Not getting expected index seek.
-
Here is the query and the indexes. I can't figure out for the life of me why I'm not getting an index seek on the lnc_ordno_seqno_includes index. Query plan attached. I feel like I'm missing something really simple. Thanks in advance.
select ol.ord_no, pl.ID
from oeordlin_wv ol
join wsPKGLin pl ON ol.Ord_no = pl.ord_no
AND ol.line_seq_no = pl.Seq_no
where ol.ord_type = 'O'
option (recompile, maxdop 1)/****** Object: Index [ioeordlin_sql0] Script Date: 8/23/2021 10:34:24 AM ******/CREATE UNIQUE CLUSTERED INDEX [ioeordlin_sql0] ON [dbo].[oeordlin_sql]
(
[ord_type] ASC,
[ord_no] ASC,
[line_seq_no] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
/****** Object: Index [lnc_ordno_seqno_includes] Script Date: 8/23/2021 10:32:59 AM ******/CREATE UNIQUE NONCLUSTERED INDEX [lnc_ordno_seqno_includes] ON [dbo].[wsPKGLin]
(
[Ord_no] ASC,
[Seq_no] ASC,
[PKG_ID] ASC,
[ID] ASC
)
INCLUDE ( [Line_no],
[Qty],
[Item_no]) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO -
Experts correct me if I am wrong, but what I am seeing is that you have no filter predicates on the non-clustered index scan. The filter is on the clustered index seek, so it can reduce that data set.
With the non-clustered index, the ONLY filters are based on the clustered index result set. So in order for SQL to determine the rows it needs, it is grabbing all of the data from the non-clustered index, the filtered result set from the clustered index, then JOINing them to reduce the data set. Prior to the JOIN operation, SQL has no knowledge of what values are valid from the non-clustered index.
Without filtering on the result set, SQL has no way to reduce the data and thus it must use a SCAN instead of a SEEK. If you NEED that to be a SEEK, you would need some column in that index to be added to your WHERE clause.
The above is all just my opinion on what you should do.
As with all advice you find on a random internet forum - you shouldn't blindly follow it. Always test on a test server to see if there is negative side effects before making changes to live!
I recommend you NEVER run "random code" you found online on any system you care about UNLESS you understand and can verify the code OR you don't care if the code trashes your system. -
I think you're right. I've found that if I use the LOOP hint to force a loop join, which passes thru the ord_no and line_seq_no thrue to the wspkglin join as predicates, i do get more logical reads but the query finished much faster and only reads 11000 rows of the lnc_ordno_seqno_includes vs the entire index. I'm confused as to why i would have to force the loop join, and also why it's so much faster even though it does nearly 2x the logical reads. Attached the new plan with forced loop join.
Merge join - 2560372 rows , 26,897 logical reads, .350 cpu, .355 elapsed.
Loop Join - 11,000 rows, 59,299 logical reads, .063 cpu, .064 elapsed.
-
I think that is the joys of the SQL engine. USUALLY logical reads are slow operations and having more of them will result in longer elapsed time. That is likely why the optimizer went with a MERGE join instead.
The other fun part - it may be faster on the specific CU level you are on of SQL 2016, but upgrading to a newer CU or newer version (2019 for example) COULD help performance. Or it could hurt performance.
Another fun query optimizer thing - it doesn't always pick the absolute best plan, it picks a good enough plan. The optimizer did its best to determine the "good enough" plan and went with it. If it had tried a bit harder, it MAY have decided that a loop join would be faster. I do think that making it 5 times faster is a pretty good improvement. My guess here is that the query optimizer got a low enough query cost and went with it. Since the estimated and actual rows are close to the same value for both indexes, updating statistics likely isn't going to help anything, but it is my usual "go to" solution when I see odd execution plan behavior. In your case, I don't think it will help.
As a thought - do you have it in a non-2016 Compatibility mode OR have the old query optimizer enabled? I think anything prior to 2014 for compat mode will use the old query optimizer.
The above is all just my opinion on what you should do.
As with all advice you find on a random internet forum - you shouldn't blindly follow it. Always test on a test server to see if there is negative side effects before making changes to live!
I recommend you NEVER run "random code" you found online on any system you care about UNLESS you understand and can verify the code OR you don't care if the code trashes your system. -
It also looks like you're querying a view for oeordlin rather than the actual table. If you are using a view, the text for that view would help us a lot at understanding what is going on.
The force-loop query is also using a different index on the oeordlin table. When looking at plans, we really need to be able to see all the indexes on a table, even if the current plan doesn't use them. Sometimes a simple mod to an existing index, such as including one more column or adding a key column, can make it a better choice for a given query.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
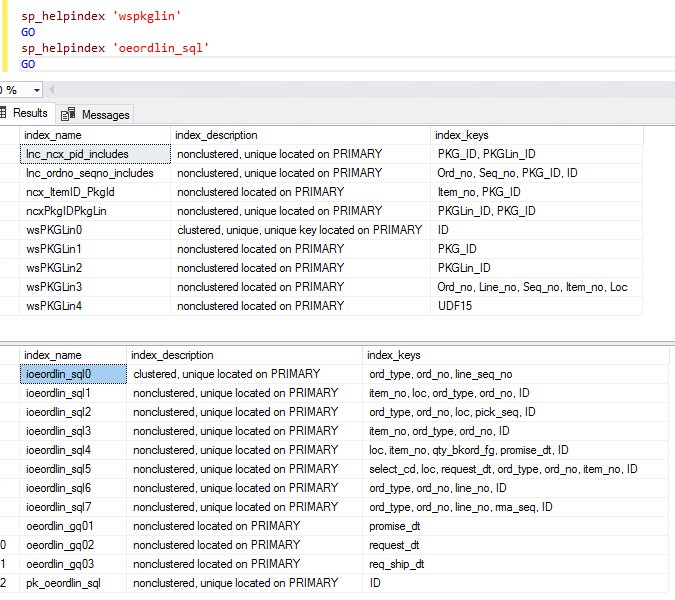
Here is all the indexes for the tables. If you need different format, let me know. P.S., the view only creates aliases for some of the columns in the oeordlin_sql table.

- Jackie Lowery wrote:
Here is all the indexes for the tables. If you need different format, let me know. P.S., the view only creates aliases for some of the columns in the oeordlin_sql table.
-
Better to script out the indexes; sp_helpindex doesn't show INCLUDEd columns, for one major failing.
A simple sys.sp_helptext on the view to show us its definition is fine.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
Looking at the Clustered Index for the oeordlin_sql table, I'm a wee bit concerned (especially for insert and update performance) over having the leading column be in the "ultra low cardinality" category of using something like the "ord_type" column seems to imply.
How's that working out for you? I ask only because it's quite unusual and doing such a thing on a non-clustered index in my early days caused a rather well known website to absolutely freeze up for about 3 minutes until we dropped the newly formed index.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden wrote:
Looking at the Clustered Index for the oeordlin_sql table, I'm a wee bit concerned (especially for insert and update performance) over having the leading column be in the "ultra low cardinality" category of using something like the "ord_type" column seems to imply.
How's that working out for you? I ask only because it's quite unusual and doing such a thing on a non-clustered index in my early days caused a rather well known website to absolutely freeze up for about 3 minutes until we dropped the newly formed index.
That was my thoughts as well. It should be ord_no, line_no, ord_type right? Ord_no and line_no would narrow it down to a single record nearly every time expect for the rare occasion they have the same order of a different type. Unfortunately, I can't make DDL changes to the table. If I even try to create my own indexes, it usually breaks upgrades. Is there any other way i can work around the issue?
- Jackie Lowery wrote:Jeff Moden wrote:
Looking at the Clustered Index for the oeordlin_sql table, I'm a wee bit concerned (especially for insert and update performance) over having the leading column be in the "ultra low cardinality" category of using something like the "ord_type" column seems to imply.
How's that working out for you? I ask only because it's quite unusual and doing such a thing on a non-clustered index in my early days caused a rather well known website to absolutely freeze up for about 3 minutes until we dropped the newly formed index.
That was my thoughts as well. It should be ord_no, line_no, ord_type right? Ord_no and line_no would narrow it down to a single record nearly every time expect for the rare occasion they have the same order of a different type. Unfortunately, I can't make DDL changes to the table. If I even try to create my own indexes, it usually breaks upgrades. Is there any other way i can work around the issue?
Actually, it depends on how the table is searched.
Do you often filter the rows by only type when SELECTing? If so, then the clus index makes sense as is. If you filter by type, and the type is not very selective, and the lead column on the clus index is not type, then SQL will pretty much have to scan the whole table unless you go the gazillions-of-covering-indexes-for-every-query route, and that's terrible for performance overall.
I'd probably add the type condition to the JOIN just in case:
ON ol.ord_type = 'O'
AND ol.Ord_no = pl.ord_no
AND ol.line_seq_no = pl.Seq_no
but SQL should do the equivalent of that itself anyway.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
- ScottPletcher wrote:
Actually, it depends on how the table is searched.
Do you often filter the rows by only type when SELECTing? If so, then the clus index makes sense as is. If you filter by type, and the type is not very selective, and the lead column on the clus index is not type, then SQL will pretty much have to scan the whole table unless you go the gazillions-of-covering-indexes-for-every-query route, and that's terrible for performance overall.
I'd probably add the type condition to the JOIN just in case:
ON ol.ord_type = 'O' AND ol.Ord_no = pl.ord_no AND ol.line_seq_no = pl.Seq_no
but SQL should do the equivalent of that itself anyway.
We do often filter the query by ord_type only, so i guess you're right as to why it is first in the clustered index.
I do wonder why the clustered index wasn't on the ID column, and the current clustered index could have instead been a non-clustered unique index on ord_type, ord_no, line_seq_no. I've always understood that for an INNER JOIN the filters could be placed on the join or in the where clause and it didn't matter.
- Jackie Lowery wrote:ScottPletcher wrote:
Actually, it depends on how the table is searched.
Do you often filter the rows by only type when SELECTing? If so, then the clus index makes sense as is. If you filter by type, and the type is not very selective, and the lead column on the clus index is not type, then SQL will pretty much have to scan the whole table unless you go the gazillions-of-covering-indexes-for-every-query route, and that's terrible for performance overall.
I'd probably add the type condition to the JOIN just in case:
ON ol.ord_type = 'O' AND ol.Ord_no = pl.ord_no AND ol.line_seq_no = pl.Seq_no
but SQL should do the equivalent of that itself anyway.
We do often filter the query by ord_type only, so i guess you're right as to why it is first in the clustered index.
I do wonder why the clustered index wasn't on the ID column, and the current clustered index could have instead been a non-clustered unique index on ord_type, ord_no, line_seq_no. I've always understood that for an INNER JOIN the filters could be placed on the join or in the where clause and it didn't matter.
Because if the clus index were on ord_type only, it would be useless for queries that specified WHERE ord_type = <whatever> unless it included every column needed by the query, i.e. was a covering index.
Sadly -- very sadly for overall performance -- most people do just automatically slap an id on as a clus key and then use nonclus for the actual search criteria. The problem with that is SQL is very selective/picky about using a non-covering non-clus index. Often the row count has to be extremely small or SQL just reverts to a full table scan instead.
So then people end up creating covering indexes for lots of queries. Index1 has ( ord_type, ord_no, line_seq_no ) INCLUDE ( col_d, col_f, col_g, col_r ) because that covers 1 query; then another index with ( ord_type, ord_no, line_seq_no ) INCLUDE ( col_e, col_f, col_i, col_q ); and on and on. And that ends up being vastly more overhead than just clustering the table properly to begin with.
I went thru all that partly to point out that that's a good warning sign that you may have the wrong clus key on a table: if you see lots of nonclus indexes that have the same key and different INCLUDEs.
More generally, if the clus index on a table is a $IDENTITY, and it's not a "master" table (customers, orders, etc.), you should very carefully examine whether the table has the best possible clustering key(s) or not, because it very likely does not. The majority of tables are not best clustered by $identity!
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
- Jackie Lowery wrote:Jeff Moden wrote:
Looking at the Clustered Index for the oeordlin_sql table, I'm a wee bit concerned (especially for insert and update performance) over having the leading column be in the "ultra low cardinality" category of using something like the "ord_type" column seems to imply.
How's that working out for you? I ask only because it's quite unusual and doing such a thing on a non-clustered index in my early days caused a rather well known website to absolutely freeze up for about 3 minutes until we dropped the newly formed index.
That was my thoughts as well. It should be ord_no, line_no, ord_type right? Ord_no and line_no would narrow it down to a single record nearly every time expect for the rare occasion they have the same order of a different type. Unfortunately, I can't make DDL changes to the table. If I even try to create my own indexes, it usually breaks upgrades. Is there any other way i can work around the issue?
"It Depends". It could actually be really good for queries that are looking for a particular order type on a regular basis and more often than just looking for a particular order number. I suspect, though, that looking for a particular order number is going to seriously outstrip other queries for usage.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden wrote:Jackie Lowery wrote:Jeff Moden wrote:
Looking at the Clustered Index for the oeordlin_sql table, I'm a wee bit concerned (especially for insert and update performance) over having the leading column be in the "ultra low cardinality" category of using something like the "ord_type" column seems to imply.
How's that working out for you? I ask only because it's quite unusual and doing such a thing on a non-clustered index in my early days caused a rather well known website to absolutely freeze up for about 3 minutes until we dropped the newly formed index.
That was my thoughts as well. It should be ord_no, line_no, ord_type right? Ord_no and line_no would narrow it down to a single record nearly every time expect for the rare occasion they have the same order of a different type. Unfortunately, I can't make DDL changes to the table. If I even try to create my own indexes, it usually breaks upgrades. Is there any other way i can work around the issue?
"It Depends". It could actually be really good for queries that are looking for a particular order type on a regular basis and more often than just looking for a particular order number. I suspect, though, that looking for a particular order number is going to seriously outstrip other queries for usage.
So create a nonclus index on ord_no, with other keys/columns as needed. Singleton lookups via a non-clus index are very efficient overall. Especially since, if you clus the table first on ord_no, then every search for type (only) will have to scan the entire table.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
Viewing 15 posts - 1 through 15 (of 16 total)
You must be logged in to reply to this topic. Login to reply