Issue in a hierarchy
-
Hi,
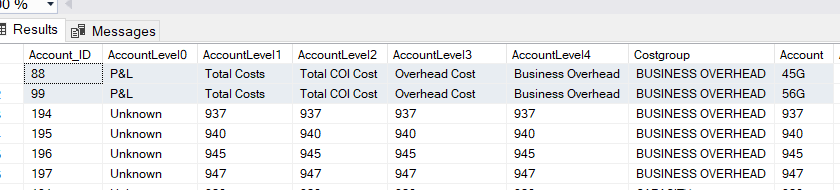
I am trying to create a hierarchy but due to the data structure, it fails. When I process the dimension it is failed due to duplicate found. Please find the images below. Some how the hierarchy considers the first couple of records shown in the first image as duplicate. I am not able to figure it out. Can some help me to find out what is possibly going wrong? Also would like to inform that according to the data set in the table, it is a ragged hierarchy.

Thanks,
Charmer -
The issue i ran into somethimes is when 2 rows of a column in the Dimension have different Name Column values.
Example:
- AccountLevel0 = P&L
Name Column:
- Row1: AccountLevel0_Name = Name
- Row2: AccountLevel0_Name = anotherNAME
I want to be the very best
https://www.sqlservercentral.com/articles/forum-etiquette-how-to-post-datacode-on-a-forum-to-get-the-best-help
Like no one ever was -
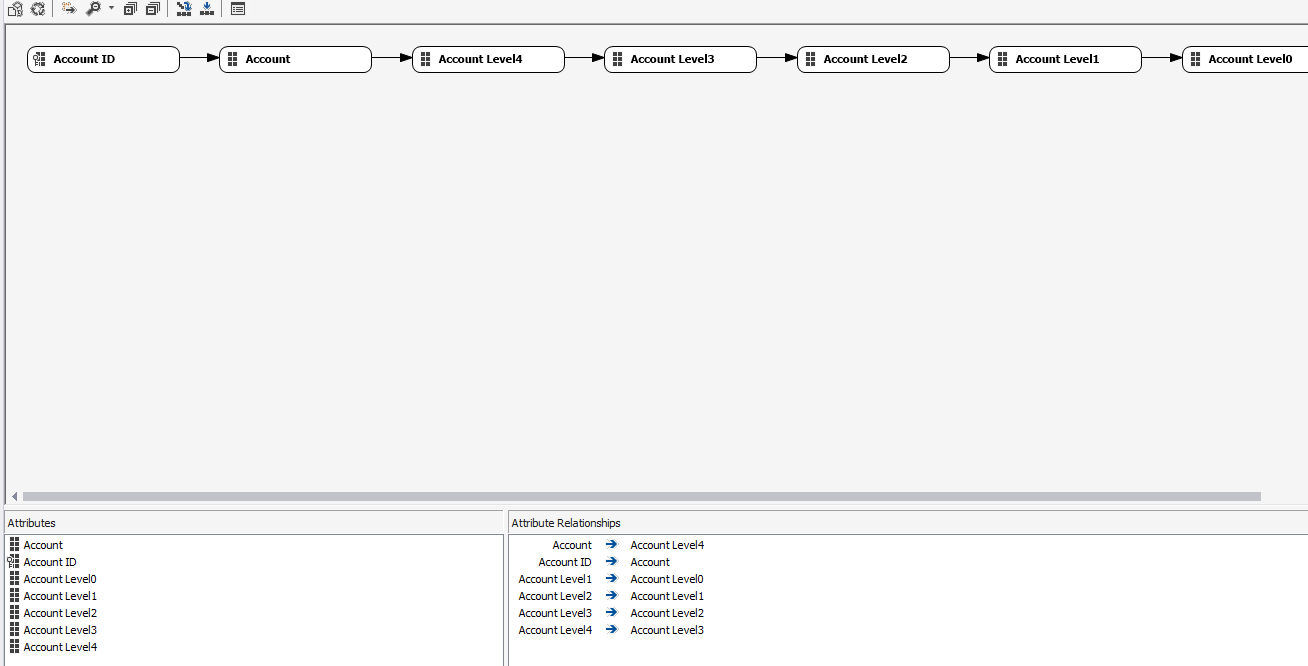
It's because your "Account Level 0" attribute is finding a duplicate composite of the dimension key (e.g 88 and 99 are both P&L). You need to make the KeyColumns property of Account Level 0 a combination of Account Level 0 and Account_ID.
More on this here: https://www.mssqltips.com/sqlservertip/3271/sql-server-analysis-server-ssas-keycolumn-vs-namecolumn-vs-valuecolumn/
I'm on LinkedIn -
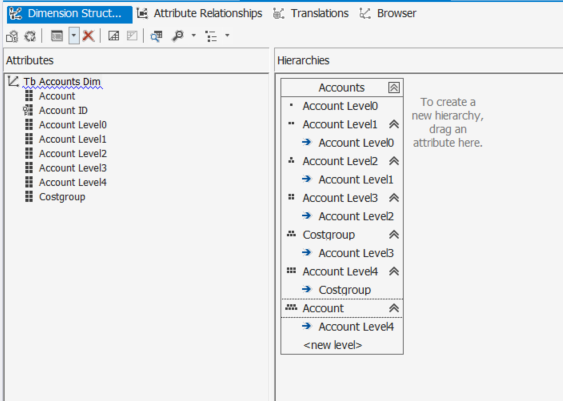
This issue is happening only when I include cost group column in the hierarchy. I am just wondering, why hierarchy works only if I don't include cost group column , though I still find it is a duplicate.
Thanks,
Charmer -
It very much depends on how you have each attribute set up (the key columns and the attribute relationships) but what you have to bear in mind is that when SSAS processes a dimension it is issuing a lot of SELECT DISTINCT queries to your data source to determine members of each attribute/hierarchy.
In your case, imagine that you have Cost Group in your hierarchy at a level between Account and Account Level 4 - that's not going to work as the relationship between Account and Cost Group is many to one.
Essentially you have Cost Group at the incorrect level in your hierarchy because the cost group "BUSINESS OVERHEAD" has >1 Account values.
I'm on LinkedIn -
Yeah exactly. I struggling to include cost group in the hierarchy as you rightly said it is many to one account. What could be the solution ? Should I take cost group out of this hierarchy and table and use it as a new dimension/table?
Thanks,
Charmer -
Work out the cardinality of it vs the cardinality of the other attributes (taking into account composite keys and existing relationships) and then place it in the appropriate place in your attribute relationships/hierarchy relationships.
Have a read of the following for a better understanding of this concept: https://www.mssqltips.com/sqlservertip/3414/sql-server-analysis-services-attribute-relationships/
I'm on LinkedIn - PB_BI wrote:
It very much depends on how you have each attribute set up (the key columns and the attribute relationships) but what you have to bear in mind is that when SSAS processes a dimension it is issuing a lot of SELECT DISTINCT queries to your data source to determine members of each attribute/hierarchy.
In your case, imagine that you have Cost Group in your hierarchy at a level between Account and Account Level 4 - that's not going to work as the relationship between Account and Cost Group is many to one.
Essentially you have Cost Group at the incorrect level in your hierarchy because the cost group "BUSINESS OVERHEAD" has >1 Account values.
I am kind of confused how the hierarchy works without any problem when cost group is not used. I still think that it is a duplicate without using cost group but some how ssas considers this not.
Thanks,
Charmer -
Because you are attempting to put Cost Group in a position in a relationship where it does not belong. The attribute relationships/keys are how SSAS determines what SQL to run when processing, so if the cardinality of an attribute at a higher level is many to the one attribute being processed then it will not work as it cannot resolve the attribute as unique. Run a trace on your source and do a process of this dimension with and without cost group. Examine the queries that are being run - run them yourself and you will understand why this is happening.
Once you understand this, if you still think that Cost Group belongs in the place that you are putting it, related in the way that you are specifying it, then you can simply instruct SSAS to ignore these errors in the dimension properties.
I'm on LinkedIn -
Yeah, now I got your point. I could see why it is many to one. Unfortunately the users wants the cost group to put it in that particular level. How do I ignore the errors? I wanna try once.
Thanks,
Charmer - PB_BI wrote:
Because you are attempting to put Cost Group in a position in a relationship where it does not belong. The attribute relationships/keys are how SSAS determines what SQL to run when processing, so if the cardinality of an attribute at a higher level is many to the one attribute being processed then it will not work as it cannot resolve the attribute as unique. Run a trace on your source and do a process of this dimension with and without cost group. Examine the queries that are being run - run them yourself and you will understand why this is happening.
Once you understand this, if you still think that Cost Group belongs in the place that you are putting it, related in the way that you are specifying it, then you can simply instruct SSAS to ignore these errors in the dimension properties.
Just wondering, is there any other way to deal with this ? Put cost group in different level or change in the dimension structure? I would like to recommend that to the user if there is any other way to handle this.
Thanks,
Charmer -
You have to change the error configuration in the dimension properties to ignore key duplicates: https://docs.microsoft.com/en-us/analysis-services/multidimensional-models/error-configuration-for-cube-partition-and-dimension-processing#bkmk_dupe
This can really mess up your query performance but if it's what the users want.....
I'm on LinkedIn - PB_BI wrote:
You have to change the error configuration in the dimension properties to ignore key duplicates: https://docs.microsoft.com/en-us/analysis-services/multidimensional-models/error-configuration-for-cube-partition-and-dimension-processing#bkmk_dupe
This can really mess up your query performance but if it's what the users want.....
I tried but wow. It completely messed up the value in the cube. I think I will have to create a many to many dimension.
Thanks,
Charmer -
You would have to do some analysis of your data and determine where in the hierarchy, if at all, cost group should go. Bear in mind that users can always drop attributes into their own analysis in any way they see fit - creating their own hierarchies. It's recommended that attributes that form a hierarchy are not separately exposed because when users do this they will encounter duplicates/other strange behavior ( e.g. If you had a geographical hierarchy you could drag country below city - it would work but it would just look odd).
I'm on LinkedIn - PB_BI wrote:
You would have to do some analysis of your data and determine where in the hierarchy, if at all, cost group should go. Bear in mind that users can always drop attributes into their own analysis in any way they see fit - creating their own hierarchies. It's recommended that attributes that form a hierarchy are not separately exposed because when users do this they will encounter duplicates/other strange behavior ( e.g. If you had a geographical hierarchy you could drag country below city - it would work but it would just look odd).
I would like to thank you for all your suggestions. I found out the issue as it was in the data that needs to be changed. It should be one to many.
Thanks,
Charmer
Viewing 15 posts - 1 through 15 (of 15 total)
You must be logged in to reply to this topic. Login to reply