Is there another way to solve this "group in 5 day spans" problem?
-
I ran into an interesting problem over on StackOverflow at the following link...
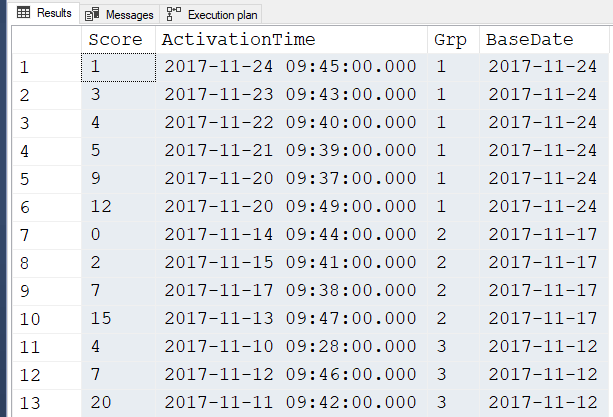
To summarize, here's the data the op posted with 1 row removed because removing that row broke the "Accepted" solution.
DROP TABLE IF EXISTS #MyHead;
GO
SELECT *
INTO #MyHead
FROM (VALUES
(1 ,'2017-11-24 09:45:00.000') --These should be in Grp #1.
,(3 ,'2017-11-23 09:43:00.000') --The 24th thru the 20th is a 5 day span
,(4 ,'2017-11-22 09:40:00.000')
,(5 ,'2017-11-21 09:39:00.000')
,(12 ,'2017-11-20 09:49:00.000')
,(9 ,'2017-11-20 09:37:00.000')
--<--<< Notice that there are 2 days in this gap.
,(7 ,'2017-11-17 09:38:00.000') --Group 2 starts here, as does a new
,(2 ,'2017-11-15 09:41:00.000') --span start date. Even though there are
,(0 ,'2017-11-14 09:44:00.000') --less than 5 entries, the span goes from
,(15 ,'2017-11-13 09:47:00.000') --the 17 to the 13th, which is 5 days
--<--<< Notice that this actually isn't a gap.
,(7 ,'2017-11-12 09:46:00.000') --Group 3 starts here, as does a new
,(20 ,'2017-11-11 09:42:00.000') --span start date
,(4 ,'2017-11-10 09:28:00.000')
)v(Score,ActivationTime)
;That also contains an explanation of what the OP wants the code to do. Basically, start at the latest date and include all rows that are within the 5 days (inclusive of that first date). Then, starting with the next row (which is a couple of days earlier), use that date as a new starting date for the next 5 day group. Notice that for the 3rd group (following the same rules), there are no missed days.
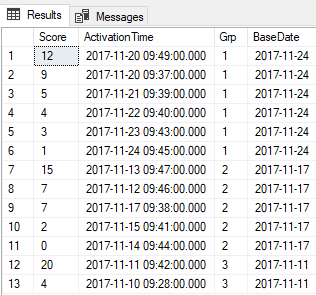
Here's the output from the "Quirky Update" method that I used to solve it.

The OP didn't want the "Base Date" column. I added that just to see what I was doing. The OP DOES want the Grp column. Also notice that within each 5 day group, it's sorted in order by the score and not the date. I know... that makes no sense to me either but that's what they wanted, perhaps just for easy reading for some form of analysis. That's the easy part, though. Getting the groups of 5 day spans is the hard part.
This poor ol' head of mine isn't working like it used to and so I thought I'd ask for some help. Is there a way to produce the output of the left 3 columns (Score, ActivationTime, Grp) in a manner (other than RBAR) to do this with Windowing Functions or some such? If so, I sure would like to see it.
Thanks for the help folks. Looking forward to answers even if it's "Nope... can't be done" (without the Quirky Update).
I posted this in the 2022 forum just in case there's a new wonder there but it would be cool to see it solved using SQL Server 2016.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
I think I would resort to the RBAR cursor method:
DROP TABLE IF EXISTS #Results;
CREATE TABLE #Results(Score int, ActivationTime datetime, Grp int, BaseDate date)
DECLARE @Score int, @ActivationTime datetime
DECLARE @BaseDate datetime, @Counter int = 0, @Grp int = 1
DECLARE myCursor CURSOR LOCAL FAST_FORWARD
FOR select h.Score, h.ActivationTime
from #MyHead h
order by ActivationTime desc
OPEN myCursor
FETCH NEXT FROM myCursor INTO @Score, @ActivationTime
SET @BaseDate = @ActivationTime
WHILE @@FETCH_STATUS = 0 BEGIN
IF @BaseDate > DATEADD(dd, 5, @ActivationTime) BEGIN
SELECT @BaseDate=@ActivationTime, @Grp+=1
END
INSERT INTO #Results(Score, ActivationTime, Grp, BaseDate) VALUES (@Score, @ActivationTime, @Grp, @BaseDate)
FETCH NEXT FROM myCursor INTO @Score, @ActivationTime
END
CLOSE myCursor
DEALLOCATE myCursor
SELECT *
FROM #Results
ORDER BY Grp, Score DESC;The difference between 2017-11-12 09:46 and 2017-11-17 09:38 is 8 minutes less than 5 days so is in Grp 2.
What SQL did you use to solve it?
- Jonathan AC Roberts wrote:
What SQL did you use to solve it?
Ah... sorry. Like I said, I used the "Quirky Update" method, which allows variables to interplay with columns as each row passes, just like RBAR methods but at set-based speeds. Microsoft has it documented but they say it's not controllable for more than 1 row at a time. I've been using it literally for decades (it was the only non-RBAR method to do running totals prior to 2012) and I wish two things... that MS would figure out that it actually is controllable and I wish they'd figure out how to make it so we could do it in SELECTs. The closest they've come, so far, is the Windowing functions. I'm not sure how to limit one in such a fashion to effectively find the totally unpredictable "BaseDate"s in this problem.
This could probably be done using Windowing functions but I think the resource usage would be a whole lot higher and performance wouldn't be quite as good.
Here's my code that uses the test data above. I've repeated the test data here just to make things easy.
(Lordy, the double-spacing of code the code windows on this site does makes this look crazy long... It's actually kinda short for what it does).
--=================================================================================================
-- Original data by the OP but sorted by date in descending order so we can see things.
--=================================================================================================
DROP TABLE IF EXISTS #MyHead;
GO
SELECT *
INTO #MyHead
FROM (VALUES
(1 ,'2017-11-24 09:45:00.000') --5 day span in this group
,(3 ,'2017-11-23 09:43:00.000')
,(4 ,'2017-11-22 09:40:00.000')
,(5 ,'2017-11-21 09:39:00.000')
,(12 ,'2017-11-20 09:49:00.000')
,(9 ,'2017-11-20 09:37:00.000')
,(7 ,'2017-11-17 09:38:00.000') -- This is what group 2 should be.
,(2 ,'2017-11-15 09:41:00.000')
,(0 ,'2017-11-14 09:44:00.000')
,(15 ,'2017-11-13 09:47:00.000')
--,(3 ,'2017-11-13 09:37:57.570') --Removing this row of data caused "Accepted" solution to fail
--but the QU method has no issues whether it's present or not.
,(7 ,'2017-11-12 09:46:00.000')
,(20 ,'2017-11-11 09:42:00.000')
,(4 ,'2017-11-10 09:28:00.000')
)v(Score,ActivationTime)
;
GO
--=================================================================================================
-- My High performance "Quirky Update" solution.
--=================================================================================================
--===== Create and populate a tempory table, much like a Windowing function does but physical
-- so we can reuse it. Note that the CI is quintessential here and the temp table is
-- necessary because the original table may have other indexes on it or the CI may change.
-- Again, this is similar to how Windowing functions work but without the CI.
DROP TABLE IF EXISTS #QU;
GO
CREATE TABLE #QU
(
RowNum INT PRIMARY KEY CLUSTERED
,Score INT
,ActivationTime DATETIME
,WholeDate AS CONVERT(DATE,ActivationTime) PERSISTED
,Grp INT
,BaseDate DATE
)
;
--===== This does the "sequencing"
INSERT INTO #QU WITH (TABLOCK) --For Minimal Logging if not in FULL Recovery Model
(RowNum,Score,ActivationTime)
SELECT RowNum = ROW_NUMBER() OVER (ORDER BY ActivationTime DESC, Score DESC)
,Score
,ActivationTIme
FROM #MyHead
ORDER BY ActivationTime DESC --Pedantic assurance of order and Minimal Logging
,Score DESC
OPTION (MAXDOP 1) --Pedantic assurance.
;
--===== Uncomment to see the contents of the Temp Table.
-- SELECT *
-- FROM #QU
-- ORDER BY ActivationTime DESC, Score DESC
--;
---------------------------------------------------------------------------------------------------
--===== Some necessary variables much like a RBAR method would require.
DECLARE
@RowSafety INT = 1
,@Grp INT = 0
,@LastDate DATE = '99991231'
,@GrpDate DATE = '99991230'
;
--===== Solve the problem with the "Quirky Update" method.
-- Works exactly the same as a While loop but without the RBAR.
-- It uses the "Pseudo-Cursor" of the table rows.
UPDATE tgt
SET @Grp = tgt.Grp = @Grp
+ IIF(DATEDIFF(dd,tgt.WholeDate,@GrpDate)>=5
AND @LastDate <> tgt.WholeDate
,1, 0)
,@GrpDate = BaseDate = IIF(DATEDIFF(dd,tgt.WholeDate,@GrpDate)>=5
AND @LastDate <> tgt.WholeDate
,tgt.WholeDate, @GrpDate)
,@LastDate = tgt.WholeDate
,@RowSafety = @RowSafety + IIF(RowNum = @RowSafety, 1, 1/0) --Produces an error ONLY if not synced
FROM #QU tgt WITH (INDEX(1)) --Force the usage of the CI in the temp table to control the logical order.
OPTION (MAXDOP 1) --Absolutely required to prevent parallelism for this serial action.
;
--===== Display the results.
-- Notice that the final display order is differnt than the processing order
-- because of the requirement to sort by Score within each group.
SELECT Score, ActivationTime, Grp, BaseDate FROM #QU
ORDER BY Grp ASC, Score ASC, ActivationTime DESC
;--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
p.s. Your "Group 2" is incorrect according to the requirements. Just to be sure, they're based on WHOLE days and the date span must be 5 days or less based on the data.
The fellow with the "Accepted" answer made the same mistake and worse because he used DENSE_RANK on the days. Unfortunately for him, there were enough days in the original data for group 2 to make it look like it worked but resulted in the silent failure.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
I do not think this type of problem is solvable with windowed functions as the result is dependent on previous values in the series. In this case I cannot see anyway to predict when missing dates are needed (2017-11-16) or not needed (2017-11-19 & 2017-11-18). Maybe someone with a more mathematical background can prove this.
Like you I suspect the quirky update will be the quickest t-sql solution but a cursor or recursion may be fine with less than 5,000 rows. If the result is needed for an application the best solution is probably to off load the grouping and additional sorting to the application servers as they will be easier and cheaper to scale.
- Jeff Moden wrote:
The fellow with the "Accepted" answer made the same mistake and worse because he used DENSE_RANK on the days. Unfortunately for him, there were enough days in the original data for group 2 to make it look like it worked but resulted in the silent failure.
Yes DENSE_RANK seems inappropriate and only appeared to work imo. The issue seems to be I'm not finding a solution without 'time' (the series summation of prior gap adjustments) being part of the equation. The inter-group gaps would need to be carried forward afaik. Idk
Aus dem Paradies, das Cantor uns geschaffen, soll uns niemand vertreiben können
-
@ken McKelvey. Thanks for looking and thanks for the confirmation in a couple of areas, here, Ken.
I've seen some mathematical magic in the past with "Gaps and Islands", which this problem actually is, but with the twist of limiting how long the island can be. I'm going to look a bit more deeply into that possibility.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
@ Peter Larsson...
You've been popping up on some of the formula related posts that I've posted to and you're listed as a "follower". Any ideas/solutions here?
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
@ Steve Collins ,
Agreed and, except for RBAR or "Quirky Update" solutions, I'm not seeing a way to do this. This is also kind of like the "Bin Fill" problem. I've not seen a "Single Query" solution even with multiple sub-queries in the form of CTEs, actual sub-queries, APPLYs, what have you.
I was thinking about Itzik's Ben-Gan's ultimate "Packing Intervals" solution, which also has interval forgiveness, but it doesn't have the nuance of 5 day Bins with separate "Bin Start Dates" that aren't necessarily less than 5 days apart.
Fun stuff.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
@ Jonathan, Ken, and Steve,
Thank all 3 of you for lending and ear and basically confirming that this is actually a real booger of a problem. I really appreciate it, especially between the two end of year holidays.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
One approach could be to use a WHILE loop to increment grp values based on row counts and the DATEDIFF interval
Starting with Jeff's code:
--=================================================================================================
-- Original data by the OP but sorted by date in descending order so we can see things.
--=================================================================================================
DROP TABLE IF EXISTS #MyHead;
GO
SELECT *
INTO #MyHead
FROM (VALUES
(1 ,'2017-11-24 09:45:00.000') --5 day span in this group
,(3 ,'2017-11-23 09:43:00.000')
,(4 ,'2017-11-22 09:40:00.000')
,(5 ,'2017-11-21 09:39:00.000')
,(12 ,'2017-11-20 09:49:00.000')
,(9 ,'2017-11-20 09:37:00.000')
,(7 ,'2017-11-17 09:38:00.000') -- This is what group 2 should be.
,(2 ,'2017-11-15 09:41:00.000')
,(0 ,'2017-11-14 09:44:00.000')
,(15 ,'2017-11-13 09:47:00.000')
--,(3 ,'2017-11-13 09:37:57.570') --Removing this row of data caused "Accepted" solution to fail
--but the QU method has no issues whether it's present or not.
,(7 ,'2017-11-12 09:46:00.000')
,(20 ,'2017-11-11 09:42:00.000')
,(4 ,'2017-11-10 09:28:00.000')
)v(Score,ActivationTime)
;
GO
--=================================================================================================
-- My High performance "Quirky Update" solution.
--=================================================================================================
--===== Create and populate a tempory table, much like a Windowing function does but physical
-- so we can reuse it. Note that the CI is quintessential here and the temp table is
-- necessary because the original table may have other indexes on it or the CI may change.
-- Again, this is similar to how Windowing functions work but without the CI.
declare
@qu_row_count int=0,
@grp_row_count int=0,
@grp int=1;
DROP TABLE IF EXISTS #QU;
CREATE TABLE #QU
(
RowNum INT PRIMARY KEY CLUSTERED
,Score INT
,ActivationTime DATETIME
,WholeDate AS CONVERT(DATE,ActivationTime) PERSISTED
,Grp INT
,BaseDate DATE
)
;
--===== This does the "sequencing"
INSERT INTO #QU WITH (TABLOCK) --For Minimal Logging if not in FULL Recovery Model
(RowNum,Score,ActivationTime)
SELECT RowNum = ROW_NUMBER() OVER (ORDER BY ActivationTime DESC, Score DESC)
,Score
,ActivationTIme
FROM #MyHead
ORDER BY ActivationTime DESC --Pedantic assurance of order and Minimal Logging
,Score DESC
OPTION (MAXDOP 1) --Pedantic assurance.
;
select @qu_row_count=@@rowcount;
while @qu_row_count<>@grp_row_count
begin
with top_cte as (
select top(1) ActivationTime
from #qu
where grp is null
order by ActivationTime desc)
update qu
set grp=@grp
from #qu qu
cross join top_cte tc
where qu.grp is null
and datediff(day, qu.ActivationTime, tc.ActivationTime)<5;
select @grp_row_count=@grp_row_count+@@rowcount;
select @grp=@grp+1;
end
--===== Uncomment to see the contents of the Temp Table.
SELECT *
FROM #QU
ORDER BY ActivationTime DESC, Score DESC
;Aus dem Paradies, das Cantor uns geschaffen, soll uns niemand vertreiben können
-
I could be wrong but that looks like it will do a full scan of the table for each grouping of rows. Why not just do a single pass with the While loop using logic similar to what's in the Quirky Update?
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden wrote:
I could be wrong but that looks like it will do a full scan of the table for each grouping of rows. Why not just do a single pass with the While loop using logic similar to what's in the Quirky Update?
It said "One approach" not the best or only way. The WHERE clause is not sarge-able, I agree. When I switched to what seemingly seemed to be equivalent code the row result was not the same. Not sure why:
qu.ActivationTime>dateadd(day, 5, tc.ActivationTime);
One item which seems important and yet hasn't been established afaik is whether or not the 'ActivationTime' column is a unique key. It seems possible there are duplicate rows and if so self joins seem risky but I'm not sure. My WHILE loop checks to confirm the correct number of rows were updated
Aus dem Paradies, das Cantor uns geschaffen, soll uns niemand vertreiben können
- Ken McKelvey wrote:
In this case I cannot see anyway to predict when missing dates are needed (2017-11-16) or not needed (2017-11-19 & 2017-11-18).
This is a delayed message as I was away from a computer for three days. It occurred to me later that 2017-11-18 and 2017-11-19 are actually a Saturday and Sunday so for the actual published test data the complicated 5 day rule can be replace by iso_week.
SELECT Score, ActivationTime
,DENSE_RANK() OVER
(
ORDER BY YEAR(ActivationTime) * 100 + DATEPART(iso_week, ActivationTime) DESC
) AS Grp
FROM #MyHead
ORDER BY Grp, Score DESC;Of course, it would be easy for additional test data to make this approach wrong.
-
my attempt at this.
Do note that the 5 days interval is partially misleading as to the final result because of the time part.
,(7 ,'2017-11-17 09:38:00.000') --Group 2 starts here
,(7 ,'2017-11-12 09:46:00.000') --Group 3 starts here, but if using the time part on the 5 days rule then this should be on the bottom of group 2
this can be tested easily by changing the cast to date below to be datetime instead
drop table if exists #myhead
SELECT score
, cast(Activationtime as datetime) as ActivationTime
INTO #MyHead
FROM (VALUES
(1 ,'2017-11-24 09:45:00.000') --These should be in Grp #1.
,(3 ,'2017-11-23 09:43:00.000') --The 24th thru the 20th is a 5 day span
,(4 ,'2017-11-22 09:40:00.000')
,(5 ,'2017-11-21 09:39:00.000')
,(12 ,'2017-11-20 09:49:00.000')
,(9 ,'2017-11-20 09:37:00.000')
--<--<< Notice that there are 2 days in this gap.
,(7 ,'2017-11-17 09:38:00.000') --Group 2 starts here, as does a new
,(2 ,'2017-11-15 09:41:00.000') --span start date. Even though there are
,(0 ,'2017-11-14 09:44:00.000') --less than 5 entries, the span goes from
,(15 ,'2017-11-13 09:47:00.000') --the 17 to the 13th, which is 5 days
--<--<< Notice that this actually isn't a gap.
,(7 ,'2017-11-12 09:46:00.000') --Group 3 starts here, as does a new
,(20 ,'2017-11-11 09:42:00.000') --span start date
,(4 ,'2017-11-10 09:28:00.000')
)v(Score,ActivationTime)
;
with tops as
(select *
from (select top 1 ActivationTime
from #MyHead
order by ActivationTime desc
) t
union all
select t2.activationtime
from tops tp1
outer apply (select row_number() over (order by mh1.ActivationTime desc) as rownum
, ActivationTime
from #MyHead mh1
--where cast(mh1.ActivationTime as datetime) <= dateadd(day, -5, cast(tp1.ActivationTime as datetime))
where cast(mh1.ActivationTime as date) <= dateadd(day, -5, cast(tp1.ActivationTime as date))
) t2
where t2.rownum = 1
)
, base as
(select *
, row_number() over (order by tp1.ActivationTime desc) as grp
-- , dateadd(day, -5, tp1.activationtime) as lowdate -- CHANGE to line below
, dateadd(day, -5, convert(date, tp1.activationtime)) as lowdate
from tops tp1
)
select mh.Score
, mh.ActivationTime
, base.grp
from base
inner join #MyHead mh
--on mh.ActivationTime > base.lowdate -- CHANGE to line below
on convert(date, mh.ActivationTime) > base.lowdate
and mh.ActivationTime <= base.ActivationTime
order by base.grp
, mh.ActivationTime desc
, mh.Score
OPTION (MAXRECURSION 0)
Viewing 15 posts - 1 through 15 (of 36 total)
You must be logged in to reply to this topic. Login to reply