Is there a best way to combine data into a single output field
-
I need to create output that takes a list of names and combines them into one field. Here is an example of the output:Name States
Bob Ohio, Iowa, Alaska
Sue Idaho, Iowa
Jane Alaska, Hawaii, Idaho, OhioThe tables are well-formed (see below) and I can brute force a solution but am curious if there is a better, preferred way. I have two questions.
1) Is there a recommended way for creating this sort of output?
2) Is there a name for this sort of process? I can't think of one, which makes it difficult to search for a recommended solution.Thank you for your time and attention,
Rod
--===============================================================
CREATE TABLE #names (
NameID int,
name varchar(4));INSERT INTO #names
VALUES (1, 'Bob'), (2, 'Sue'), (3, 'Jane');----
CREATE TABLE #states (
StateID int,
State varchar(6));INSERT INTO #states
VALUES (1, 'Ohio'), (2, 'Iowa'), (3, 'Hawaii'), (4, 'Alaska'), (5, 'Idaho');----
CREATE TABLE #name_states (
NameID int,
StateID int);INSERT INTO #name_states
VALUES (1, 1), (1, 2), (1, 4), (2, 5), (2, 2), (3, 4), (3, 3), (3, 5), (3, 1); - Rod Harten - Friday, April 28, 2017 6:38 PM
I think this will give you what you're looking for.
WITH cteData AS (
SELECT n.Name, s.State
FROM #names n
INNER JOIN #name_states ns ON ns.NameID = n.NameID
INNER JOIN #states s ON ns.StateID = s.StateID
),
cteNames AS (
SELECT DISTINCT Name
FROM #names
)
SELECT Name,
StatesList = STUFF((SELECT ',' + d.State
FROM cteData d
WHERE d.Name = cteNames.Name
ORDER BY d.State
FOR XML PATH(''), TYPE).value('.', 'varchar(max)'), 1, 1, '')
FROM cteNames
ORDER BY Name;There are many approaches to creating a delimited list, but Wayne Sheffield's article at http://www.sqlservercentral.com/articles/comma+separated+list/71700/ is the approach I prefer. This is the technique above.
Edit: Please forgive the indenting of the code, but I still haven't gotten the knack of the new SQL editor on SSC. I tried to get it close.
-
Thank you very much!
That works great and is a much better solution than anything I was considering.
Thanks also for the link to the article and giving a name, comma separated list, to what I an trying to create,
Rod
- Rod Harten - Sunday, April 30, 2017 5:32 PM
I'm glad it worked well for you. Thanks for your feedback.
- Rod Harten - Friday, April 28, 2017 6:38 PM
There's so much fundamentally wrong here. You might want to look up what the term "field" means in SQL. You also might want to look at what a column is; a column has to be scaler not a list. By definition. Then you might want to look at what a table is; what you posted has no keys. In fact, what you posted can never have a key, because all the columns are NULL-able.
On top of all of this, identifiers are never numerics because you don't do any computations with them (this is usually covered in the first week of any good data modeling course); what would the square root of your credit card number mean?
The model in modern computing is a tiered architecture. Data is scrubbed in an input layer, past into the database layer, and then queried from it so it can be passed to a presentation layer. What you're trying to do is best done in a presentation layer, not in SQL. The way to do this is by getting out of SQL completely and doing a kludge with XML or passing it on to report writer of some kind.
Please post DDL and follow ANSI/ISO standards when asking for help.
- jcelko212 32090 - Monday, May 1, 2017 8:22 AM
There's no need to go completely OCD and berate the OP on what terms they used. I looked at what the OP was trying to do. After all, this site is supposed to be about helping others.
Oh, an identifiers can be numeric. Using an integer identity column as an artificial key has many benefits that are well beyond the scope of this post. It may or not be ISO-compliant, but it doesn't matter because this is a SQL Server forum, not an ISO standards forum. There's no question that you know the ISO standards, but many people don't consider them a religion.
- Ed Wagner - Monday, May 1, 2017 9:38 AM
Please post DDL and follow ANSI/ISO standards when asking for help.
- Joe, really getting tired of the your bullying on here. If you want to help, try providing something constructive and helpful instead of constantly telling everyone how wrong they are and how right you are.
I say that having seen some of the code you posted in the past that DIDN'T work when cut/paste/executed in SSMS, and when called on it you ignored it.
I will say it again, you have a vast wealth of knowledge that you could share but you don't seem willing to really share it except in your books, that I refuse to purchase because of your online persona.
-
Because the only text that you are dealing with is alphanumeric, you can change
FOR XML PATH(''), TYPE).value('.', 'varchar(max)'), 1, 1, '')
toFOR XML PATH('')), 1, 1, '')
As Wayne talks about in the article Ed posted, the TYPE and value constructs are used to deal with any XML characters (e.g. <>&). They also, however, slow the query down which is why you only include that code when necessary. The optimized code would look like this:WITH
cteData AS
(
SELECT n.Name, s.State
FROM #names n
INNER JOIN #name_states ns ON ns.NameID = n.NameID
INNER JOIN #states s ON ns.StateID = s.StateID
),
cteNames AS (SELECT DISTINCT Name FROM #names)
SELECT
Name,
StatesList = STUFF((SELECT ',' + d.State
FROM cteData d
WHERE d.Name = cteNames.Name
ORDER BY d.State
FOR XML PATH('')), 1, 1, '')
FROM cteNames;
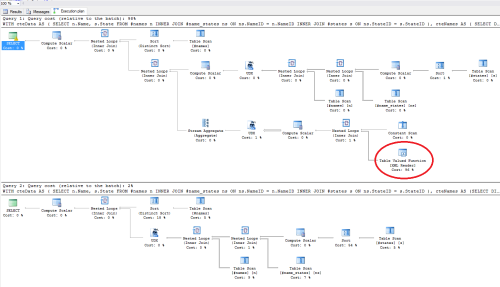
This looks like a small change but if you look at the execution plans, the impact is pretty big. Note excluding the TYPE & value clauses removes the calls to the XML Reader TVF in the plan which slows things down.
Lastly - there is a STRING_AGG function available in 2017 & Azure SQL which is far superior to the FOR XML PATH method.
"I cant stress enough the importance of switching from a sequential files mindset to set-based thinking. After you make the switch, you can spend your time tuning and optimizing your queries instead of maintaining lengthy, poor-performing code."-- Itzik Ben-Gan 2001
- Lynn Pettis - Monday, May 1, 2017 3:41 PM
Same here, Lynn.
Joe, I mean this constructively. The angry, pedantic monologues just turn people off. You're punishing people for nothing. When people are berated and receive no actual help, they go away. Worse yet, what's posted doesn't work and people who don't know any better will end up with bad design. If your goal is to be a troll, you've succeeded. If you're trying to be helpful, you might want to try a different approach.
-
Alan, I found the same thing. When I tested them against one another (with de-entitization versus without) I found an average of 78.3% reduction in execution time. I included it for safety, but I should have noted it. Thanks for picking up on it.
Also, thank you for the tip about the STRING_AGG function. I will be sure to check that one out.
Viewing 11 posts - 1 through 11 (of 11 total)
You must be logged in to reply to this topic. Login to reply