MERGING RECORDS
-
Hi all,
Thanks for any help given.
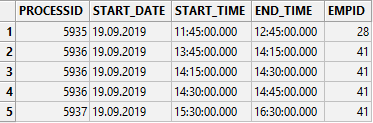
I have a table as below:

I want to write a query which merges rows together, if the processID, EmpID and start_date are the same, and the end_time matches the start_time.
So you can see where processed=5936 and empid = 41 and start_date are all the same, there are 3 record. The end_time of the first record is the same as the start_time of the second record. The second record end_time is the same as the third record's start_time… so these three records could be replaced with just one record, with a start_time of 13:45 and an end_time of 14:45.
I think this can be done with one update query, but cant figure it out. Also, I don't want it to run through the entire table.. I want to specify the processID, and it merges just these records, e.g. just where processID = 5936.
Hope that makes sense! Thanks very much. Below may help.
CREATE TABLE TABLE_PROCESSTIMES
(
PROCESSID INTEGER,
START_DATE DATE,
START_TIME TIME,
END_TIME TIME,
EMPID INTEGER
)
SELECT'5935','19.09.2019','11:45:00.000','12:45:00.000','28' UNION ALL
SELECT'5936','19.09.2019','13:45:00.000','14:15:00.000','41' UNION ALL
SELECT'5936','19.09.2019','14:15:00.000','14:30:00.000','41' UNION ALL
SELECT'5936','19.09.2019','14:30:00.000','14:45:00.000','41' UNION ALL
SELECT'5937','19.09.2019','15:30:00.000','16:30:00.000','41' -
Itzik Ben-Gan wrote an incredible article on this subject. You can find it at the following URL:
https://blogs.solidq.com/en/sqlserver/packing-intervals/
Because you're not using SQL Server 2012 or above, we can't use his more modern 3rd method.
With that, here's you're test data setup so that it actually works and works for everyone in case they want to play. I kept the same casing as you in case (no pun intended) you have a case-sensitive server. I do have to express a great dislike for the DATE and TIME data types because you have to combine them to do this simple type of date math if you want to survive possibly traversing midnight with your data for a given process.
CREATE TABLE #TABLE_PROCESSTIMES
(
PROCESSID INTEGER
,START_DATE DATE
,START_TIME TIME
,END_TIME TIME
,EMPID INTEGER
)
;
INSERT INTO #TABLE_PROCESSTIMES
(PROCESSID,START_DATE,START_TIME,END_TIME,EMPID)
SELECT '5935','20190919','11:45:00.000','12:45:00.000','28' UNION ALL
SELECT '5936','20190919','13:45:00.000','14:15:00.000','41' UNION ALL
SELECT '5936','20190919','14:15:00.000','14:30:00.000','41' UNION ALL
SELECT '5936','20190919','14:30:00.000','14:45:00.000','41' UNION ALL
SELECT '5937','20190919','15:30:00.000','16:30:00.000','41'
;And here's Itzik's very high performance method warped to fit your needs...
--===== Solve the problem using Itzik''s count up/count down method of grouping.
WITH
C1 AS
(--==== Find all the starts and number them as "S"
SELECT PROCESSID
,EMPID
,TS = CONVERT(DATETIME,START_DATE)+START_TIME
,Type = +1
,E = NULL
,S = ROW_NUMBER() OVER (PARTITION BY EMPID ORDER BY CONVERT(DATETIME,START_DATE)+START_TIME, PROCESSID)
FROM #TABLE_PROCESSTIMES
UNION ALL
--==== Find all the ends and number them as "E" and add 1 second of time to the "TS" (end time)
SELECT PROCESSID
,EMPID
,TS = DATEADD(ss,1,CONVERT(DATETIME,START_DATE)+END_TIME)
,Type = -1
,E = ROW_NUMBER() OVER(PARTITION BY EMPID ORDER BY DATEADD(ss,1,CONVERT(DATETIME,START_DATE)+END_TIME), PROCESSID)
,S = NULL
FROM #TABLE_PROCESSTIMES
)
,C2 AS
(--==== Create a sort order (SE) according to the time stamp, row type, and process ID by employee ID
SELECT c1.*
,SE = ROW_NUMBER() OVER (PARTITION BY EMPID ORDER BY TS, Type DESC, PROCESSID)
FROM C1 c1
)
,C3 AS
(--==== Create group numbers according to the beginning and end of contiguous times by employee ID
SELECT PROCESSID
,EMPID
,TS
,GrpNum = FLOOR((ROW_NUMBER() OVER(PARTITION BY EMPID ORDER BY TS)-1)/2+1)
FROM C2
WHERE COALESCE(S-(SE-S)-1, (SE-E)-E) = 0
)--===== Return the min and max times for each contiguous group for the final answer
SELECT PROCESSID
,EMPID
,Start_Date = MIN(TS)
,End_Date = MAX(DATEADD(ss,-1,TS))
FROM C3
GROUP BY PROCESSID, EMPID, GrpNum
ORDER BY PROCESSID, EMPID, START_DATE
;And here are the results...
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Hope this will help.
DECLARE @Table TABLE
(
PROCESSID INT
, START_DATE DATE
, START_TIME TIME
, END_TIME TIME
, EMPID INT
)
INSERT INTO @Table
(
PROCESSID
, START_DATE
, START_TIME
, END_TIME
, EMPID
)
VALUES
(
5935
, '2019-9-19'
, '11:45:00:000'
, '12:45:00:000'
, 28
)
,
(
5936
, '2019-9-19'
, '13:45:00:000'
, '14:15:00:000'
, 41
)
,
(
5936
, '2019-9-19'
, '14:15:00:000'
, '14:30:00:000'
, 41
)
,
(
5936
, '2019-9-19'
, '14:30:00:000'
, '14:45:00:000'
, 41
)
,
(
5937
, '2019-9-19'
, '15:30:00:000'
, '16:30:00:000'
, 41
)
SELECT * FROM @Table
; WITH cte_stag_1
AS
(
SELECT A.PROCESSID
, A.START_DATE
, A.EMPID
, MIN(A.START_TIME) AS START_TIME_MIN
FROM @Table A
INNER JOIN @Table B
ON B.PROCESSID = A.PROCESSID
AND B.EMPID = A.EMPID
AND B.START_DATE = A.START_DATE
GROUP BY A.PROCESSID
, A.START_DATE
, A.EMPID
)
, cte_stag_2
AS
(
SELECT A.PROCESSID
, A.START_DATE
, A.EMPID
, A.START_TIME_MIN
, MAX(B.END_TIME) AS END_TIME_MAX
FROM cte_stag_1 A
INNER JOIN @Table B
ON B.PROCESSID = A.PROCESSID
AND B.EMPID = A.EMPID
AND B.START_DATE = A.START_DATE
GROUP BY A.PROCESSID
, A.START_DATE
, A.EMPID
, A.START_TIME_MIN
)
SELECT PROCESSID
, START_DATE
, START_TIME_MIN AS START_TIME
, END_TIME_MAX AS END_TIME
, EMPID
FROM cte_stag_2
UNION ALL
SELECT A.PROCESSID
, A.START_DATE
, A.START_TIME
, A.END_TIME
, A.EMPID
FROM @Table A
LEFT JOIN cte_stag_2 B
ON B.PROCESSID = A.PROCESSID
AND B.EMPID = A.EMPID
AND B.START_DATE = A.START_DATE
WHERE B.PROCESSID IS NULL

Viewing 3 posts - 1 through 3 (of 3 total)
You must be logged in to reply to this topic. Login to reply