logging data with variable column count
-
I want to log a table (in this case Payroll) where number of columns might vary from time to time considering variable salary components and pay frequency for each employee and etc. This is how I keep salary data for each employee:

Payroll is generated pivoting for salary component and pay frequency and then adding other parameters like taxes, working hours and etc. from other tables. Finally, I want to store the final result in a simple Payroll table like:
payroll_date, payroll_type, payroll_data
'2021-04-30' , 'Monthly', [DATA]
'2021-04-14' , 'Biweekly', [DATA]
What data type I should use for payroll_data column? (considering performance, column size in the long run)
Is this a right approach for keeping data in a table when number of column vary from time to time?
-
What data would be contained in [DATA], and how would this table be used?
I would probably switch that to a view with a fixed pivot/cross-tab of all possible salary components. Those components not defined or used for that period would then contain a null value - and those that are defined would have the value defined. This would allow for easy generation of totals for year to date, last quarter, last month, etc.
Jeffrey Williams
“We are all faced with a series of great opportunities brilliantly disguised as impossible situations.”― Charles R. Swindoll
How to post questions to get better answers faster
Managing Transaction Logs -
Yes, there are NULL values for certain rows as some is not used or just used by one employee and not the other (e.g. Bonus). Besides a new component might be added later.
DATA is basically rows and columns of final select statement from multiple CTEs.
To explain further why columns number might increase overtime, consider a case when a certain salary component which hasn't been there initially is added by HR. So if I use a table with all columns to log the payroll, I'll need to add a new column every time a new component value is added by HR. To avoid that, I thought of using Pivot and the logging into a single format in one column.
So I want to know what data type/format I should use to store/log Payroll data for each date (row) into a single column?
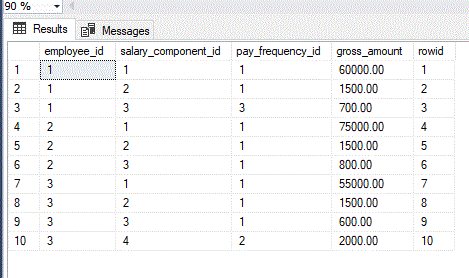
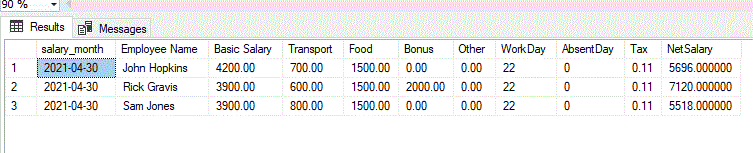
This is a sample select and output data for a few employees:
;WITH CTE AS(
SELECT
'2021-04-30' salary_month,
e.ename,
c.cname,
s.gross_amount
FROM salary s
JOIN employee e ON s.employee_id = e.id
JOIN salary_component c ON s.salary_component_id = c.id
), Payroll AS ( SELECT * FROM CTE
PIVOT (SUM(gross_amount) FOR cname IN ([Basic Salary],[Transport],[Food],[Bonus],[Other])) AS PVT
)
SELECT
salary_month,
ename [Employee Name],
[Basic Salary],
Transport,
Food,
ISNULL(Bonus,0) Bonus,
ISNULL(Other,0) Other,
'22' WorkDay,
'0' AbsentDay,
'0.11' Tax,
([Basic Salary]+Transport+Food+ISNULL(Bonus,0))-(([Basic Salary]+Transport+Food+ISNULL(Bonus,0))*0.11) [NetSalary]
FROM Payroll -
You don't create a table - and you don't create a table with delimited items in a single column like this. If you need a dynamic cross-tab/pivot then build a stored procedure that does this dynamically.
With that said - this should really be done in the reporting layer and not in SQL Server.
Jeffrey Williams
“We are all faced with a series of great opportunities brilliantly disguised as impossible situations.”― Charles R. Swindoll
How to post questions to get better answers faster
Managing Transaction Logs -
Agreed, you don't need nor want a separate table.
If you're having performance issues with the existing table generating your result using the PIVOT, then let's fix that issue, not create a separate table.
Also, the salary table should almost certainly be clustered on ( employee_id, salary_component_id ) for best performance. That should be unique. If somehow it's not (?), add $IDENTITY column to make it unique.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
PLEASE DISREGARD THIS POST. OTHERS REPLYING TO THIS ARE DOING A MUCH BETTER JOB ON THIS THAN THE BELOW ADVICE.
I agree with Jeffrey here - I would create a table that has all of the possible values and allow NULL for some of the columns. Storing data like how you are proposing in that "payroll_data" column may work for storing the data, but is going to become problematic when you to get the data out.
Lets say for example you do what you are proposing and then you select from that table for employee ID 1. You get a comma separated list of data in the payroll_data column with mixed number of fields and no header information for the columns? Not helpful, so lets say you put header1:value1, header2:value2 and so on in there - you now have a LOT of repeated data as each employee for that payroll_date is likely going to have the same number of header and values under their name. And building an index on that column is going to be tricky to have anything useful for searching. MOST of your SELECT queries are going to be SCANs instead of SEEKs.
Now, lets say you have 50 possible data points in the payroll data, so you create a table with 52 columns (so you can include the payroll_date and payroll_type). Now, lets say on average you have 10 of the 50 columns populated, with 40 of the 50 NULL, but there are some that MUST always be populated (such as "employeeID"). Now you can easily build an index on the employeeID (I'd even venture a guess that you could build a clustered index on EmployeeID, Payroll_Date, and RowID; maybe not in that order depending on how you normally lookup information in your table) and you'll be able to do seeks instead of scans when looking through your data.
This will also give you a lot more flexibility on how you use the data. For example, if you are frequently summing up the gross_amount column, this becomes trivial with the "lots of columns" approach, but is painful and slow to do with a single column holding all of the data that you need to split and parse.
Now, my above advice falls apart if you are using a different tool to parse the data. What I mean is if you have a tool that can parse XML incredibly fast, then storing the data in an XML column may work great for you. I personally am not a fan of storing XML in SQL as SQL Server isn't that quick at parsing XML data (as of SQL Server 2019, this may change in the future. I have heard nothing of it improving, but I can dream...). But if you have a nice .NET app that can grab raw XML and display it and filter it in a pretty manner to the end users, then that may be a better storage format in the database side.
The above is all just my opinion on what you should do.
As with all advice you find on a random internet forum - you shouldn't blindly follow it. Always test on a test server to see if there is negative side effects before making changes to live!
I recommend you NEVER run "random code" you found online on any system you care about UNLESS you understand and can verify the code OR you don't care if the code trashes your system. -
Don't forget about views: if you prefer that some people see a combined result as a table, you can use a view so they can see it as table, without actually having to create a physical table that re-stores the data.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
Yes, sorry. My reply was before I realized that this data is already stored inside SQL Server. I wouldn't bother making a new table for it when a view will do just as well.
Please ignore my post above as the advice is not relevant to this thread.
The above is all just my opinion on what you should do.
As with all advice you find on a random internet forum - you shouldn't blindly follow it. Always test on a test server to see if there is negative side effects before making changes to live!
I recommend you NEVER run "random code" you found online on any system you care about UNLESS you understand and can verify the code OR you don't care if the code trashes your system. - Jeffrey Williams wrote:
With that said - this should really be done in the reporting layer and not in SQL Server.
I understand this should be done on Reporting layer, but one of the main motives behind logging data is to avoid challenges of back-date reporting. Consider it is end of the year and Auditors want to look at past Payroll data. They simply don't care that we have stored Payroll data for each period in nice protected Excel files. They just want to extract it from system!
Now consider, how many employees who have been promoted (changed grades and salaries)… if an employee has left and his status changed to Resigned....maybe Tax changed...etc. So I have to keep a log of all changes, let alone increased report processing time to figure-out what was the value that has been altered?!!
ScottPletcher wrote:Don't forget about views: if you prefer that some people to see a combined result as a table, you can use a view so they can see it as table, without actually having to create a physical table that re-stores the data.
Yes, using Views is a more practical solution. I might use this method!
Mr. Brian Gale wrote:I would create a table that has all of the possible values and allow NULL for some of the columns. Storing data like how you are proposing in that "payroll_data" column may work for storing the data, but is going to become problematic when you to get the data out...
As long as there's way to read and calculate data dynamically (using Dynamic Pivot), why do it statically (having a table with multiple NULL columns) (unless absolutely necessary)?
I think this is a bad practice in every way....column naming will be something general which is bad naming convention...table looks bad with many NULL columns...and...
Mr. Brian Gale wrote:..What I mean is if you have a tool that can parse XML incredibly fast, then storing the data in an XML column may work great for you..
Initially, when I opened this post I had XML in mind, but I was not sure. I think it is okay in this case to store data into XML (or JSON) because logged data is not frequently accessed. Besides, I think processing time is eventually less costly than implementing the design in a way to support back-date reporting, right?!
Viewing 9 posts - 1 through 9 (of 9 total)
You must be logged in to reply to this topic. Login to reply