Plain code with a paste from Word used to work when I changed all spaces to non-breaking spaces. They've apparently changed that. The code windows they use now does double spacing, which really makes the code difficult to follow and has some real flaws for color coding.
First, I assumed that the files looked like what you posted most recently. As a refresher, that file looks like the following. Note that I've replaced all spaces with asterisks just for the sake of visibility.
LogicalServerName*********Primary************************assistUser********Role
MTL_TESTOADSQL_2008R2_REPL*MTLSQL12001.Test***************user1*************1
*********************************************************user0002**********1
*********************************************************user0003**********1
*********************************************************user0004**********1
*********************************************************user0005**********1
*********************************************************user0006**********1
*********************************************************user0007**********1
MTL_TESTOADSQL_2008R2_REPL*MTLSQL12001.Test2008R2*********user1*************1
*********************************************************user0002**********1
*********************************************************user0003**********1
*********************************************************user0004**********1
*********************************************************user0005**********1
*********************************************************user0006**********1
*********************************************************user0007**********1
MTL_TESTOADSQL_2008R2_REPL*MTLSQL12001.repl_DB************user1*************1
*********************************************************user0002**********1
*********************************************************user0003**********1
*********************************************************user0004**********1
*********************************************************user0005**********1
*********************************************************user0006**********1
*********************************************************user0007**********1[/code]
Since this is akin to a screen scraping job, I also made the assumption that, except for the first column, the other columns could vary in length depending on the contents of the file. I find the start of each column based on the positions of the column header labels in the first line of the file.
Since you said it would always be 4 columns, I took the liberty of hard coding the column names in the final result table.
The following code DOES have two dependencies. If you don't have these two items, consider adding them as part of your standard installation because both are invaluable to some pretty cool coding methods in T-SQL.
The first item is a generic "whole line" BCP format file. Don't let the name throw you. The format files are also used by BULK INSERT. Here's what it looks like. Store it somewhere where you server can see it (preferably, on the server itself).
8.0
2
1 SQLCHAR 0 0 "" 0 RowNum(NotUsed) ""
2 SQLCHAR 0 8000 "\r\n" 2 WholeRow ""[/code]
Next, you need a "Tally Function". Here's a copy of the code I use for my production systems. It's pretty well documented in the comments so I won't take the time to explain except that if you've never seen that a "Tally Table" or "Tally Function" can do for you to replace loops and other forms of RBAR, then read the first link provided in the comments.
CREATE FUNCTION [dbo].[fnTally]
/**********************************************************************************************************************
Purpose:
Return a column of BIGINTs from @ZeroOrOne up to and including @MaxN with a max value of 1 Trillion.As a performance note, it takes about 00:02:10 (hh:mm:ss) to generate 1 Billion numbers to a throw-away variable.
Usage:
--===== Syntax example (Returns BIGINT)
SELECT t.N
FROM dbo.fnTally(@ZeroOrOne,@MaxN) t
;Notes:
1. Based on Itzik Ben-Gan's cascading CTE (cCTE) method for creating a "readless" Tally Table source of BIGINTs.
Refer to the following URLs for how it works and introduction for how it replaces certain loops.
http://www.sqlservercentral.com/articles/T-SQL/62867/
http://sqlmag.com/sql-server/virtual-auxiliary-table-numbers
2. To start a sequence at 0, @ZeroOrOne must be 0 or NULL. Any other value that's convertable to the BIT data-type
will cause the sequence to start at 1.
3. If @ZeroOrOne = 1 and @MaxN = 0, no rows will be returned.
5. If @MaxN is negative or NULL, a "TOP" error will be returned.
6. @MaxN must be a positive number from >= the value of @ZeroOrOne up to and including 1 Billion. If a larger
number is used, the function will silently truncate after 1 Billion. If you actually need a sequence with
that many values, you should consider using a different tool. 😉
7. There will be a substantial reduction in performance if "N" is sorted in descending order. If a descending
sort is required, use code similar to the following. Performance will decrease by about 27% but it's still
very fast especially compared with just doing a simple descending sort on "N", which is about 20 times slower.
If @ZeroOrOne is a 0, in this case, remove the "+1" from the code.DECLARE @MaxN BIGINT;
SELECT @MaxN = 1000;
SELECT DescendingN = @MaxN-N+1
FROM dbo.fnTally(1,@MaxN);8. There is no performance penalty for sorting "N" in ascending order because the output is explicity sorted by
ROW_NUMBER() OVER (ORDER BY (SELECT NULL))Revision History:
Rev 00 - Unknown - Jeff Moden
- Initial creation with error handling for @MaxN.
Rev 01 - 09 Feb 2013 - Jeff Moden
- Modified to start at 0 or 1.
Rev 02 - 16 May 2013 - Jeff Moden
- Removed error handling for @MaxN because of exceptional cases.
Rev 03 - 22 Apr 2015 - Jeff Moden
- Modify to handle 1 Trillion rows for experimental purposes.
**********************************************************************************************************************/
(@ZeroOrOne BIT, @MaxN BIGINT)
RETURNS TABLE WITH SCHEMABINDING AS
RETURN WITH
E1(N) AS (SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1) --10E1 or 10 rows
, E4(N) AS (SELECT 1 FROM E1 a, E1 b, E1 c, E1 d) --10E4 or 10 Thousand rows
,E12(N) AS (SELECT 1 FROM E4 a, E4 b, E4 c) --10E12 or 1 Trillion rows
SELECT N = 0 WHERE ISNULL(@ZeroOrOne,0)= 0 --Conditionally start at 0.
UNION ALL
SELECT TOP(@MaxN) N = ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM E12 -- Values from 1 to @MaxN
;[/code]
And, finally, here's code to solve your problem using T-SQL. Also note that I made it compatible with all 2005+ versions of SQL Server so that you can use it on a "throwback" machine if it becomes necessary. To summarize, it reads the file as "blob" lines, determines the column positions based on the spacing of the column header labels, uses that to create Dynamic SQL that will populate a final result table, and then "smears" any missing server or "Primary" data down into rows where it's missing. Details, of course, are in the comments. And I did try to keep it from being contumacious
The only thing that you need to change in the code are the values for @pFilePath (the file to import) and the @pFmtFilePath, which is the full path to the BCP Format File from above. The code appears to be a bit long but that's only because of the flexibility that's been built in so that it should handle any similar files that you may need to bring in even though the starting position of each column may vary from file to file.
--==================================================================================================
-- These variables could be parameters for a stored procedure
--==================================================================================================
DECLARE @pFilePath VARCHAR(8000)
,@pFmtFilePath VARCHAR(8000)
;
SELECT @pFilePath = 'C:\Temp\test_loading_UnixCommandOutput_to_SQL.txt'
,@pFmtFilePath = 'C:\Temp\WholeRow.BCPFmt'
;
--==================================================================================================
-- Temp Tables
--==================================================================================================
--===== If the Temp Tables exist, drop them to make reruns in SSMS easier.
-- This section may be commented out if part of a stored procedure
IF OBJECT_ID('tempdb..#ImportStaging' ,'U') IS NOT NULL DROP TABLE #ImportStaging;
IF OBJECT_ID('tempdb..#ColumnPosition','U') IS NOT NULL DROP TABLE #ColumnPosition;
IF OBJECT_ID('tempdb..#Result' ,'U') IS NOT NULL DROP TABLE #Result;--===== Create the table that will contain the data as whole rows
CREATE TABLE #ImportStaging
(
RowNum INT IDENTITY(0,1) PRIMARY KEY CLUSTERED
,WholeRow VARCHAR(8000)
)
;
--===== Create the table that will hold the parsed results.
CREATE TABLE #Result
(
RowNum INT NOT NULL PRIMARY KEY CLUSTERED
,LogicalServerName VARCHAR(256)
,[Primary] VARCHAR(256)
,assistUser VARCHAR(256)
,[Role] INT
)
--==================================================================================================
-- Presets
--==================================================================================================
--===== Supress the auto-display of rowcounts for appearance sake.
SET NOCOUNT ON
;
--===== Common Local Variables
DECLARE @SQL VARCHAR(8000)
;
--==================================================================================================
-- Import the raw data as whole rows so that we can work on them.
-- Note that this uses a BCP format file because the file doesn't have a "RowNum" column.
--==================================================================================================
--===== Import the file as whole rows including the header,
-- which will live at RowNum = 0.
SELECT @SQL = REPLACE(REPLACE(REPLACE('
BULK INSERT #ImportStaging
FROM <<@pFilePath>>
WITH
(
BATCHSIZE = 0
,CODEPAGE = "RAW"
,DATAFILETYPE = "char"
,FORMATFILE = <<@pFmtFilePath>>
,TABLOCK
)
;'
,'"' ,'''')
,'<<@pFilePath>>' ,QUOTENAME(@pFilePath,''''))
,'<<@pFmtFilePath>>',QUOTENAME(@pFmtFilePath,''''))
;
--===== Print and then execute the Dynamic SQL.
PRINT @SQL;
EXEC ( @sql)
;
--==================================================================================================
-- Determine the "shape" of the data by finding the starting position of each column in
-- the header row.
--==================================================================================================
--===== Determine the start of each column by finding the first character of each column name.
-- Note that this assumes that there will never be spaces in any of the column names.
-- This uses a "Tally Table" function to find the start of each column by looking for characters
-- that have a space just to the left of them. Of course, we also assume the first character
-- is the beginning of the first column, as well.
WITH cteColInfo AS
(
SELECT RowNum = ROW_NUMBER() OVER (ORDER BY t.N)
,ColStart = t.N
FROM #ImportStaging stg
CROSS APPLY dbo.fnTally(1,LEN(WholeRow)) t
WHERE stg.RowNum = 0
AND (t.N = 1 OR SUBSTRING(stg.WholeRow,t.N-1,2) LIKE ' [^ ]')
)
SELECT *
,ColName = CASE
WHEN RowNum = 1 THEN 'LogicalServerName'
WHEN RowNum = 2 THEN '[Primary]'
WHEN RowNum = 3 THEN 'assistUser'
WHEN RowNum = 4 THEN 'Role'
ELSE 'ERROR'
END
INTO #ColumnPosition
FROM cteColInfo
;
--==================================================================================================
-- Build the Dynamic SQL to correctly split the input data based on the variable column
-- positions discovered above.
--==================================================================================================
--===== Reset the @SQL variable so that we can overload it to build the "Select List" that will do
-- the splitting for us.
SELECT @SQL = ''
;
--===== Create the Dynamic "Select List".
-- This uses a simple self-join on the #ColumnPosition table to calculate the lengths.
-- This could be simplified in 2012 using the new Lead/Lag functionality.
SELECT @SQL = @SQL + CHAR(10)
+ REPLACE(REPLACE(REPLACE(REPLACE(
'<<indent>>,<<ColName>> = LTRIM(RTRIM(SUBSTRING(WholeRow,<<ColStart>>,<<ColLength>>)))'
,'<<ColName>>' , CONVERT(CHAR(20),lo.ColName))
,'<<ColStart>>' , CONVERT(VARCHAR(10),lo.ColStart))
,'<<ColLength>>', CONVERT(VARCHAR(10),ISNULL(hi.ColStart-lo.ColStart,8000)))
,'<<indent>>' , SPACE(8))
FROM #ColumnPosition lo
LEFT JOIN #ColumnPosition hi ON lo.RowNum = hi.RowNum - 1
;
--===== Add the static portion of the Dynamnic SQL to the SELECT list we just created above.
SELECT @SQL = '
INSERT INTO #Result
(RowNum,LogicalServerName,[Primary],assistUser,[Role])
SELECT RowNum' + @SQL + '
FROM #ImportStaging
WHERE RowNum > 0
ORDER BY RowNum
;'
--===== Display and then execute the Dynamic SQL to populate the results table.
PRINT @SQL;
EXEC ( @sql)
;
--==================================================================================================
-- Do a "Data Smear" to populate any missing column 1 and column 2 data.
-- This uses a "Quirky Update", which works in any version of SQL Server.
-- If you're using 2012+, this could be converted to more modern and supported by MS.
--==================================================================================================
--===== Declare the "forwarding" variables for the "Quirky Update"
DECLARE @PrevLogicalServerName VARCHAR(256)
,@PrevPrimary VARCHAR(256)
,@SafetyCounter INT
;
--===== Preset the safety count to assume that there's at least one row in the #Result table.
SELECT @SafetyCounter = 1
;
--===== Do the "Quirky Update" using the proprietary "3 part update" that SQL Server has.
-- The safety counter is to ensure that if MS ever breaks updates for this method, the code
-- will fail and alert us to the problem. Replace this code with more modern "Lead/Lag" code
-- if that ever happens (this code works on all versions through 2016).
UPDATE tgt
SET @PrevLogicalServerName
= LogicalServerName
= CASE
WHEN LogicalServerName > ''
THEN LogicalServerName
ELSE @PrevLogicalServerName
END
,@PrevPrimary
= [Primary]
= CASE
WHEN LogicalServerName > ''
THEN LogicalServerName
ELSE @PrevLogicalServerName
END
,@SafetyCounter
= CASE
WHEN RowNum = @SafetyCounter
THEN @SafetyCounter + 1
ELSE 'Safety counter violation'
END
FROM #Result tgt WITH (TABLOCKX,INDEX(1))
OPTION (MAXDOP 1)
;
--==================================================================================================
-- Display the final result.
-- From here, you could use the contents of the #Result table to populate a final table
-- for all such results.
--==================================================================================================
SELECT LogicalServerName
,[Primary]
,assistUser
,[Role]
FROM #Result
ORDER BY RowNum
;[/code]
Since I'm absolutely NOT a PowerShell Ninja, it'll be interesting to see what others may come up with for PowerShell solutions rather than a stored procedure solution. I'm also sure that someone will modify the code to work a bit more simply using some of the new features that first became available with 2012. Part of the reason why I didn't do so is that I haven't been near a 2012+ box all weekend and prefer not to post any code that I've not been able to test.Let us know how it all works out.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Thanks Jeff,
PowerShell replacement of sql based stored procedures is part our project
bellow is solution I used (part of the code)#call to unix script
$UnixOutput = (Run-Cmd -command "listdbpriv -server $ServerName -user").split("`n")
#$LogicalServerName = Null
#$Primary1 = Null
#$AssistUser =Null
#$Role =Null
foreach( $UnixOutput_row in $UnixOutput)
{
#output produce extra empty line
if($UnixOutput_row.length -gt 0)
{#$UnixOutput_row = ($UnixOutput_row -replace '\s+', ' ')
$LogicalServerName = $UnixOutput_row.split()[0]
# first row of output contain column names
if($LogicalServerName -eq "LogicalServerName")
{
$LogicalServerName_start = $UnixOutput_row.IndexOf("LogicalServerName")
$Primary_start = $UnixOutput_row.IndexOf("Primary")
$assistUser_start = $UnixOutput_row.IndexOf("assistUser")
$Role_start = $UnixOutput_row.IndexOf("Role")
$len = $UnixOutput_row.Length
}
if(-not($LogicalServerName -eq "LogicalServerName"))
{
#format is logigalservername.dbname
$Primary_contain_dot = $UnixOutput_row.Substring($Primary_start,($AssistUser_start - $Primary_start))
if ($Primary_contain_dot -like '*.*')
{
$Primary1 = $Primary_contain_dot.split('.')[1]
}
$AssistUser = $UnixOutput_row.Substring($AssistUser_start,($Role_start - $AssistUser_start ))
$len = $UnixOutput_row.Length
$Role = $UnixOutput_row.Substring($Role_start,($len - $Role_start))
$SqlQuery ="
INSERT INTO [dbo].[ServerDbPrivUsers]
([ServerName]
-- ,[LogicalServerName]
,[Primary1]
,[assistUser]
,[Role])
VALUES
('$Servername',
-- '$Logicalservername',
'$Primary1',
'$AssistUser',
'$Role'
)"
...custom call to insert row in table
}
}
}
} - ebooklub - Monday, January 23, 2017 9:01 AM
Can you post the "custom call to insert row in table"? Seems like that might be sort'a important. 😉
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Hi Jeff
>Can you post the "custom call to insert row in table"? Seems like that might be sort'a importan
I can't post the code
it is company build PS object that call calls TSQL
PSObject]$SqlObject = $CompanyDataObject.ExecQuery($SqlQuery)
result return 1 or 0 as error code and log execution to txt file
Viewing 10 posts - 16 through 25 (of 25 total)
You must be logged in to reply to this topic. Login to reply