OK, I still think like a programmer -- is there a better way to do this?
-
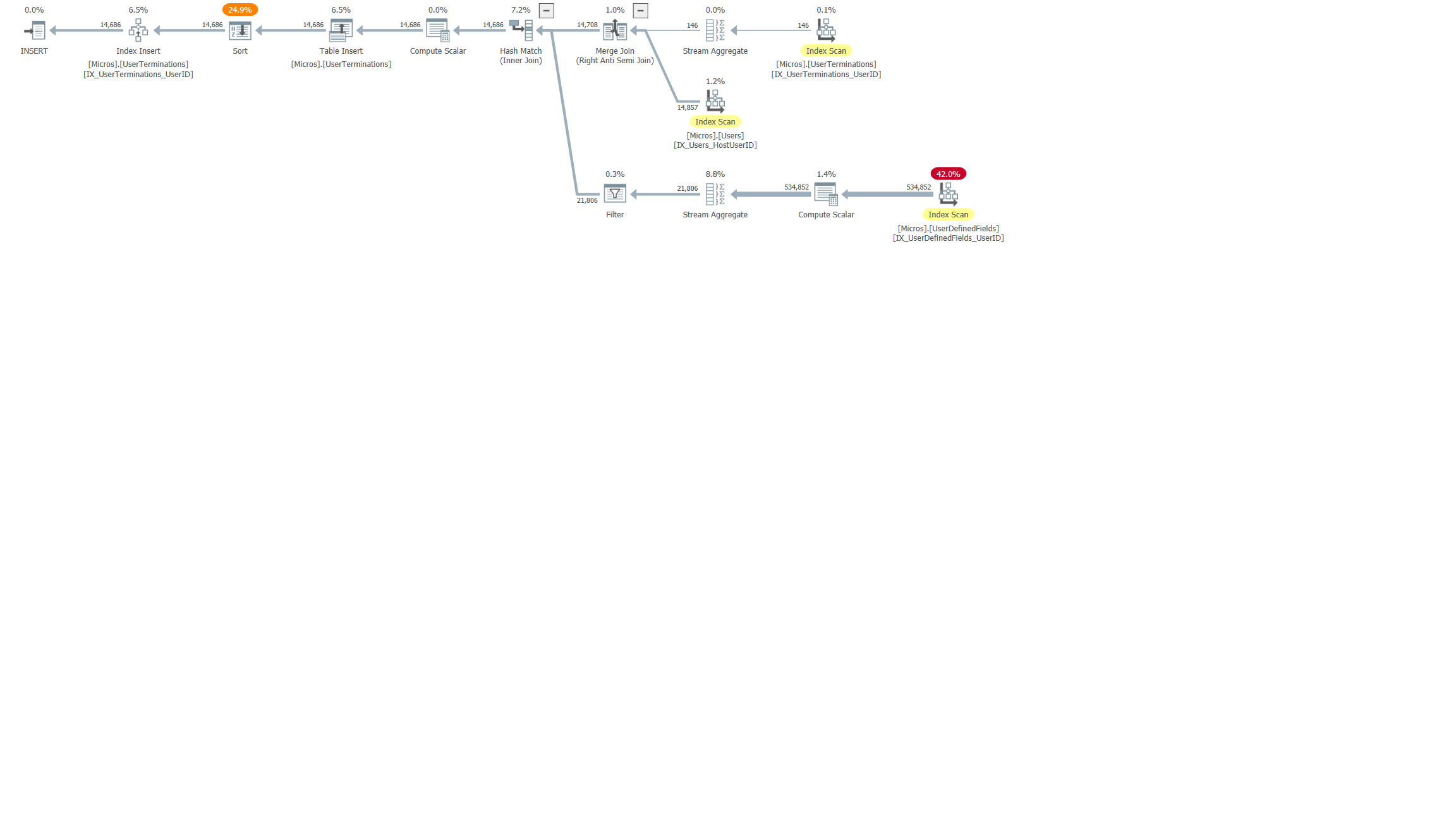
My SQL tools tell me this invokes an inefficient step with an index scan. I am treating this as a learning exercise since it's not really a problem, but I have code written by others (vendors) that I see this a lot and I'd like to be able to suggest fixes. The query plan is below.
INSERT INTO [Micros].[UserTerminations]
(
[UserID]
, [TerminationDateTime]
)
SELECT .[HostUserId] AS [UserID]
, getDate () AS [TerminationDateTime]
FROM [Micros].[Users] AS
LEFT JOIN (
SELECT [UserID]
, [FieldNo]
, [Value]
FROM [Micros].[UserDefinedFields]
) AS [SourceUserData]
PIVOT (
max([Value])
FOR [FieldNo] IN ([1], [2], [3], [4], [9])
) AS [pud]
ON [pud].[UserID] = .[HostUserId]
WHERE [pud].[9] = 'Terminated' --#999
AND .[HostUserId] NOT IN (
SELECT [UserID] FROM [Micros].[UserTerminations]
);
-
Here's an attempt to refactor the query with functional equivalency (afaik)
insert into [Micros].[UserTerminations]([UserID], [TerminationDateTime])
select u.[HostUserId], getdate()
from [Micros].[Users] AS u
where exists (select 1
from [Micros].[UserDefinedFields] udf
where udf.[UserID]=u.[HostUserId]
and udf.[FieldNo]= 9
having max([Value])= 'Terminated')
and not exists (select 1
from [Micros].[UserTerminations] ut
where ut.[UserID]=u.[HostUserId]);Aus dem Paradies, das Cantor uns geschaffen, soll uns niemand vertreiben können
- Steve Collins wrote:
Here's an attempt to refactor the query with functional equivalency (afaik)
insert into [Micros].[UserTerminations]([UserID], [TerminationDateTime])
select u.[HostUserId], getdate()
from [Micros].[Users] AS u
where exists (select 1
from [Micros].[UserDefinedFields] udf
where udf.[UserID]=u.[HostUserId]
and udf.[FieldNo]= 9
having max([Value])= 'Terminated')
and not exists (select 1
from [Micros].[UserTerminations] ut
where ut.[UserID]=u.[UserID]);Interesting.
The idea is to find the users in the main (Users) table who have a "#999%" Entry in field 9 of their associated UserDefinedFields records and who are not already in the UserTerminations table.
I took the root of your idea and came up with this which is wicked fast, but I need to test it for efficacy versus the existing (read: working) query.
WITH [Candidates]
([UserID], [FieldNo], [Value])
AS (SELECT .[HostUserId]
, [udf].[FieldNo]
, [udf].[Value]
FROM [Micros].[Users] AS
LEFT JOIN [Micros].[UserDefinedFields] AS [udf]
ON .[HostUserId] = [udf].[UserID]
RIGHT JOIN [Micros].[UserTerminations] [t]
ON .[HostUserId] = [t].[UserID]
WHERE [udf].[FieldNo] = '9'
AND [udf].[Value] LIKE '#999%'
AND [t].[UserID] IS NULL)
INSERT INTO [Micros].[UserTerminations]
(
[UserID]
, [TerminationDateTime]
) -
Solved.
- Stephen Rybacki wrote:
Solved.
How? With the reworked code you posted above?
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
So yes the combination of that plus fixing an underlying problem with the data itself. It turns out that the table that contains the users who have been terminated is not thoroughly populated with those who have actually been terminated according to the users table.
So by cleaning up the data and then doing a left join from the users table to the user termination table and checking for null in the user ID of the termination table, it gave me the exact said I needed.
I knew how to select out of a table those things that aren't in another table using the slip joint and no combination before, but my mistake was assuming that the data was accurate and it was not.
Thanks all,
Steve
-
Thanks for the feedback, Stephen. Heh... being an old dude, I can really sympathize with you on the bad data thing. It's been a problem even without computers since I can remember.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
The difference of bad data before and after computers is that bad data in computers can be perpetuated and disseminated so much faster.
And that more people believe the bad data because "the computer said so".
- GaryV wrote:
The difference of bad data before and after computers is that bad data in computers can be perpetuated and disseminated so much faster.
And that more people believe the bad data because "the computer said so".
Heh... On my first civilian job after the Navy and started working with computers a whole lot, my saying was "Yep... humans are prone to error but, if you really want to screw something up quickly, you need a computer". 😀
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally)
Viewing 9 posts - 1 through 9 (of 9 total)
You must be logged in to reply to this topic. Login to reply