Loading 20% of an index in to memory to get a small % of the table's data
-
We have a table as follows:
CREATE TABLE [dbo].[TAudit_History](
[HistoryID] [int] IDENTITY(1,1) NOT NULL,
[FunctionalAreaID] [int] NULL,
[EntityID] [int] NULL,
[PrimaryKeyID] [int] NOT NULL,
[EntityDescription] [varchar](max) NULL,
[OldValue] [varchar](3500) NULL,
[OldValueDescription] [varchar](3500) NULL,
[NewValue] [varchar](3500) NULL,
[NewValueDescription] [varchar](3500) NULL,
[Date] [datetime] NOT NULL,
[User] [nvarchar](128) NULL,
[TableID] [int] NULL,
[ColumnID] [int] NULL,
CONSTRAINT [PK_TAudit_History] PRIMARY KEY CLUSTERED
(
[HistoryID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, FILLFACTOR = 100) ON [PRIMARY]
) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY]
GO
CREATE NONCLUSTERED INDEX [IX_TAudit_History_TableIDColumnID] ON [dbo].[TAudit_History]
(
[TableID] ASC,
[ColumnID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, FILLFACTOR = 80) ON [PRIMARY]So essentially a table with
- An integer, identity, clustered primary key
- A non-unique index on two of the columns
It's got about 176,375k rows in. So far, so good. If I run this query
Drop Table If Exists #Temp
-- Flush data out of memory.
Checkpoint
DBCC DROPCLEANBUFFERS WITH NO_INFOMSGS
Select dbo.IndexPercentInMemory ('PK_TAudit_History', 'TAudit_History') [PK],
dbo.IndexPercentInMemory ('IX_TAudit_History_TableIDColumnID', 'TAudit_History') [IX]
Select PrimaryKeyID, [Date], dbo.DateWithoutTime ([Date]) [ChangeDateWithoutTime], 'Created' [Message], 1 [TypeID]
Into #Temp
From dbo.TAudit_History
Where TableID = 14
And ColumnID = 56
Select dbo.IndexPercentInMemory ('PK_TAudit_History', 'TAudit_History') [PK],
dbo.IndexPercentInMemory ('IX_TAudit_History_TableIDColumnID', 'TAudit_History') [IX]The main select gets 404k rows from the database - that's 0.2% of the total (176,375k rows).
However, the final calls to the IndexPercentInMemory function (which uses sys.dm_db_partition_stats and sys.allocation_units etc. and is based on https://msdn.microsoft.com/en-us/library/ms173442.aspx) suggest that 19% of the table's primary key has been loaded in to memory, and that's bad for performance.
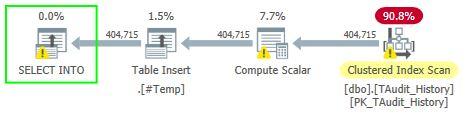
Here's the execution plan:

So it's scanning the primary key and not even using the index on TableID and ColumnID!
Does anybody know why this is happening? Thanks
-
Grant will probably have a great answer to this, but my suspicion would be that the optimiser decided that the cost of scanning the PK would be less than index seeks on TableId and ColumnId followed by lots of lookups to retrieve those columns in the SELECT which are not part of the index.
-
Thanks Phil. Yes, the engine will have done what the optimiser told it to do but I'm surprised, given there is an index on the very two columns I'm searching on and I'm only getting back 0.2% of the rows in the table.
It makes me wonder whether indexes are completely pointless! (OK - I know they're not.)
Presumably, if I include PrimaryKeyID and Date on IX_TAudit_History_TableIDColumnID it'll be a different, and happier story. I'll give that a go.
-
Are the statistics up to date? You might get a more detailed answer if you attach the Actual Execution Plan (as XML) for people to take a closer look at what is going on.
-
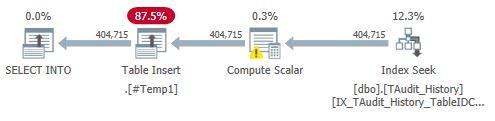
With PrimaryKeyID and Date included on the index, it's far faster and 0.23% of in the index is loaded but none of the primary key, as expected:
<b></b><i></i><u></u>But I'd prefer not to do that, as it would make my index bigger and slower to maintain and I still feel that it shouldn't be necessary!
I'll revert, refresh statistics and see if that helps.
-
Shifting gears a bit, Julian... I'm curios as to what you would be putting into the OldValueDescription and NewValueDescription columns. I've not seen anyone have such columns on this type of columnar auditing.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Jeff,
The TAudit_History table is used to record changes to data in much of the rest of the database. So if I change the value in the Surname field of a record in a table from 'Sidebottom' to 'Cholmondley-Warner', you'd get
- OldValueDescription = 'Sidebottom'
- NewValueDescription = 'Cholmondley-Warner'
In the case of the field being a lookup to another table, changing a person's ethnicity from 'Caribbean (D1)' to 'White and Asian (B3)' might mean EthnicityID being changed from 43 to 27. That's not terribly helpful when it comes to reporting on what was actually done, so here you'd get
- OldValue = 43
- OldValueDescription = 'Caribbean (D1)'
- NewValue = 27
- NewValueDescription = 'White and Asian (B3)'
That also means somebody can subsequently go and change entries in the lookup table without affecting this audit record. (Of course, that wouldn't be a terribly good idea in this particular case, but that's the idea.)
Having all the audit data in one table has its advantages and disadvantages of course, but it does mean you only need to go to one table to get the auditing information of any table (and column) in the database. Hence the original question about
Select PrimaryKeyID, [Date], dbo.DateWithoutTime ([Date]) [ChangeDateWithoutTime], 'Created' [Message], 1 [TypeID]
Into #Temp1
From dbo.TAudit_History
Where TableID = 14
And ColumnID = 56 -
Thanks for taking the time to explain that, Julian.
Shifting gears a bit, since none of the VARCHAR(3500) columns are actually worth a hoot in an index, you might want to consider forcing them to be out of row, which would seriously improve the performance of any table scans you might end up with in the future. It would also seriously decrease the size of the Clustered Index.
For a similar audit table that I've had to contend with, I also changed the OldValue and NewValue columns to SQL_VARIANT, which is probably the only place where I'd even consider using that particular datatype. Not saying you should make that change (it does have some caveates) but it's a consideration that has helped me.
If you decide to force the VARCHAR(3500) columns to out-of-row, I can help.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
My pleasure entirely.
As it happens, we did consider moving all the data out to a new table (imaginatively called TAudit_Data) just earlier this year. Then TAudit_History would have had columns such as
- EntityDescriptionDataID
- OldValueDescriptionDataID
- NewValueDescriptionDataID
That would also have allowed us to store only distinct values in TAudit_Data, which might also have helped save overall space.
I'm not sure why we didn't pursue that - I think we got side-tracked!
We've got 1056 tables in our databases and 29466 columns and I can tell you not a single one of them is a SQL_VARIANT! How would that be an improvement over our VARCHAR (3500) columns?
-
Because then your triggers don't have to be coded to do the conversions to VARCHAR().
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Oh I see. 90% of the triggers are autogenerated so it's not really a problem.
However, I will see if I can resurrect the idea of moving all the textual data off TAudit_History in to TAudit_Data as you suggested.
Thanks.
-
Actually, 100% can be generated using a little dynamic SQL, sys.columns, and sys.indexes. I wrote some code for work that people are using. I'll see if I can find the original.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
That would be interesting if you could.
What I meant by "90% of the triggers are autogenerated" is that 90% of the triggers are fully autogenerated and 10% have to be hand-written to some extent.
 <b></b><i></i><u></u>
<b></b><i></i><u></u>Viewing 13 posts - 1 through 13 (of 13 total)
You must be logged in to reply to this topic. Login to reply